モデルが静かに壊れ始めたときにどう気づくか:いつ止めても正しい校正監視 PITMonitor
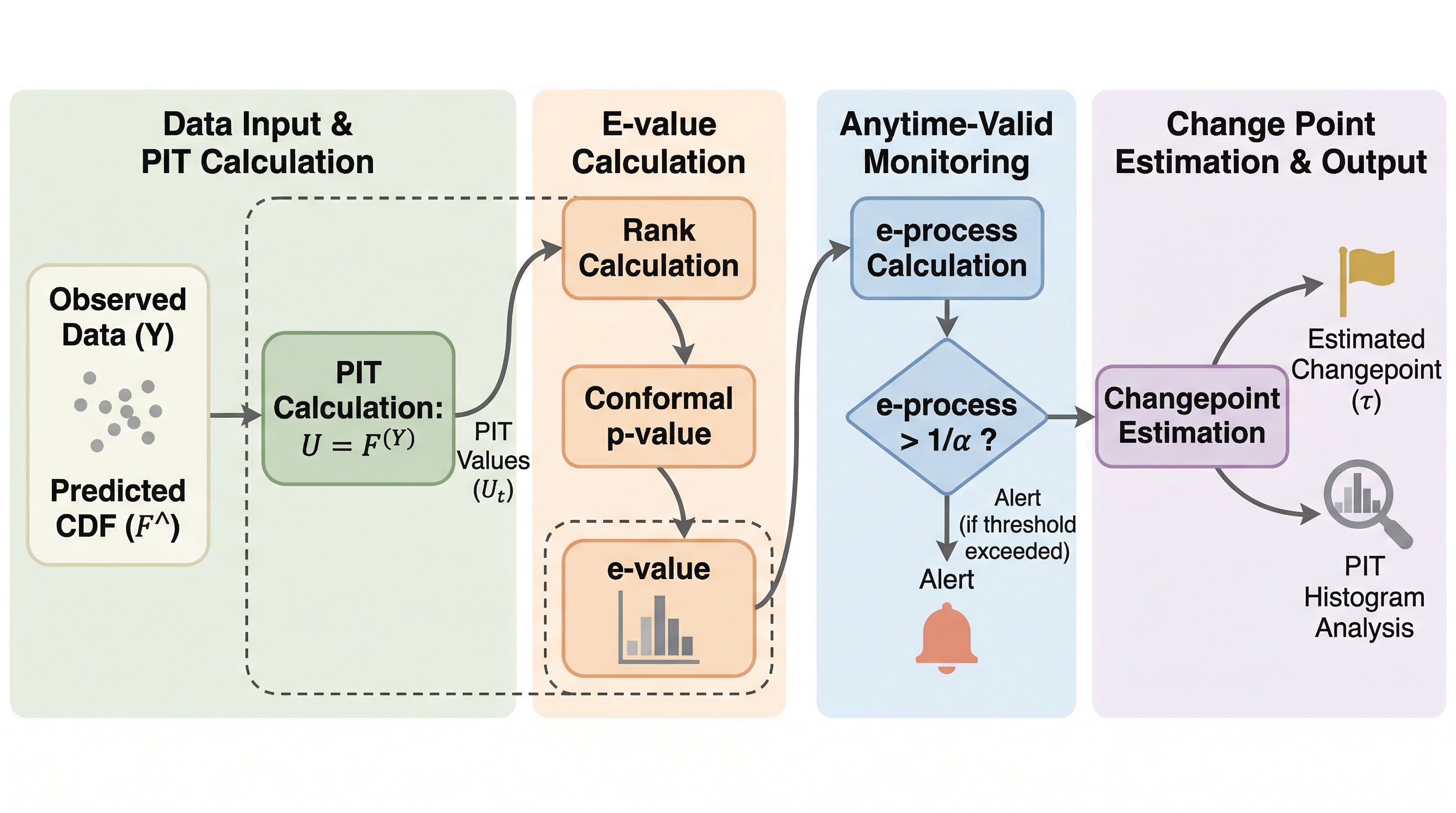
運用中の確率モデルを毎日監視するなら、固定標本検定を繰り返すだけでは、モデルが健全でもいずれ誤警報が出ます。PITMonitor はそこを正面から扱い、監視期間を事前に決めなくても「いつか誤報する確率」を水準 α で抑える校正監視法です。 監視対象を誤差率や残差平均ではなく、予測分布と実データの関係を直接表す PIT に置くことで、精度が変わらなくても起こる過信・過小信頼・尾部確率のズレまで拾えるようにしています。 FriedmanDrift ベンチでは、グローバルな急変・緩慢変化では強いベースラインと競れる検出率を保ちつつ、偽陽性率を 3.8% に抑えました。一方で局所的かつ多段階に広がるドリフトでは遅延が大きく、そこが主要な弱点として残ります。
TL;DR(結論)
- 運用中の確率モデルを毎日監視するなら、固定標本検定を繰り返すだけでは、モデルが健全でもいずれ誤警報が出ます。PITMonitor はそこを正面から扱い、監視期間を事前に決めなくても「いつか誤報する確率」を水準
αで抑える校正監視法です。 - 監視対象を誤差率や残差平均ではなく、予測分布と実データの関係を直接表す PIT に置くことで、精度が変わらなくても起こる過信・過小信頼・尾部確率のズレまで拾えるようにしています。
- FriedmanDrift ベンチでは、グローバルな急変・緩慢変化では強いベースラインと競れる検出率を保ちつつ、偽陽性率を 3.8% に抑えました。一方で局所的かつ多段階に広がるドリフトでは遅延が大きく、そこが主要な弱点として残ります。
なぜこの問題か
確率モデルを本番運用するとき、本当に怖いのは「精度が少し落ちた」ことそのものより、予測確率を信じてよいか分からなくなることです。医療、金融、需要予測のような場面では、0.9 の確率が本当に 90% くらい当たるのか、0.1 の確率が本当に滅多に起きないのかが意思決定に直結します。だから、本番で見るべきなのは accuracy だけではなく calibration です。
核心:何を提案したのか
提案の中心は PITMonitor です。名前の通り、予測分布から得られる probability integral transform, すなわち PIT の分布が時間とともに変わったかを監視します。PIT は、予測CDFに実際の観測値を通したスカラー量で、モデルが完全に校正されていれば一様分布に従います。逆に、過信、過小分散、位置ずれ、尾部のズレなど、予測分布と現実のズレはすべて PIT 分布の歪みとして現れます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related