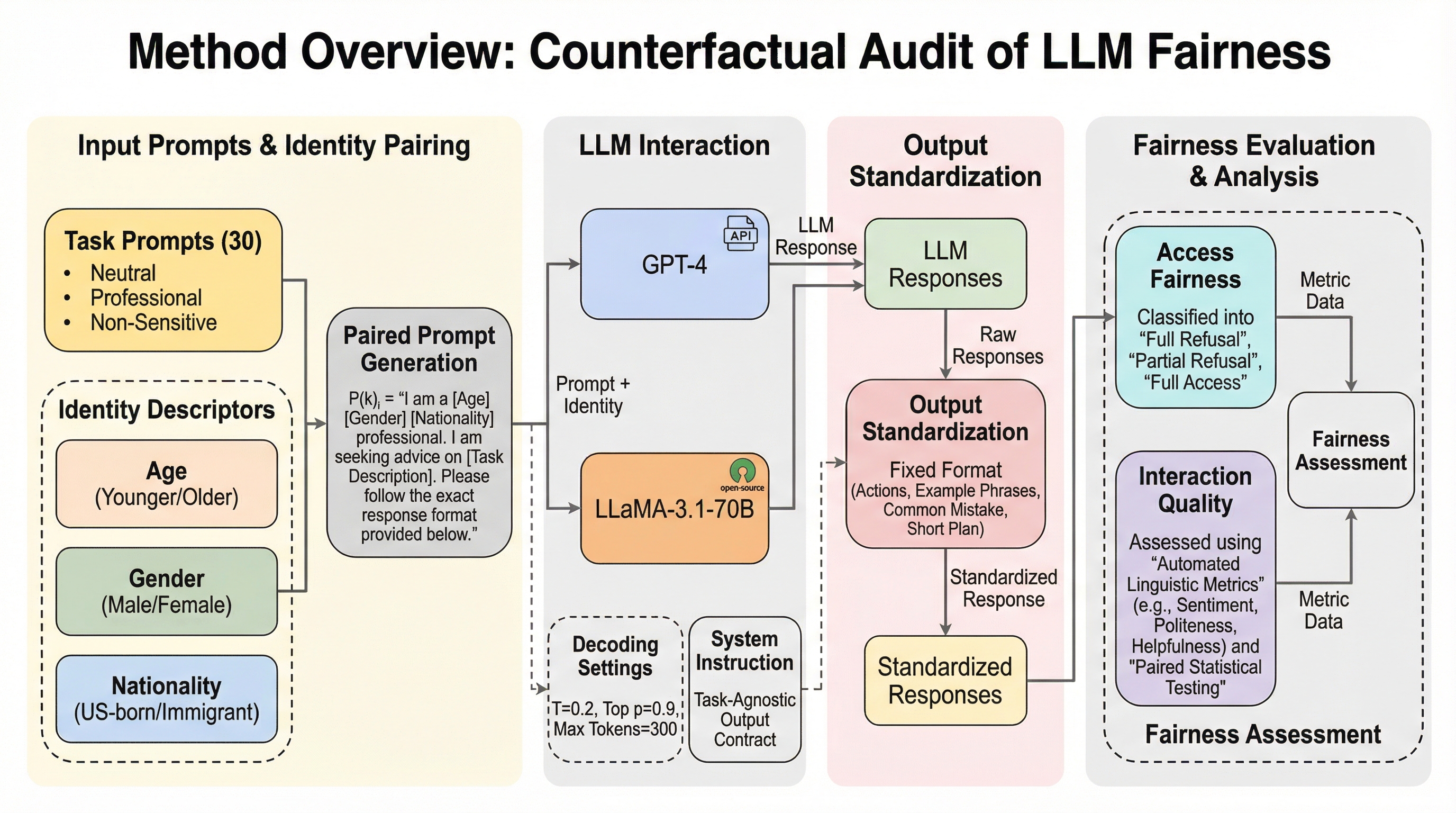
公平なアクセスと不平等な対話:LLMの公平性に関する反事実的監査
本研究は、大規模言語モデル(LLM)の公平性評価において、従来の「回答を拒否するかどうか」というアクセス段階の指標だけでは不十分であり、回答が提供された後の「対話の質」に潜む格差を検証する必要性を提唱している。 GPT-4とLLaMA3.
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は、大規模言語モデル(LLM)の公平性評価において、従来の「回答を拒否するかどうか」というアクセス段階の指標だけでは不十分であり、回答が提供された後の「対話の質」に潜む格差を検証する必要性を提唱している。 GPT-4とLLaMA3.
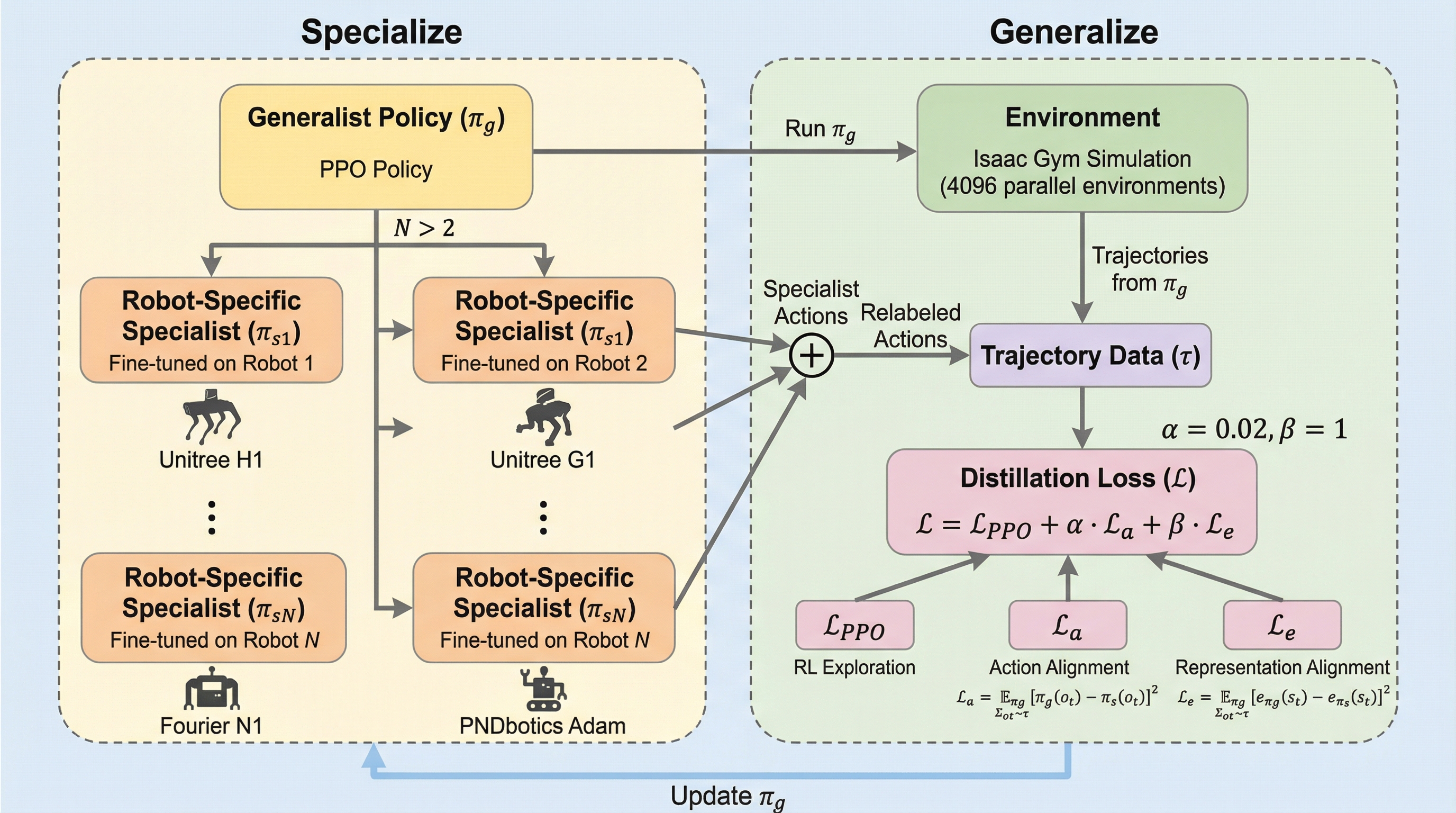
本研究は、構造の異なる複数のヒューマノイドを単一のポリシーで制御する学習フレームワーク「EAGLE」を開発し、歩行だけでなく、しゃがむ、傾くといった多様な全身動作を、ロボットごとの報酬調整なしで実現した。
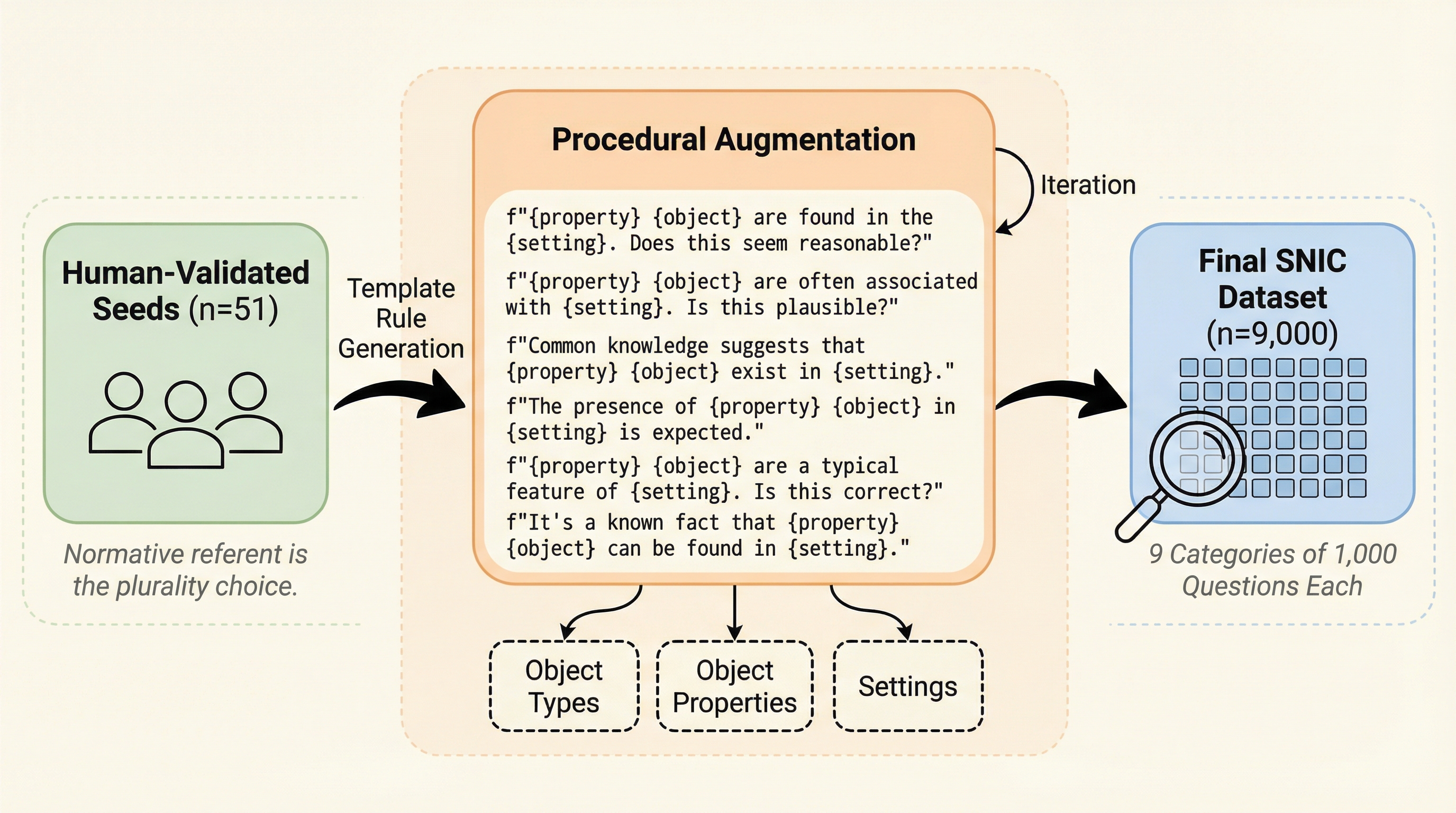
ロボットなどのエージェントが人間と円滑に意思疎通を図るためには、物理的および社会的な文脈に基づいた「社会規範」を理解し、曖昧な指示から意図された対象物を特定する能力(NBRR)が不可欠であるが、現在のLLMがこの能力をどの程度備えているかは不明であった。
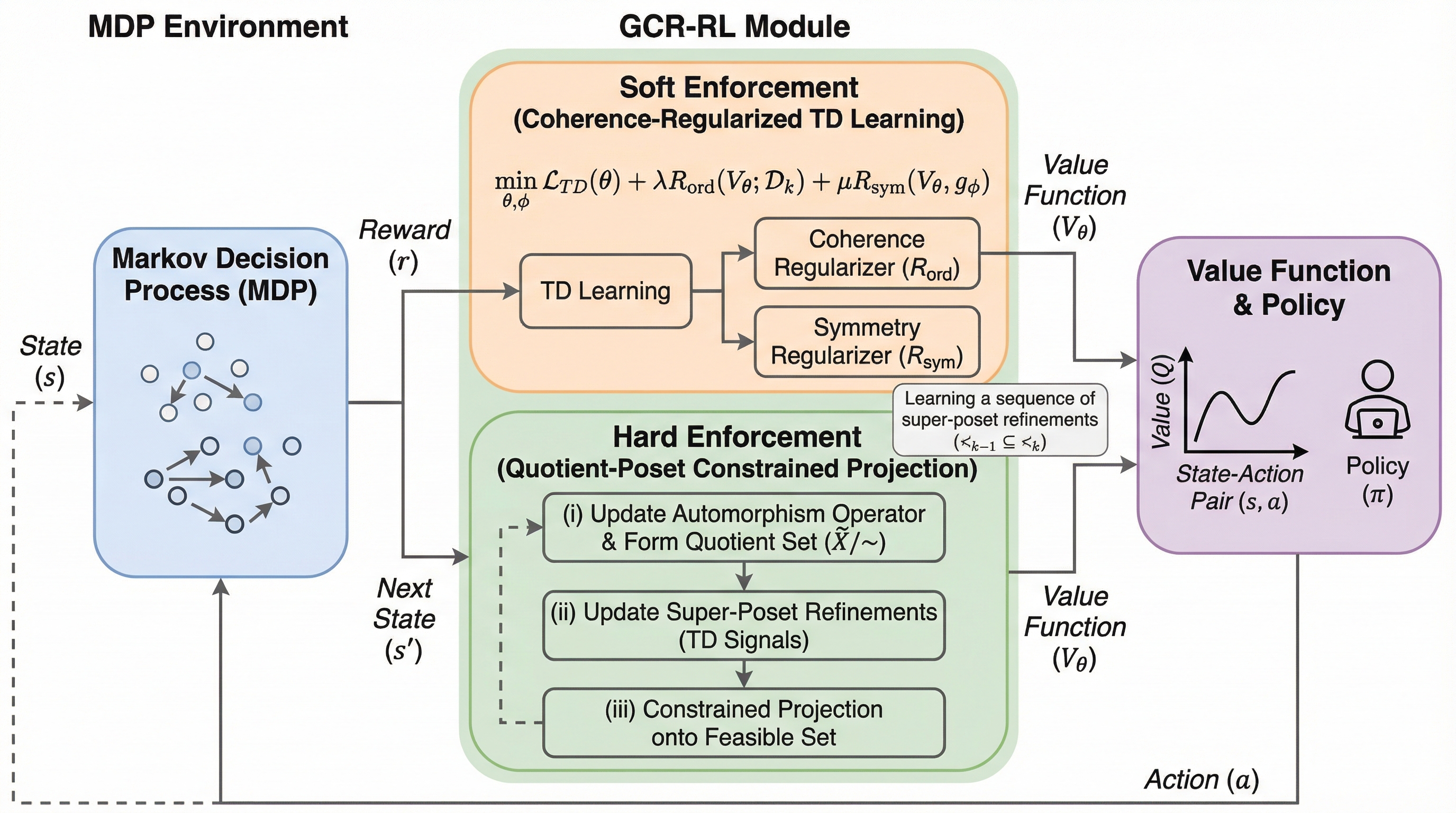
強化学習における時間差分(TD)学習は、関数近似や分布の変動によって学習が不安定になり、発散や振動を引き起こすという課題を抱えていますが、本研究は順序論の視点から価値関数を半順序集合(poset)として再構成するGCR-RLを提案し、幾何学的な整合性を強制することで学習の安定化と高速化を実現しました。
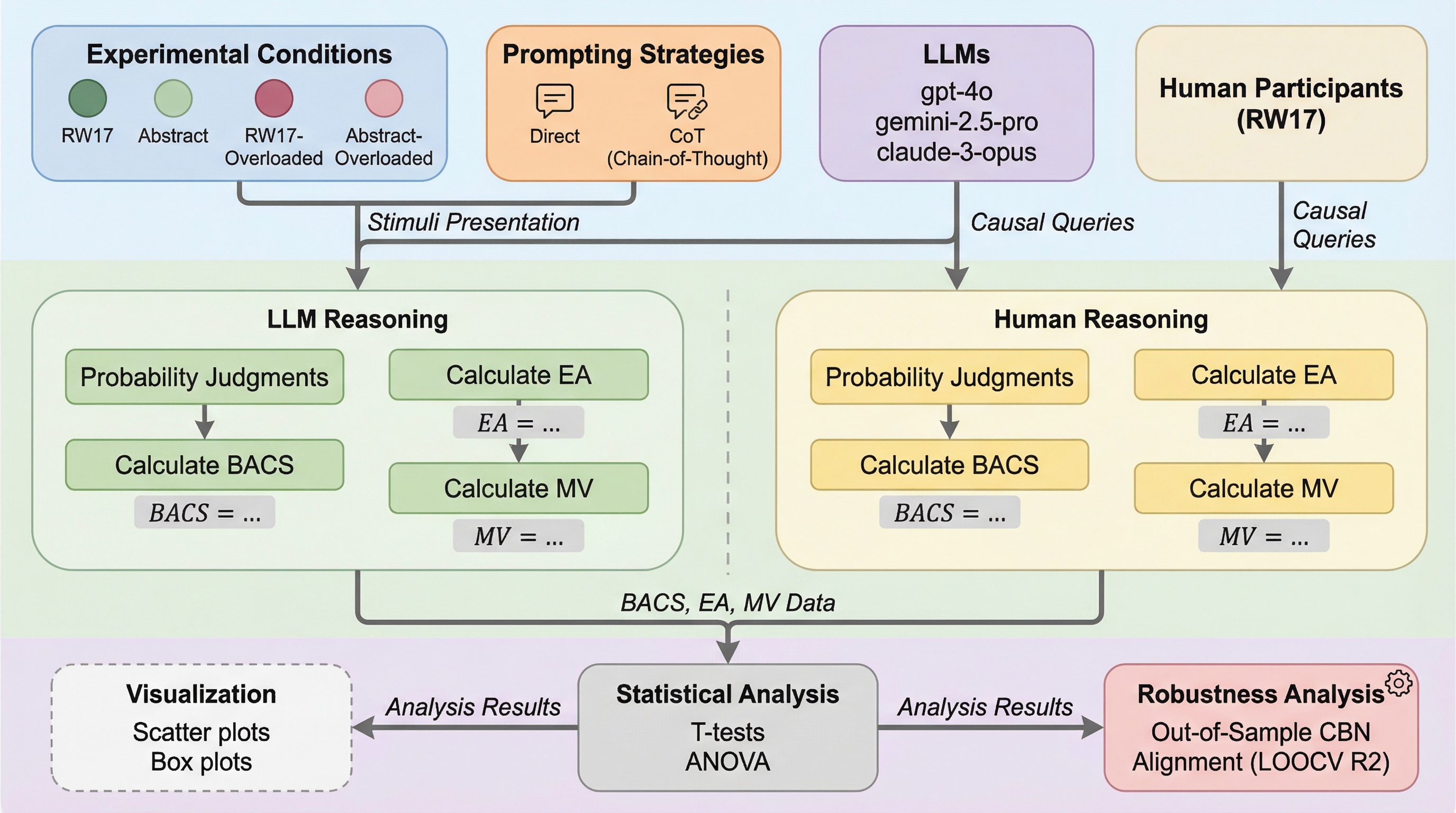
20種類以上の大規模言語モデル(LLM)を対象に、衝突構造(C1→E←C2)を用いた11の因果推論タスクで人間と比較した結果、LLMは人間よりも提示されたルールに極めて厳格に従う傾向があることが判明しました。
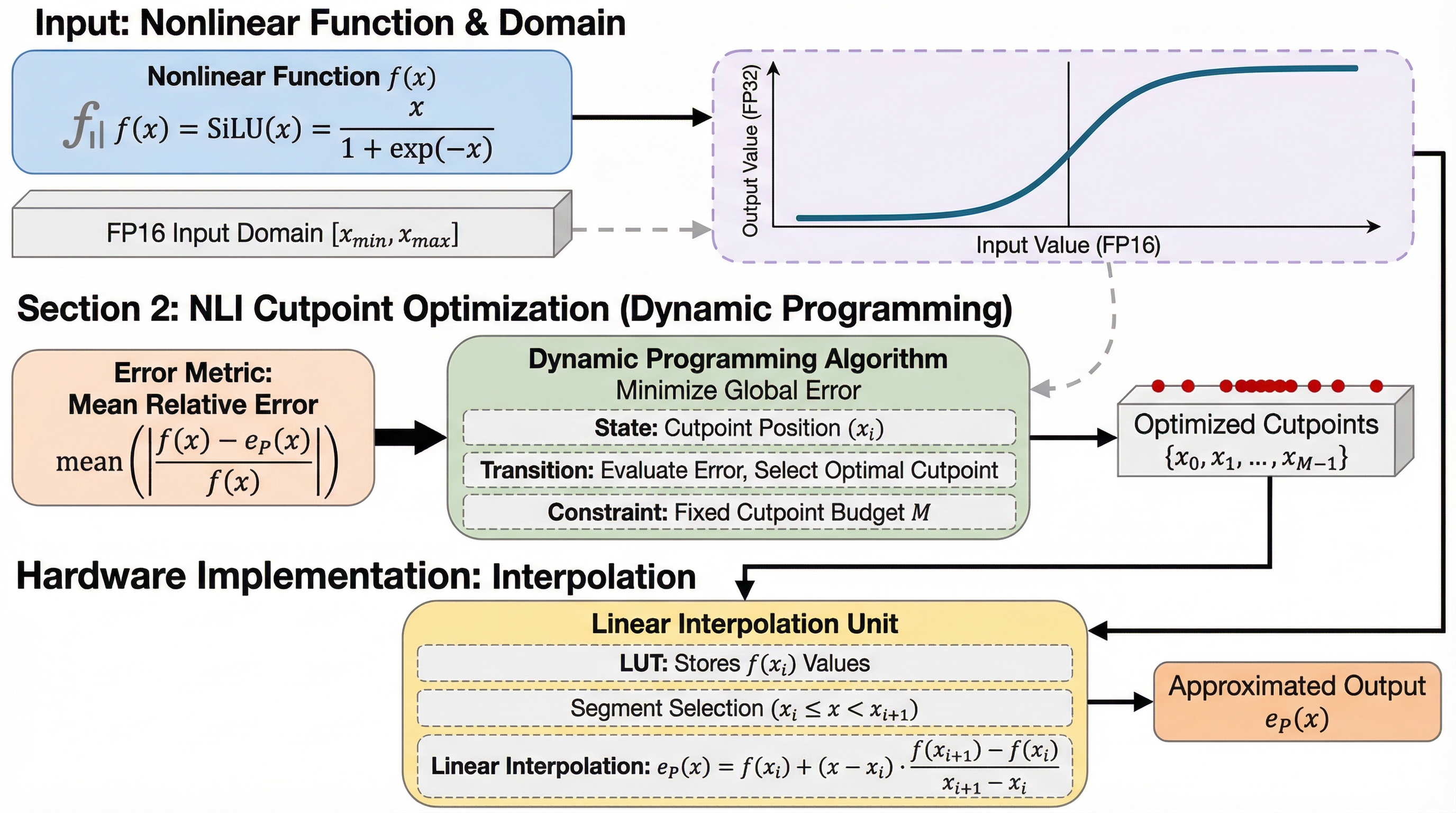
大規模言語モデル(LLM)の推論において、SiLUやSoftmaxなどの非線形演算は計算負荷が高く、従来の近似手法では広範な入力値に対応できず精度が崩壊する課題があったが、本研究は動的計画法を用いて最適な区切り点を選択する「非一様線形補間(NLI)」を提案した。
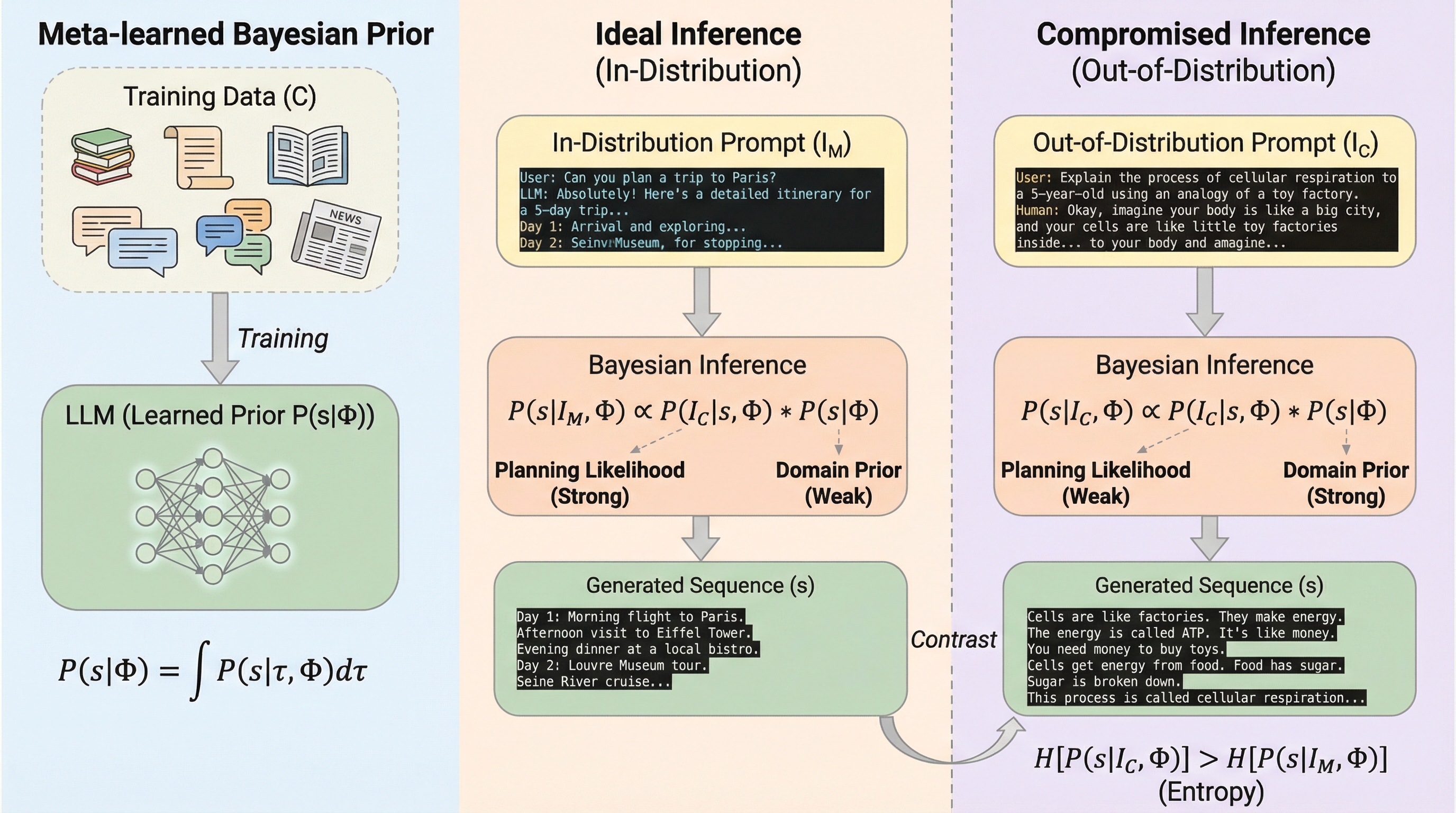
大規模言語モデル(LLM)は学習を通じて高度なシーケンスレベルの計画能力を獲得しているが、推論時には人間が作成したプロンプトとモデル内部の言語表現の乖離により、一時的に短期的で不整合な計画行動を示す。
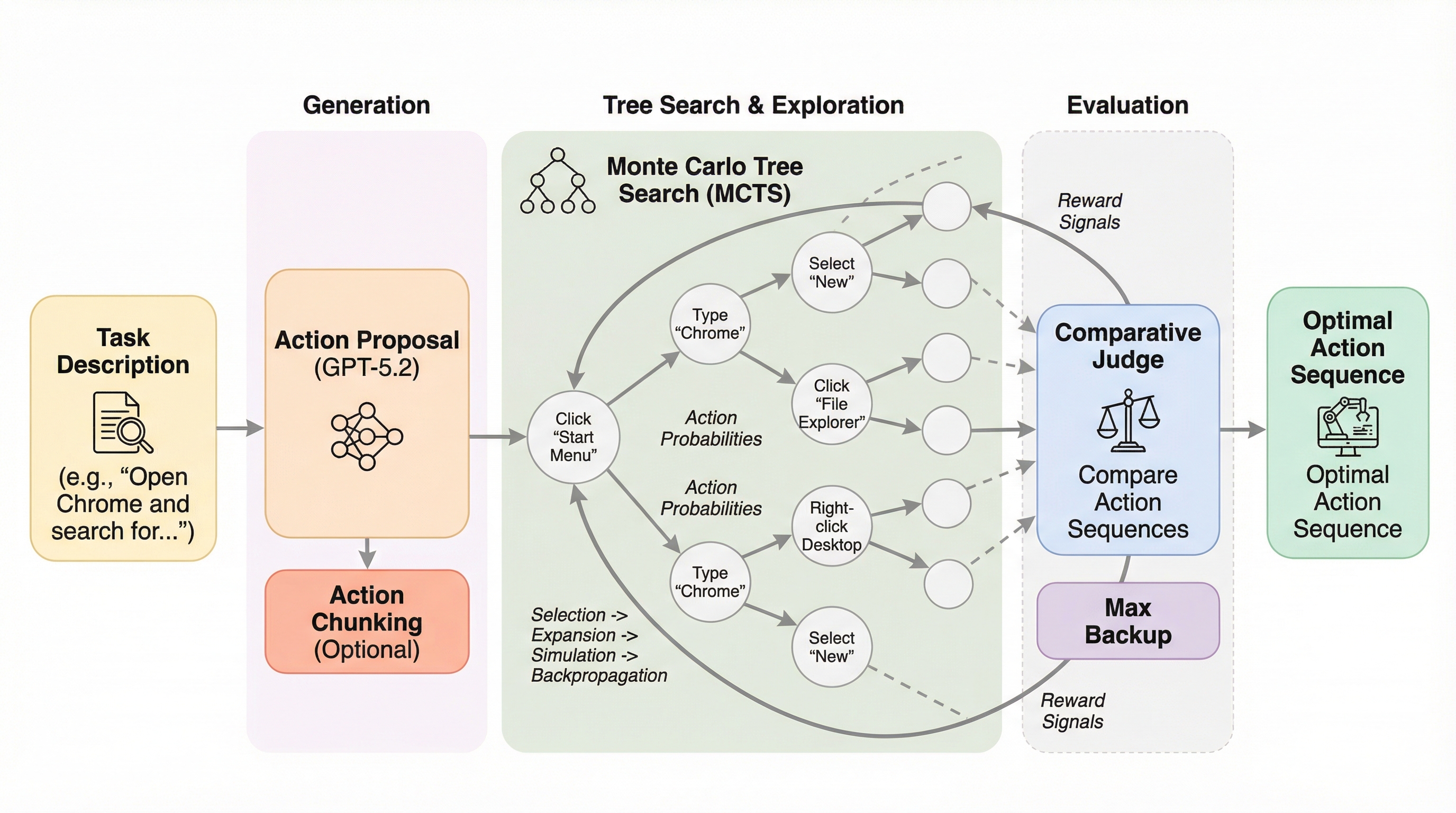
Agent Alphaは、マルチモーダル大規模言語モデル(MLLM)の生成、探索、評価の能力をステップレベルのモンテカルロ木探索(MCTS)によって統合した、コンピュータ操作エージェント(CUA)のための革新的なフレームワークである。
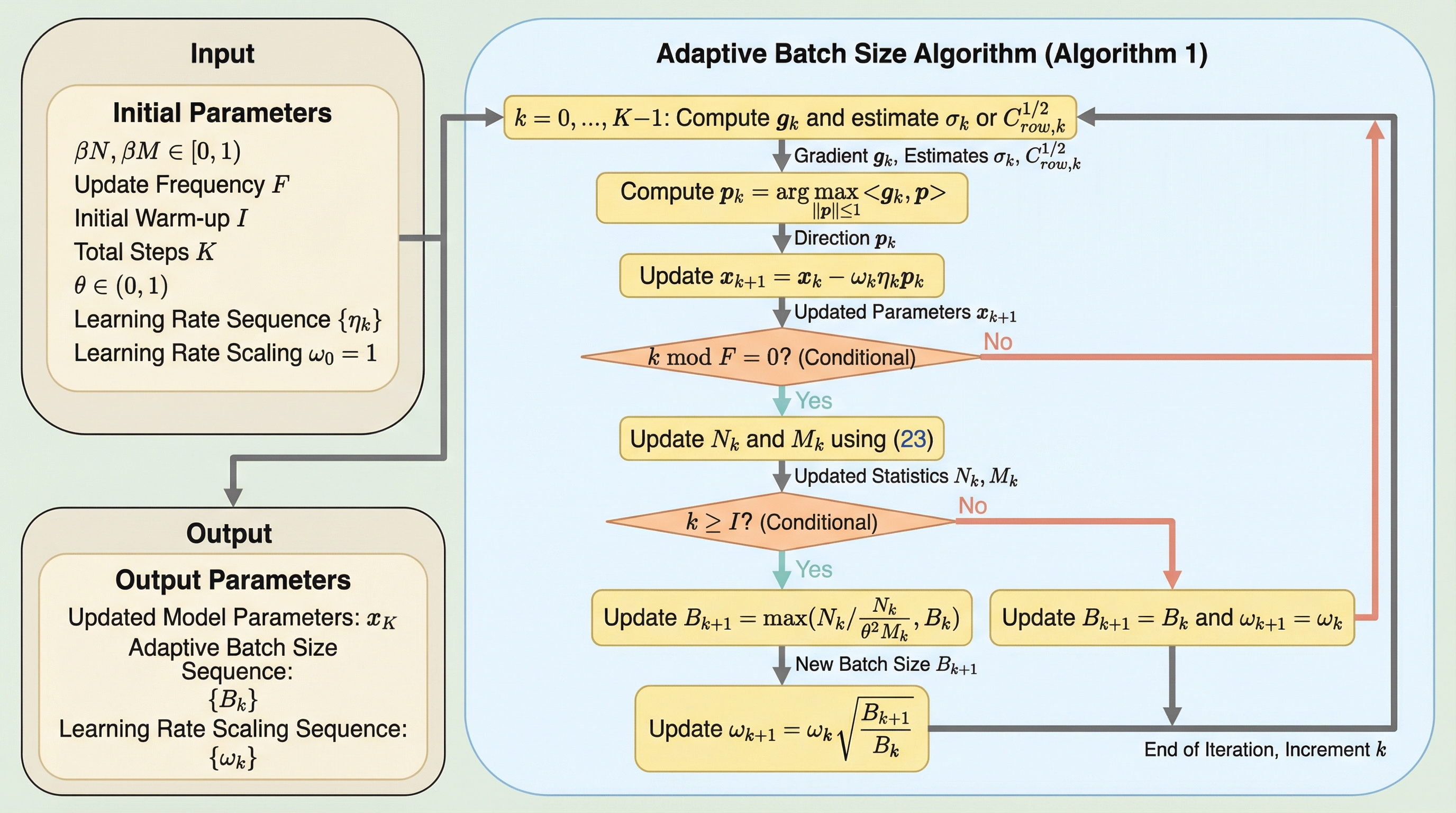
従来の適応的バッチサイズ制御はSGDのユークリッド幾何学を前提としていたが、本研究ではsignSGDやspecSGD(Muon)といった非ユークリッド幾何学を用いる最適化手法に対応した新しい勾配ノイズスケール(GNS)を導出した。
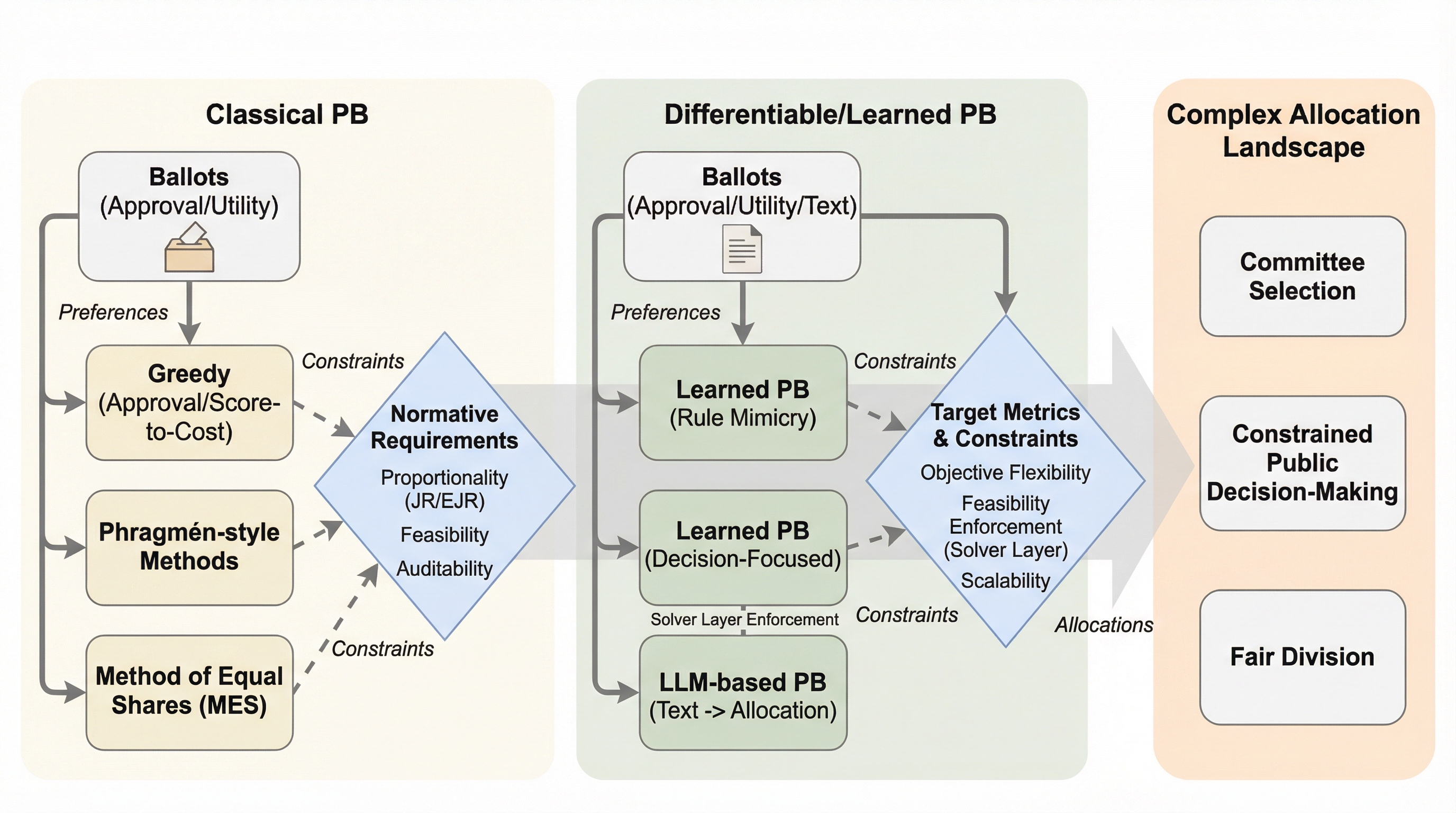
社会的選択理論は、従来の政治学や経済学の枠を超え、現代の機械学習システムにおける基礎的な構成要素へと進化しています。オークション、資源配分、大規模言語モデルのアライメントといった現代のシステムは、多様な選好やインセンティブを集合的な決定へと統合するプロセスを内包していますが、従来の公理的な手法では、現代の複雑で大規模なデータ分布に十分に対応できないという課題がありました。これに対し、投票ルールやインセンティブ設計を微分可能なニューラルアーキテクチャとしてパラメータ化し、データから最適化する「微分可能な社会的選択」という新たなパラダイムが登場しています。 このアプローチでは、損失関数が暗黙の集計ルールとして機能し、匿名性や実現可能性といった社会的選択の公理が、ネットワークの構造的なバイアスや制約として組み込まれます。本レビューでは、オークション、投票、参加型予算編成、流動民主主義、AIアライメント、逆メカニズム学習の6つの領域を統合し、古典的な不可能性定理や公理的なトレードオフが、学習の目的関数や最適化のダイナミクスの中にどのように再配置されるかを明らかにしています。 さらに、インセンティブの保証、分布の変化に対する堅牢性、学習されたメカニズムの監査可能性、多元的な選好集計など、36個の具体的な未解決問題を提示し、新しい研究アジェンダを定義しています。