明示的な情報伝達によるコンテキスト圧縮
大規模言語モデル(LLM)の長文処理における計算コストとメモリ消費を削減するため、情報を連続的なベクトル表現に凝縮するソフト圧縮手法「ComprExIT」が提案されました。 既存手法はLLM自体を圧縮器として再利用しますが、層を重ねるごとの情報の上書きや、トークン間での圧縮容量の不均等な割り当てという構造的な欠陥により、情報の欠落や精度の低下を招いていました。 本手法は、固定されたLLMの内部状態から「層方向」と「幅方向」に明示的に情報を伝達することで、わずか1%の追加パラメータで非圧縮モデルに匹敵する精度と、従来手法を凌駕する堅牢性を実現しました。
TL;DR(結論)
大規模言語モデル(LLM)の長文処理における計算コストとメモリ消費を削減するため、情報を連続的なベクトル表現に凝縮するソフト圧縮手法「ComprExIT」が提案されました。 既存手法はLLM自体を圧縮器として再利用しますが、層を重ねるごとの情報の上書きや、トークン間での圧縮容量の不均等な割り当てという構造的な欠陥により、情報の欠落や精度の低下を招いていました。 本手法は、固定されたLLMの内部状態から「層方向」と「幅方向」に明示的に情報を伝達することで、わずか1%の追加パラメータで非圧縮モデルに匹敵する精度と、従来手法を凌駕する堅牢性を実現しました。
なぜこの問題か
大規模言語モデル(LLM)が進化し、扱うコンテキストが長大化するにつれて、推論時の計算コストとメモリ消費が深刻なボトルネックとなっています。特に、アテンション機構の計算量が入力長の二乗に比例することや、キー・バリュー(KV)キャッシュの増大が、実用的なデプロイを困難にする大きな要因です。この課題に対し、入力を短く凝縮する「コンテキスト圧縮」が有効な解決策として注目されています。コンテキスト圧縮には、重要度の低いトークンを削除する「ハード圧縮」と、情報を連続的なベクトル表現に集約する「ソフト圧縮」の二種類が存在します。ハード圧縮は効率的ですが、高い圧縮率では情報の損失が避けられません。一方、ソフト圧縮はより高い表現力を持ちますが、既存の多くの手法には「LLMを圧縮器として再利用する(LLM-as-a-compressor)」という設計に起因する二つの構造的な弱点がありました。 第一の弱点は、層ごとの表現の上書き(Representation Overwriting)です。既存手法では、圧縮用の特殊トークン(gistトークンなど)をLLMの各層で繰り返し更新し、情報を吸収させます。…
核心:何を提案したのか
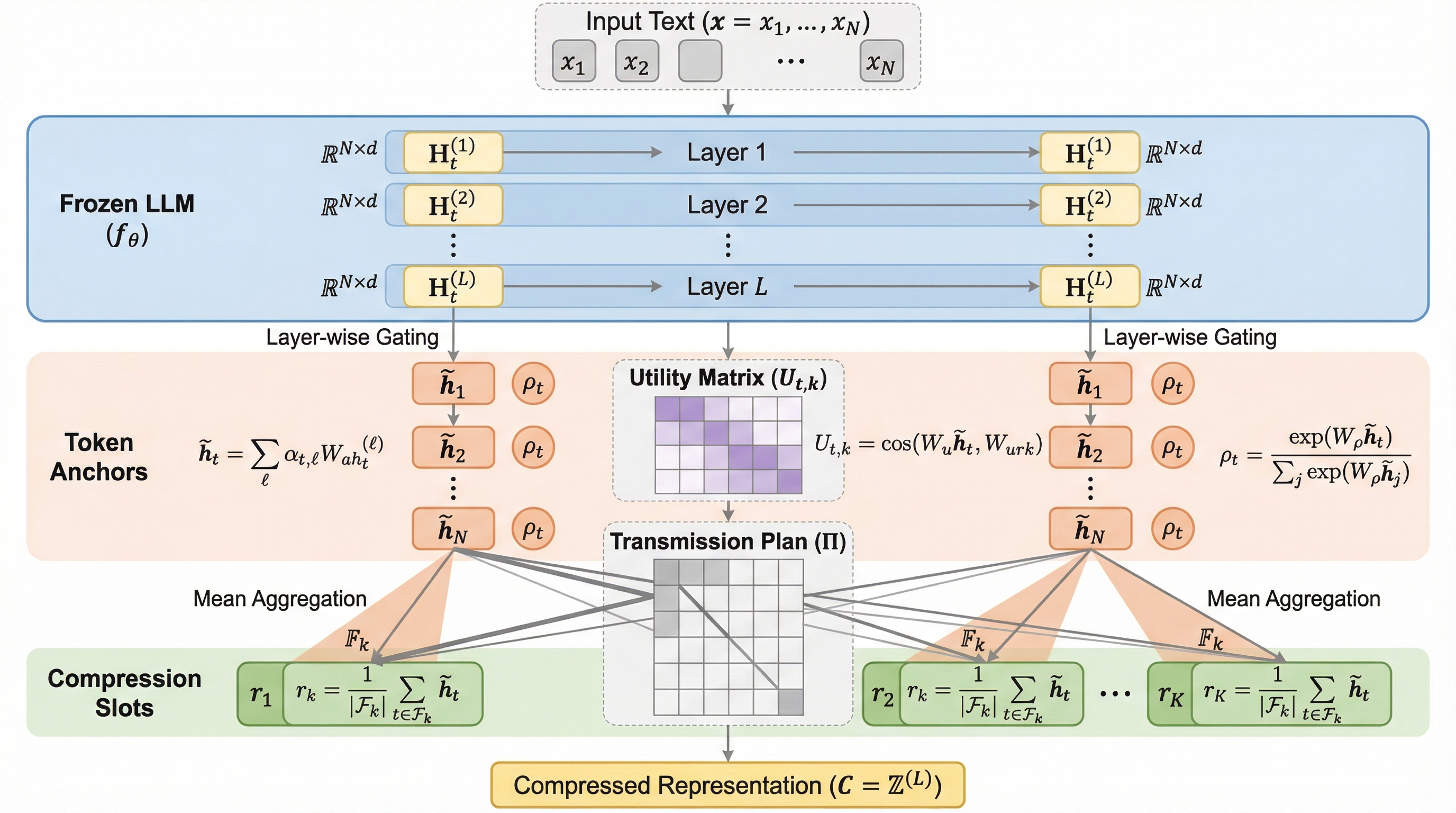
本論文では、従来の「LLM自体を学習可能な圧縮器として使う」というパラダイムを脱却し、固定されたLLMの隠れ状態に対して「明示的な情報伝達(Explicit Information Transmission)」を行う新しいフレームワーク「ComprExIT」を提案しています。この手法の核心は、圧縮プロセスをLLM内部の自己アテンションの動態から完全に切り離し、情報の流れを直接的かつ制御可能な形で設計した点にあります。ComprExITは、LLMの重みを凍結(frozen)した状態で、その内部で生成される多層的な隠れ状態を直接利用します。LLMの各層には、低レベルの語彙的特徴から高レベルのセマンティックな抽象概念まで、多様な情報が含まれているという特性を最大限に活用しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related