大規模言語モデルは推論時の計画において誤った第一歩を踏み出す可能性がある
大規模言語モデル(LLM)は学習を通じて高度なシーケンスレベルの計画能力を獲得しているが、推論時には人間が作成したプロンプトとモデル内部の言語表現の乖離により、一時的に短期的で不整合な計画行動を示す。
TL;DR(結論)
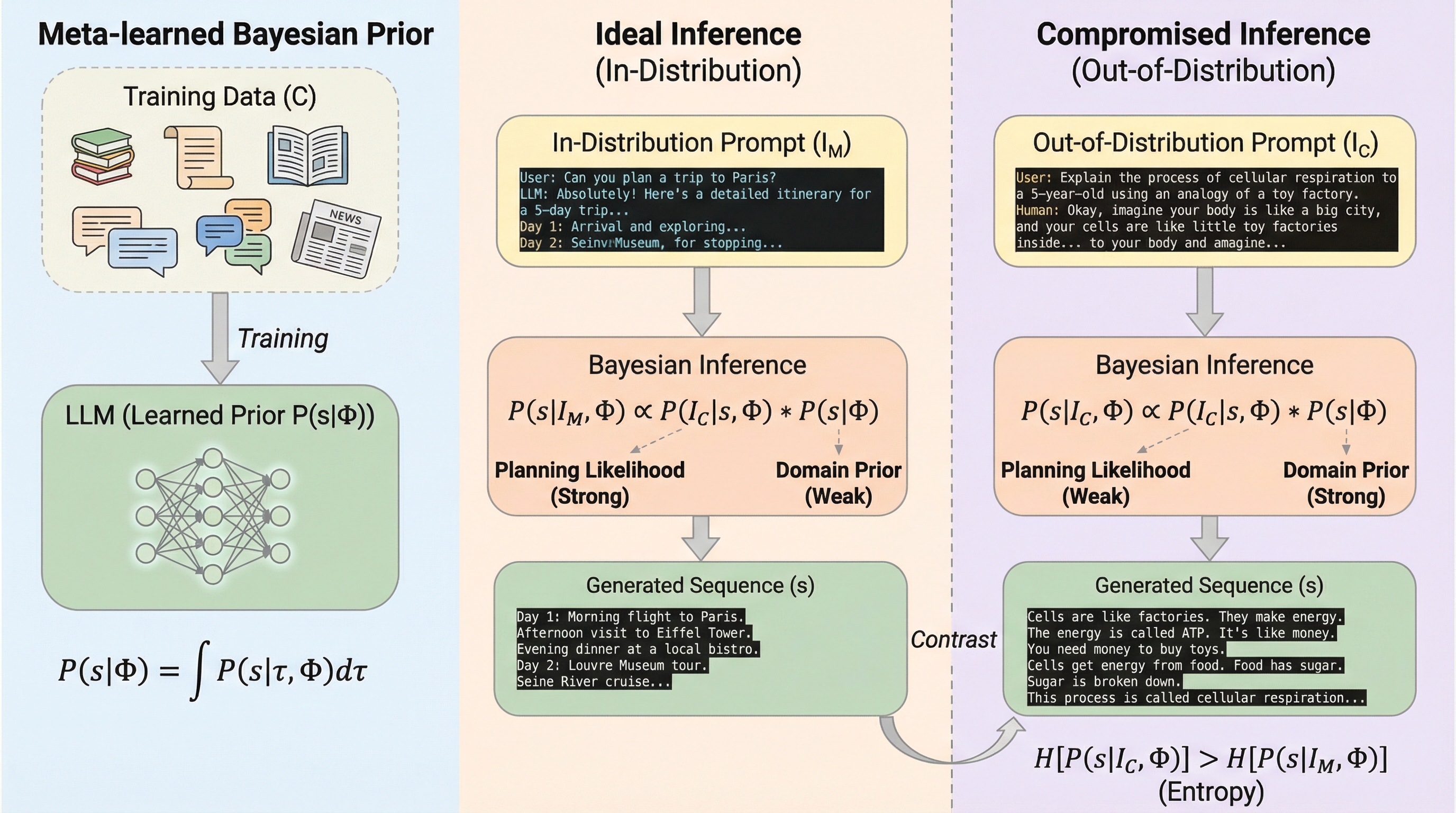
大規模言語モデル(LLM)は学習を通じて高度なシーケンスレベルの計画能力を獲得しているが、推論時には人間が作成したプロンプトとモデル内部の言語表現の乖離により、一時的に短期的で不整合な計画行動を示す。本研究はベイズ推論の枠組みを用い、自己生成された文脈が蓄積されることで不確実性が減少し、初期の「事前分布に偏った計画」から「指示に忠実な計画」へと動的に移行する「計画のシフト」現象を理論的に説明した。ランダムな数値生成およびガウス分布サンプリングの実験により、推論が進むにつれて計画の強度が向上し、初期のバイアスが自己修正される「バイアス発生とその後の解消」という動的な署名が確認され、モデルの潜在的な計画能力が推論プロセスを通じて回復することが証明された。
なぜこの問題か
大規模言語モデルは、基本的には次のトークンを自己回帰的に予測するように訓練されているが、近年の研究では、モデルが単なる近視眼的な予測を超えて、シーケンス全体を見据えた計画を行っていることが示唆されている。理論的には、次トークン予測の学習はエネルギーベースモデルにおけるシーケンスレベルのモデリングと等価であり、モデルは個々のトークンを生成する前に、将来の継続的な展開の全セットを意識しているはずである。しかし、実際の推論時における挙動を詳細に観察すると、モデルの計画能力は短期的であり、学習によって獲得されたはずの体系的な計画能力と、実際に展示される挙動との間には大きな隔たりが存在することが報告されている。この隔たりが生じるメカニズムは、これまで十分に解明されていなかった。特に、モデルが初期の層や中間の層で将来の情報をデコードできているにもかかわらず、なぜ最終的な出力においてその計画が完全には反映されないのかという点が大きな謎であった。 本研究はこの問題に対し、推論時の文脈が動的に変化することに着目している。…
核心:何を提案したのか
本研究は、LLMのシーケンスレベルの計画行動を説明するために、ベイズ推論の視点を導入した新しい理論モデルを提案した。モデルは、与えられたドメインの事前分布と、プロンプトが計画されたシーケンスによってどれだけ説明されるかを示す「計画尤度」を組み合わせることで、最適な応答シーケンスを推論すると定義されている。ここで最も重要な提案は、人間が作成したプロンプト(自然言語)と、モデルが真に内部化している言語(モデル言語)の間に存在する固有の差異が、推論時の計画を一時的に損なわせる根本的な原因であるという仮説である。 理想的な状況、つまりモデルの学習分布に完全に合致した入力が与えられた場合、モデルは適切な応答に対して高い計画尤度を割り当て、指示に従った一貫性のある応答を生成する。しかし、人間によるプロンプトが与えられた場合、モデルはその指示を解釈する際に大きな不確実性に直面する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related