Agent Alpha: コンピュータ操作エージェントのための生成・探索・評価を統合する木探索
Agent Alphaは、マルチモーダル大規模言語モデル(MLLM)の生成、探索、評価の能力をステップレベルのモンテカルロ木探索(MCTS)によって統合した、コンピュータ操作エージェント(CUA)のための革新的なフレームワークである。
TL;DR(結論)
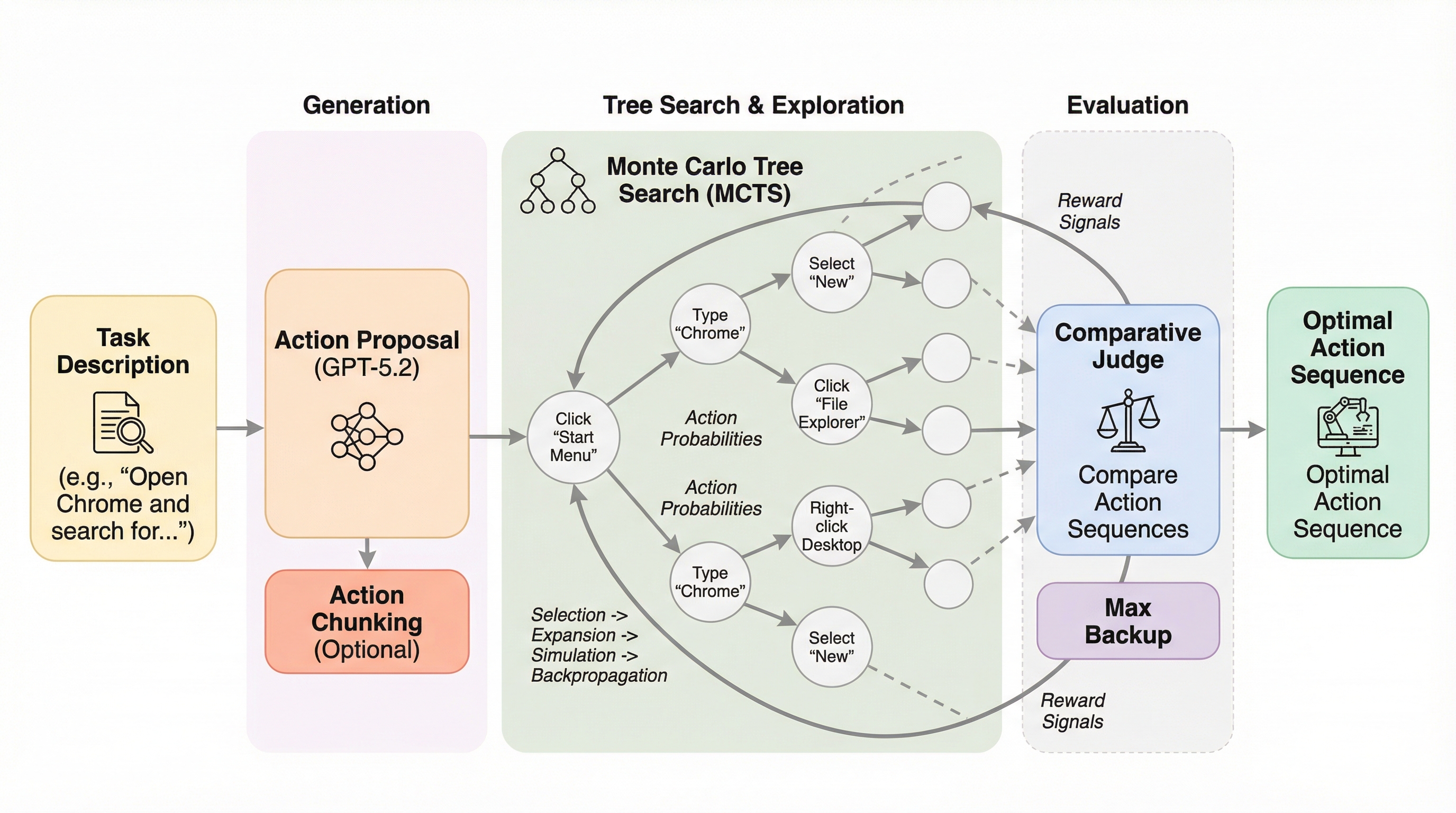
Agent Alphaは、マルチモーダル大規模言語モデル(MLLM)の生成、探索、評価の能力をステップレベルのモンテカルロ木探索(MCTS)によって統合した、コンピュータ操作エージェント(CUA)のための革新的なフレームワークである。 従来のChain of ThoughtsやBehavior Best of Nといった手法が抱えていた、一方向の処理に限定され初期の誤操作から回復できないという構造的な課題を、回帰的な計画立案とAlpha-UCT境界を用いた効率的な枝刈りによって根本から解決している。 OSWorldベンチマークにおいて、Agent Alphaは約77%という過去最高の成功率を達成し、同等の計算資源を用いた従来の軌道レベルのスケーリング手法を大幅に上回るスケーリング効率と、複雑なタスクにおける極めて高い適応能力を実証した。
なぜこの問題か
近年、マルチモーダル大規模言語モデル(MLLM)を基盤としたコンピュータ操作エージェント(CUA)の研究が急速に進展しており、推論能力を向上させるための様々な手法が提案されている。しかし、既存のChain of Thoughts(CoT)やTree of Thoughts(ToT)、あるいは軌道レベルでのサンプリングを行うBehavior Best of N(bBoN)といったテストタイムのスケーリング手法には、複雑で動的な環境において共通の限界が存在する。これらの手法は主に一方向のプロセスとして動作するため、計画空間の構造をモデル化したり活用したりする能力が欠如しており、過去の行動を遡って評価し直すことができない。特に、グラフィカルユーザーインターフェース(GUI)の操作においては、初期段階でのわずかな誤操作がその後のプロセス全体に致命的な影響を及ぼし、取り返しのつかない失敗へとつながることが非常に多い。現在の手法では、一度選択された不適切な分岐から回復するメカニズムや、有望な行動の接頭辞を再利用して探索を効率化する仕組みが整っていないため、最適な解に収束するまでの探索効率が著しく低いという問題がある。…
核心:何を提案したのか
本論文では、MLLMの生成、探索、評価の能力をステップレベルのモンテカルロ木探索(MCTS)を通じて相乗的に統合する「Agent Alpha」という統一フレームワークを提案している。Agent Alphaは、従来の線形な実行プロセスを回帰的な計画プロセスへと変換することで、あらゆる環境との相互作用の有用性を最大化し、蓄積された評価情報を活用して初期の誤りや複合的なエラーから自律的に回復することを可能にする。このフレームワークの核心は、Alpha-UCT境界によって導かれる探索を相互作用ループに組み込むことで、きめ細かな探索を実現し、有望な行動シーケンスの再利用や停滞したプロセスの早期打ち切りを促進する点にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related