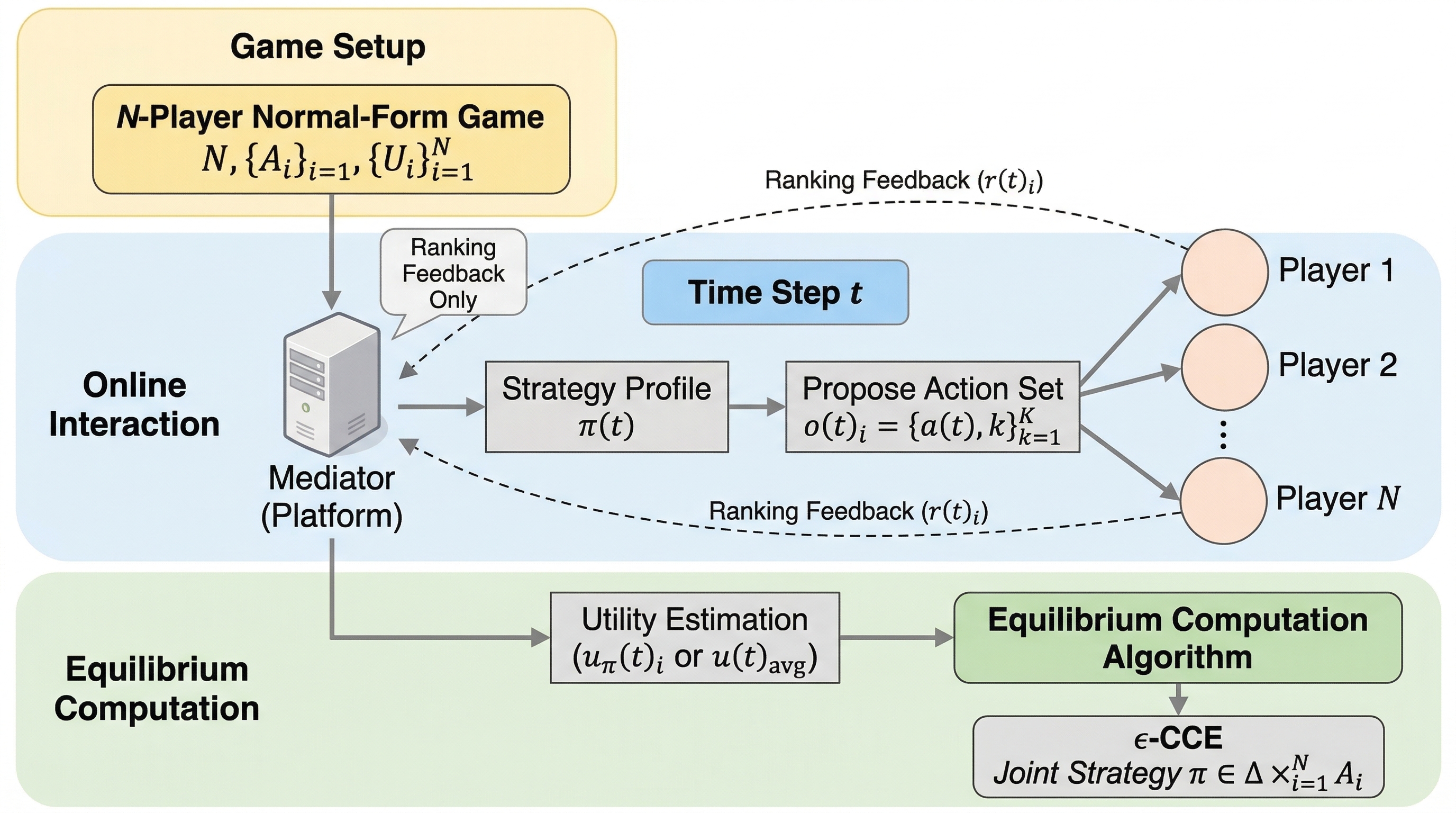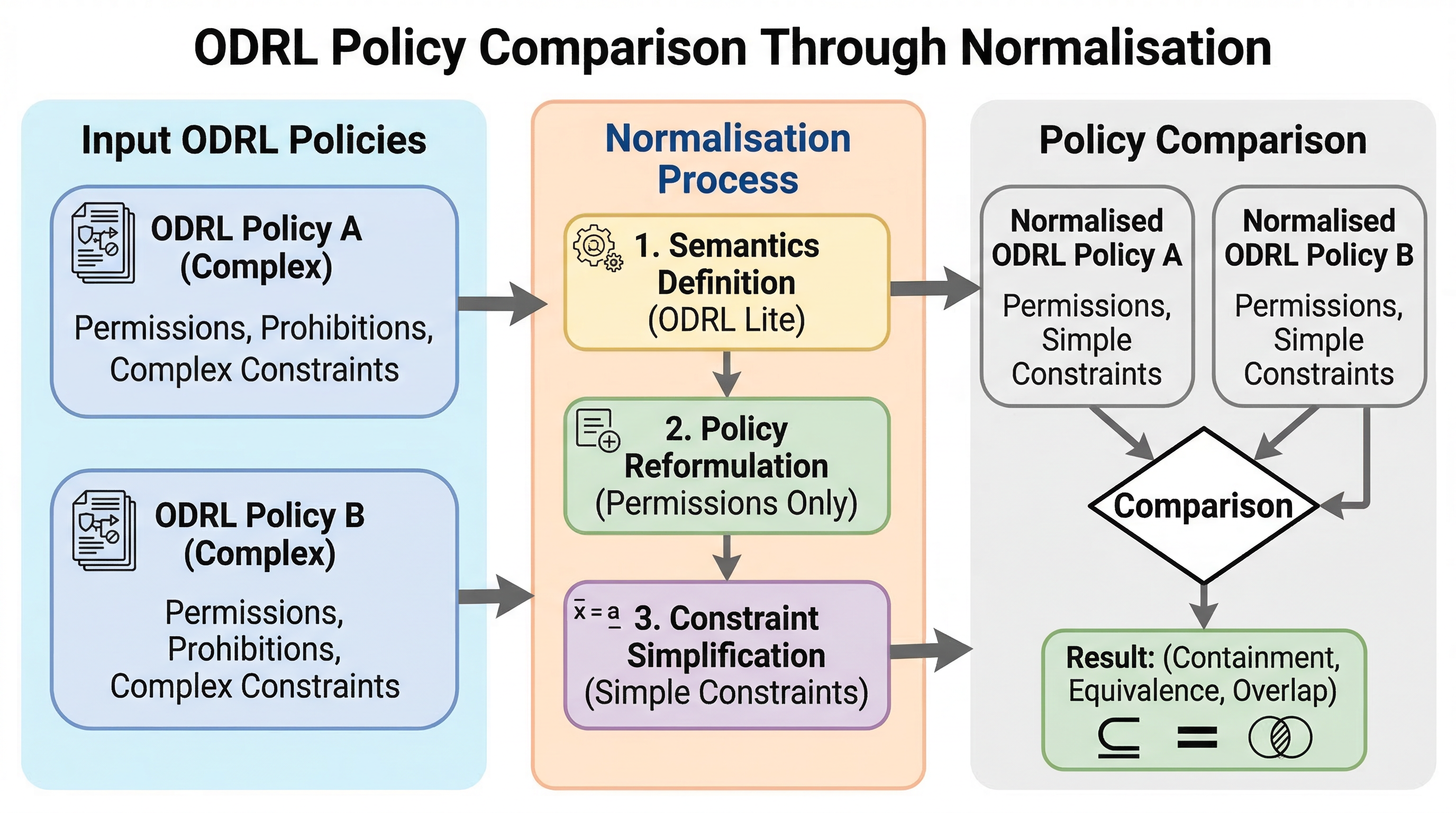
ClawTrap:OpenClaw を実ネットワーク上で監査する MITM レッドチーミング基盤
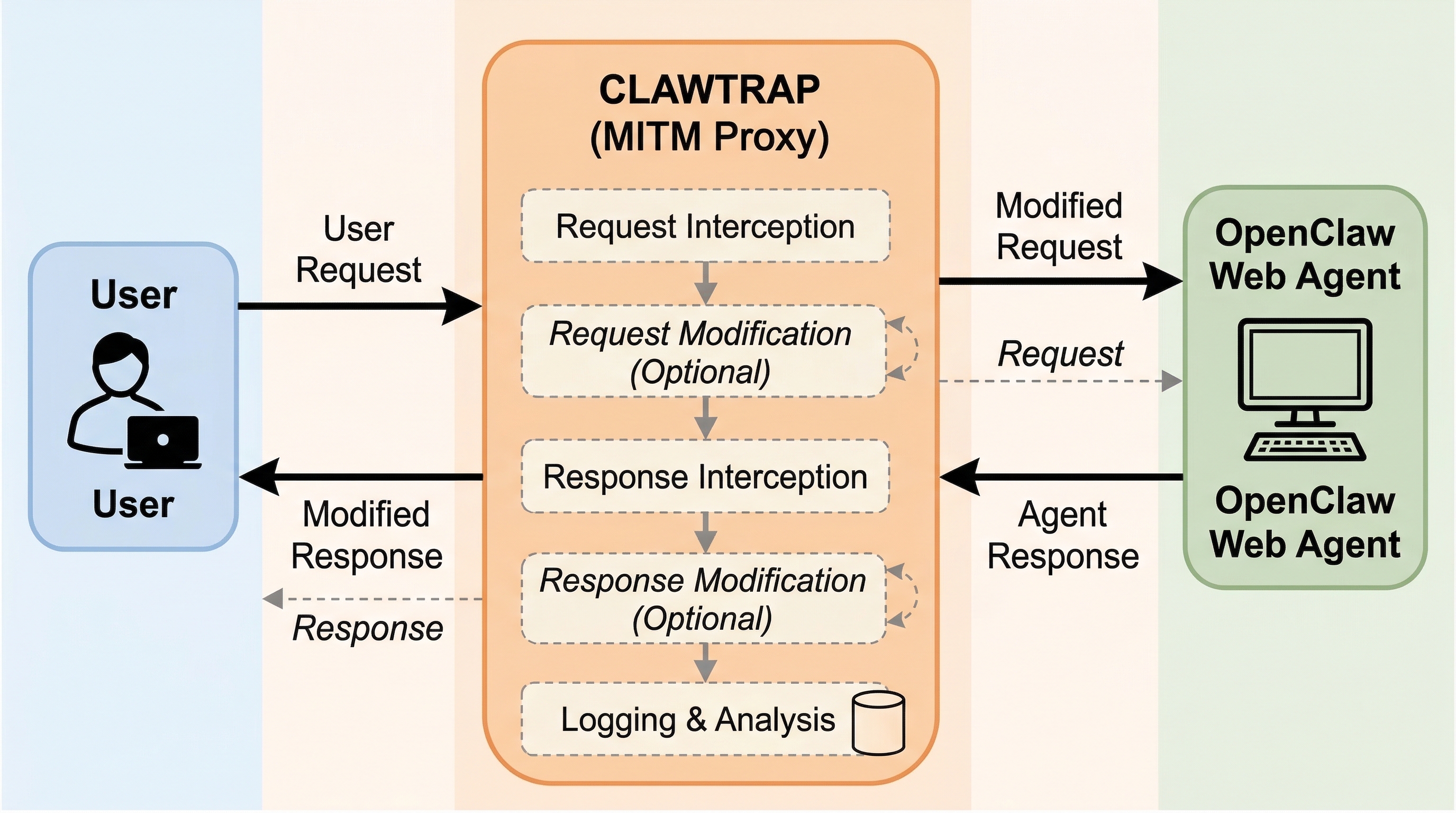
ClawTrap は、OpenClaw のような自律 Web エージェントに対し、実際の通信経路へ Man-in-the-Middle 攻撃を差し込んで安全性を調べる評価基盤です。静的サンドボックスや単純なプロンプト注入では見えにくい、ネットワーク層の改ざん耐性を測ることを目的にしています。 核心は、クラウド側で動く OpenClaw と研究者のローカル環境の間に Tailscale と mitmdump ベースの中継層を置き、Static HTML Replacement、Iframe Popup Injection、Dynamic Content Modification の3種類の攻撃を再現可能な形で実行できるようにした点です。 v1 の実験は大規模ベンチマークではなく代表的な実ブラウジングデモが中心ですが、弱いモデルほど改ざんされた観測を信用しやすく、強いモデルほど「ネットワーク改ざんかもしれない」と原因帰属しながら安全側へ倒れることを示しています。