LLMの因果推論におけるバイアスと人間との比較分析
20種類以上の大規模言語モデル(LLM)を対象に、衝突構造(C1→E←C2)を用いた11の因果推論タスクで人間と比較した結果、LLMは人間よりも提示されたルールに極めて厳格に従う傾向があることが判明しました。
TL;DR(結論)
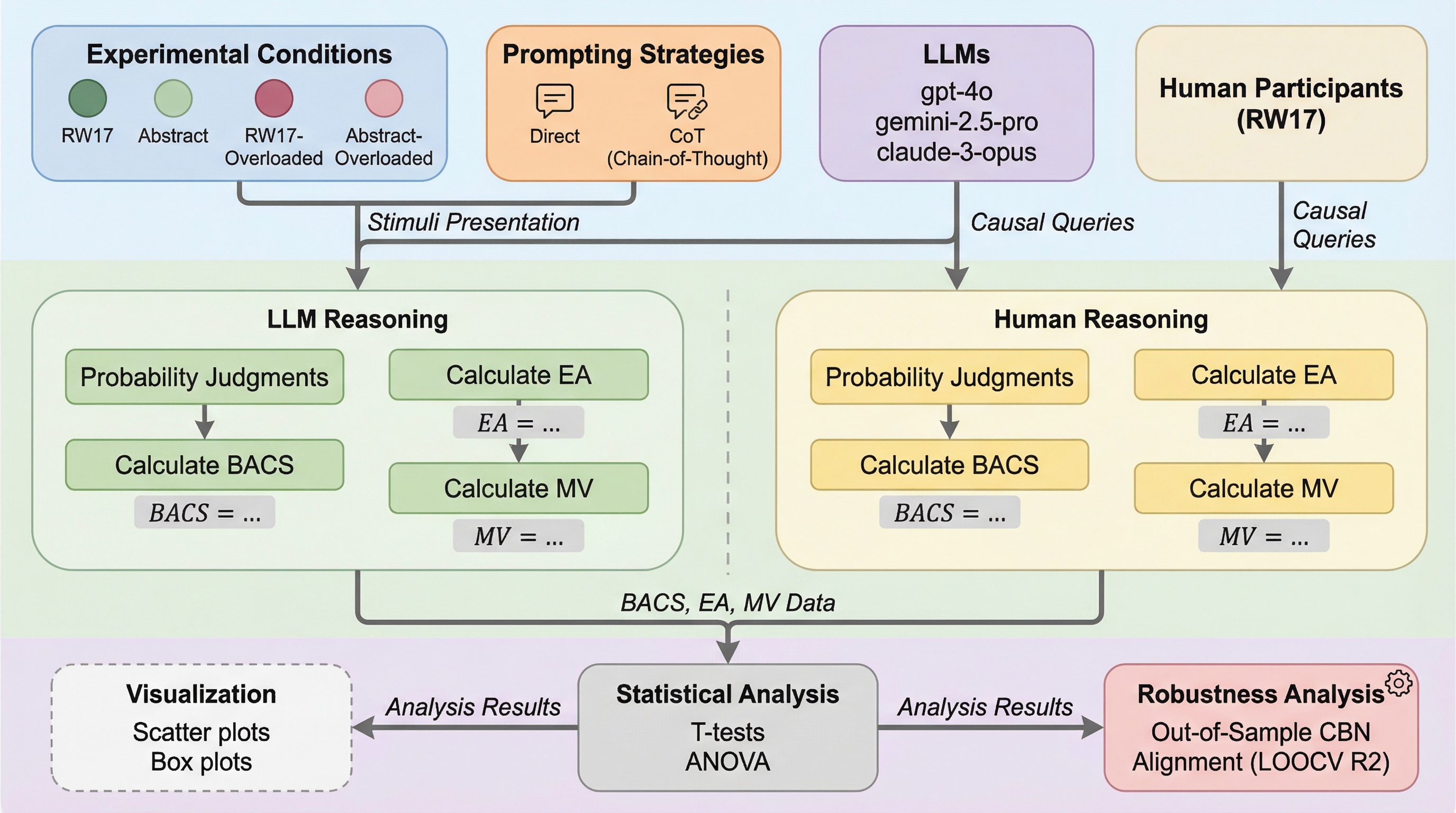
20種類以上の大規模言語モデル(LLM)を対象に、衝突構造(C1→E←C2)を用いた11の因果推論タスクで人間と比較した結果、LLMは人間よりも提示されたルールに極めて厳格に従う傾向があることが判明しました。 人間は言及されていない潜在的な要因を考慮して確率を判断しますが、多くのLLMは提示された因果関係のみに依存し、人間特有の「説明の排除」の弱さや「マルコフ性の違反」といったバイアスをほとんど再現しないことが示されています。 思考の連鎖(CoT)を用いることで、無関係な情報の注入や抽象的な表現に対しても推論の堅牢性が向上し、小規模で解釈可能な因果ベイズネットワークモデルによってLLMの判断を高い精度で説明・予測できることが明らかになりました。
なぜこの問題か
人間による因果判断は非常に強力である一方で、注意力の限界や疲労、文脈のフレーミングによって規範的な推論から逸脱しやすいという脆弱性を抱えています。このような背景から、法的判断や医療診断支援といった高いリスクを伴う意思決定の場において、一貫した因果分析を提供できるAIによる支援が期待されています。特に大規模言語モデル(LLM)が因果関係の理解を必要とする領域で急速に導入されている現状では、モデルが単なるパターンマッチングや連想的な推論によって出力を生成しているのか、それとも新しい文脈にも適用可能な因果推論戦略を適用しているのかを明らかにすることが極めて重要です。現実世界の因果判断の設定は、多くの場合において不完全であり、正確なベースレート(基準率)などが不明な「定義が不十分な」状態にあります。このような状況下で、人間はヒューリスティック(直感的な手法)や事前の仮定に頼るため、特有のバイアスが生じます。…
核心:何を提案したのか
本研究では、20種類以上の主要なLLMを対象に、人間を基準としたベースラインと比較を行うための包括的な因果推論ベンチマークを提案しました。このベンチマークは、ニューヨーク大学の学生48名を対象とした先行研究(Rehder & Waldmann, 2017)の実験に基づいています。具体的には、2つの原因(C1、C2)が1つの結果(E)をもたらす「衝突構造(collider structure)」と呼ばれる因果グラフを用いて、11種類の異なる条件付き確率の問いに対するモデルの回答を評価しました。評価の核心は、単に正解を求めることではなく、モデルがどのような推論戦略を採用しているかを「解釈可能な小規模モデル」を用いて圧縮・説明することにあります。具体的には、因果ベイズネットワーク(CBN)という数学的モデルをLLMの回答に適合させ、その一貫性を測定しました。また、推論の堅牢性を検証するために、以下の3つの側面から実験を行いました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related