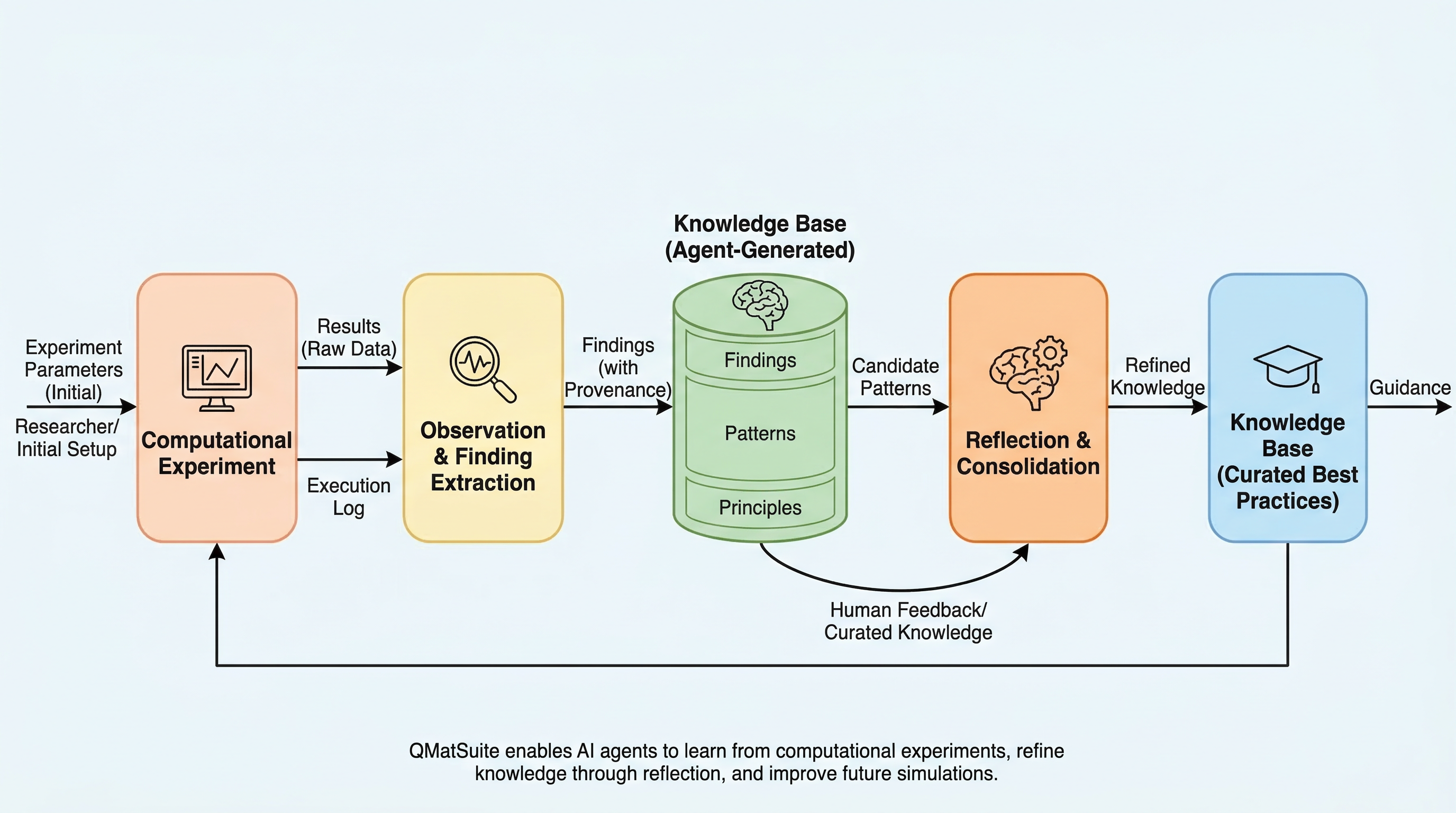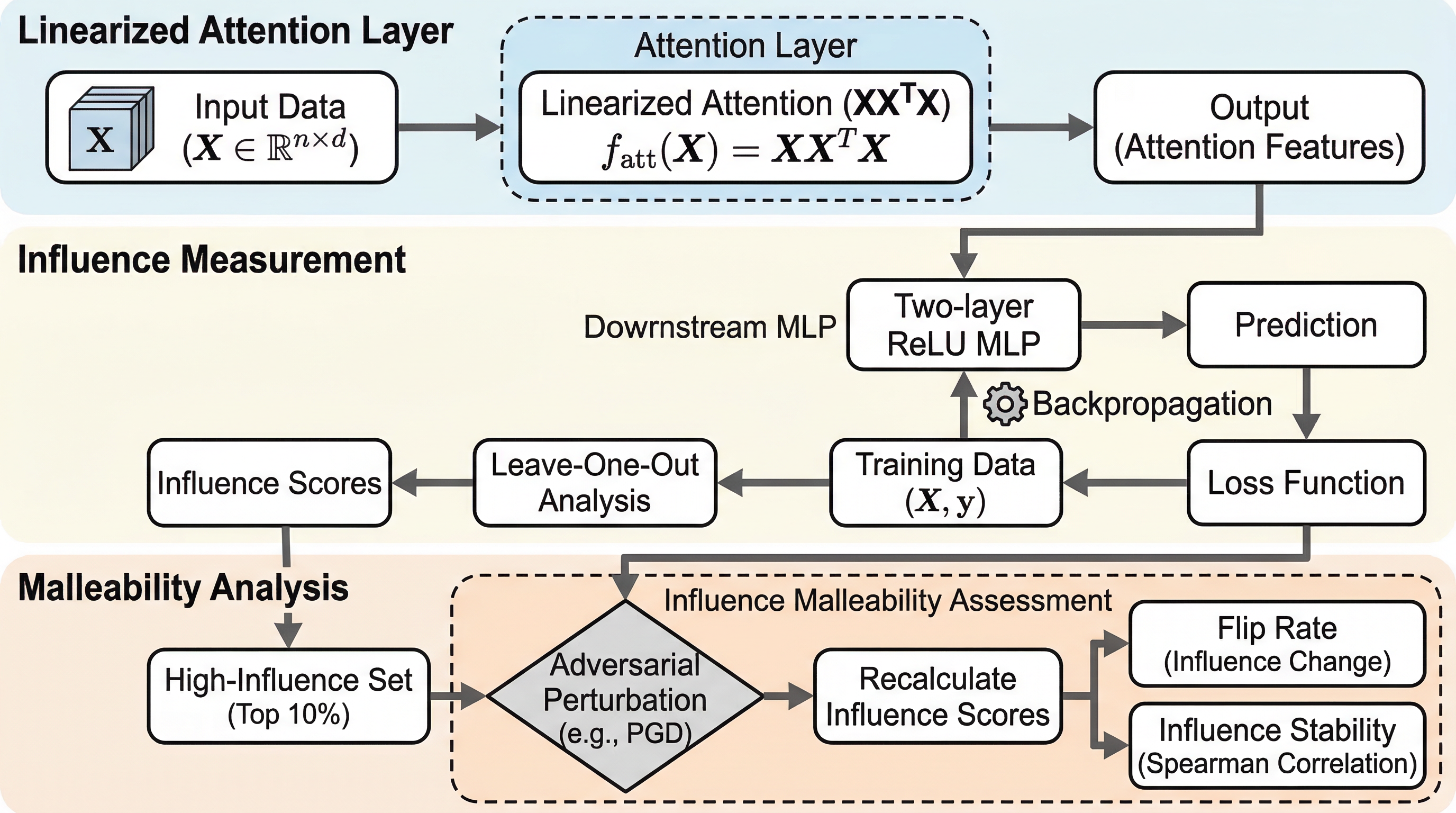
線形化注意はなぜ「効く」と同時に「危うい」のか:Influence Malleability が示す二面性
線形化した注意機構は、幅を十分に大きくしても無限幅NTKへ素直に近づかず、ReLU系のような「固定カーネルに近い学習」へ入らないことが、理論と実験の両方から示されます。 その理由は、注意変換が Gram 行列の条件数を三乗で増幅し、NTK 収束に必要な幅を実用外の大きさまで押し上げるためで、その非収束性が訓練データへの依存の変わりやすさ、すなわち influence malleability として観測されます。 この性質は、データ構造に合うと近似誤差を下げる源泉である一方、訓練データを少し細工されただけで reliance が大きく変わる脆さの源泉でもあり、注意の強みと弱みが同じ場所から生まれていると整理されます。