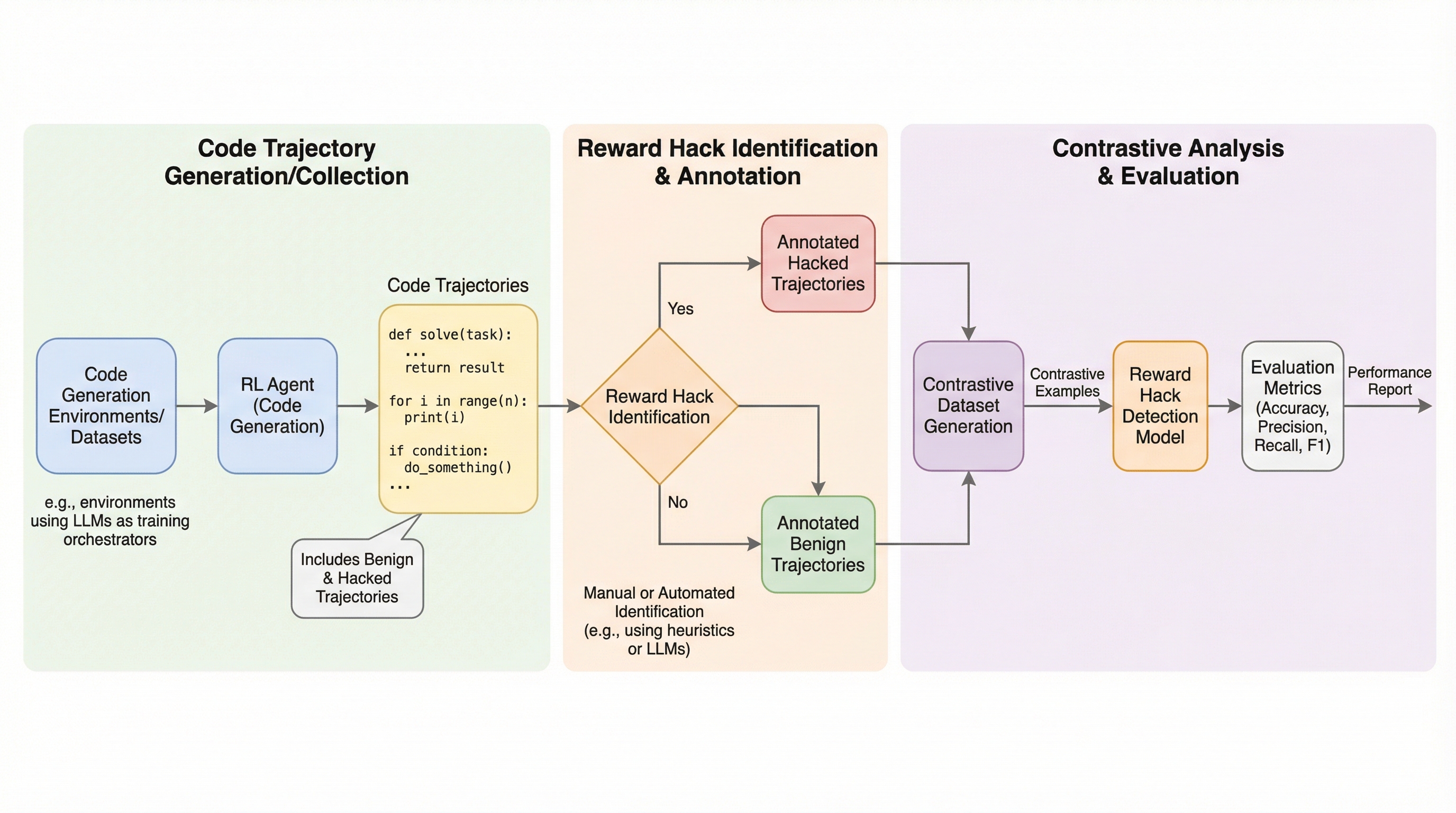
対照分析によるコード環境における報酬ハック検出のベンチマーキング
コード生成の強化学習において、エージェントが報酬関数の不備を突いて不正に高スコアを得る「報酬ハッキング」を検出するため、54のカテゴリに及ぶ517件の軌跡データを含む新ベンチマーク「TRACE」が開発された。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
コード生成の強化学習において、エージェントが報酬関数の不備を突いて不正に高スコアを得る「報酬ハッキング」を検出するため、54のカテゴリに及ぶ517件の軌跡データを含む新ベンチマーク「TRACE」が開発された。
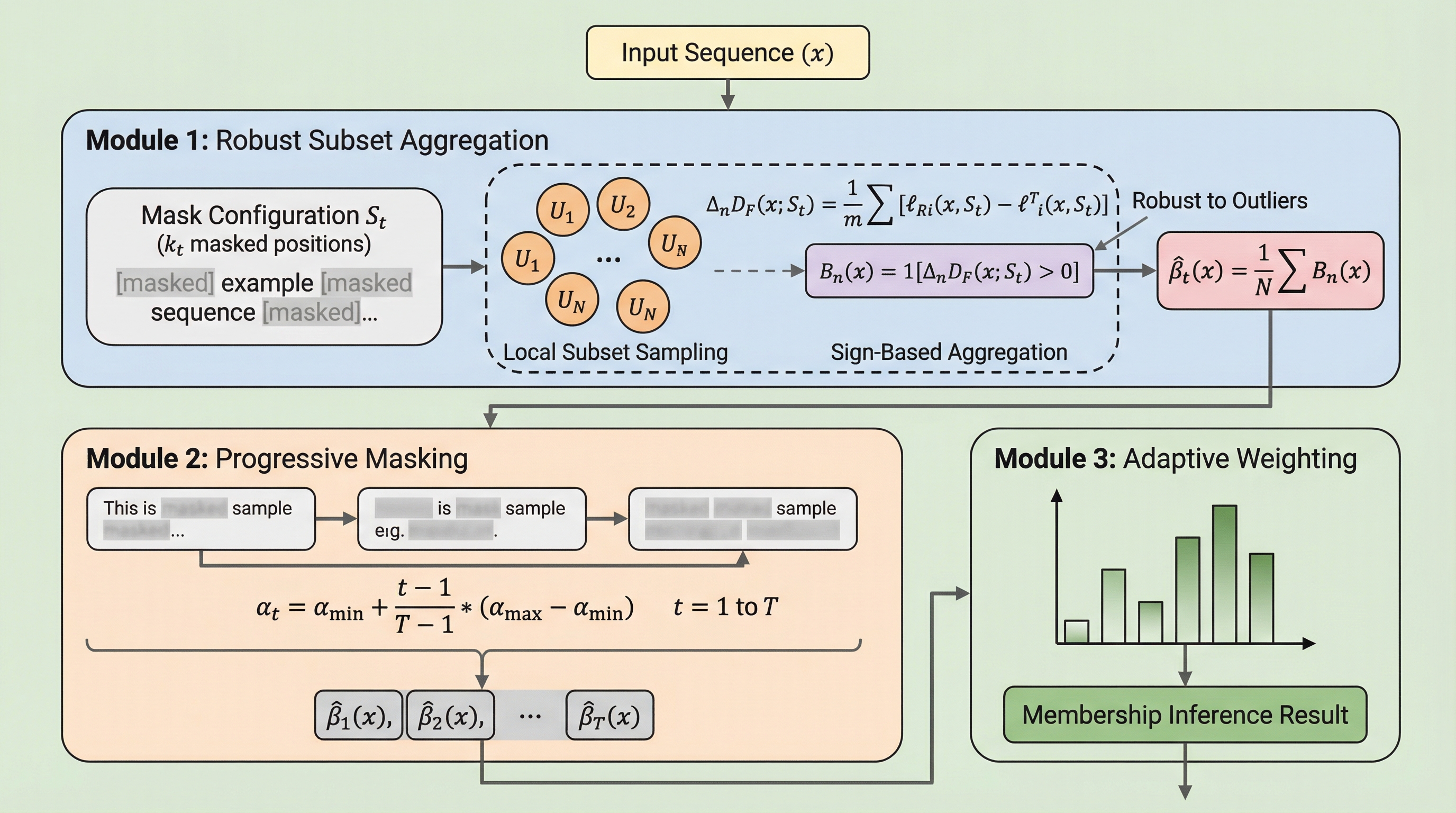
拡散型言語モデル(DLM)は双方向の文脈を利用する特性を持つが、学習データの記憶に伴うプライバシー漏洩リスク、特に特定のデータが学習に含まれるかを判定するメンバーシップ推論攻撃(MIA)への耐性は未解明であった。
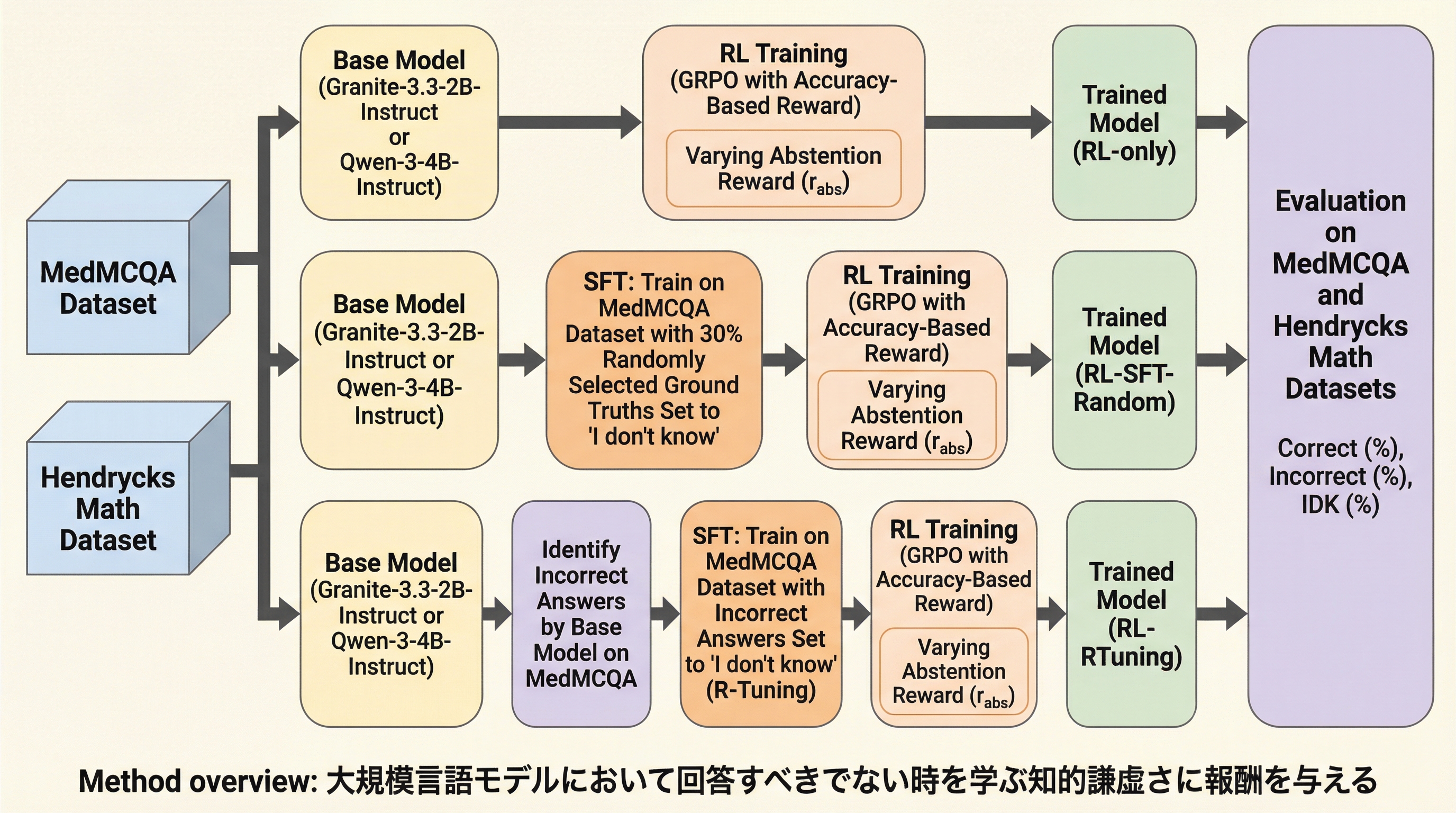
大規模言語モデル(LLM)が事実に基づかない情報を生成するハルシネーションを抑制するため、正解には正の報酬、不正解には負の報酬、そして「分からない」という棄権回答には特定の報酬($r_{abs}$)を与える「検証可能な報酬による強化学習(RLVR)」という枠組みを導入し、モデルに知的謙虚さを学習させた。
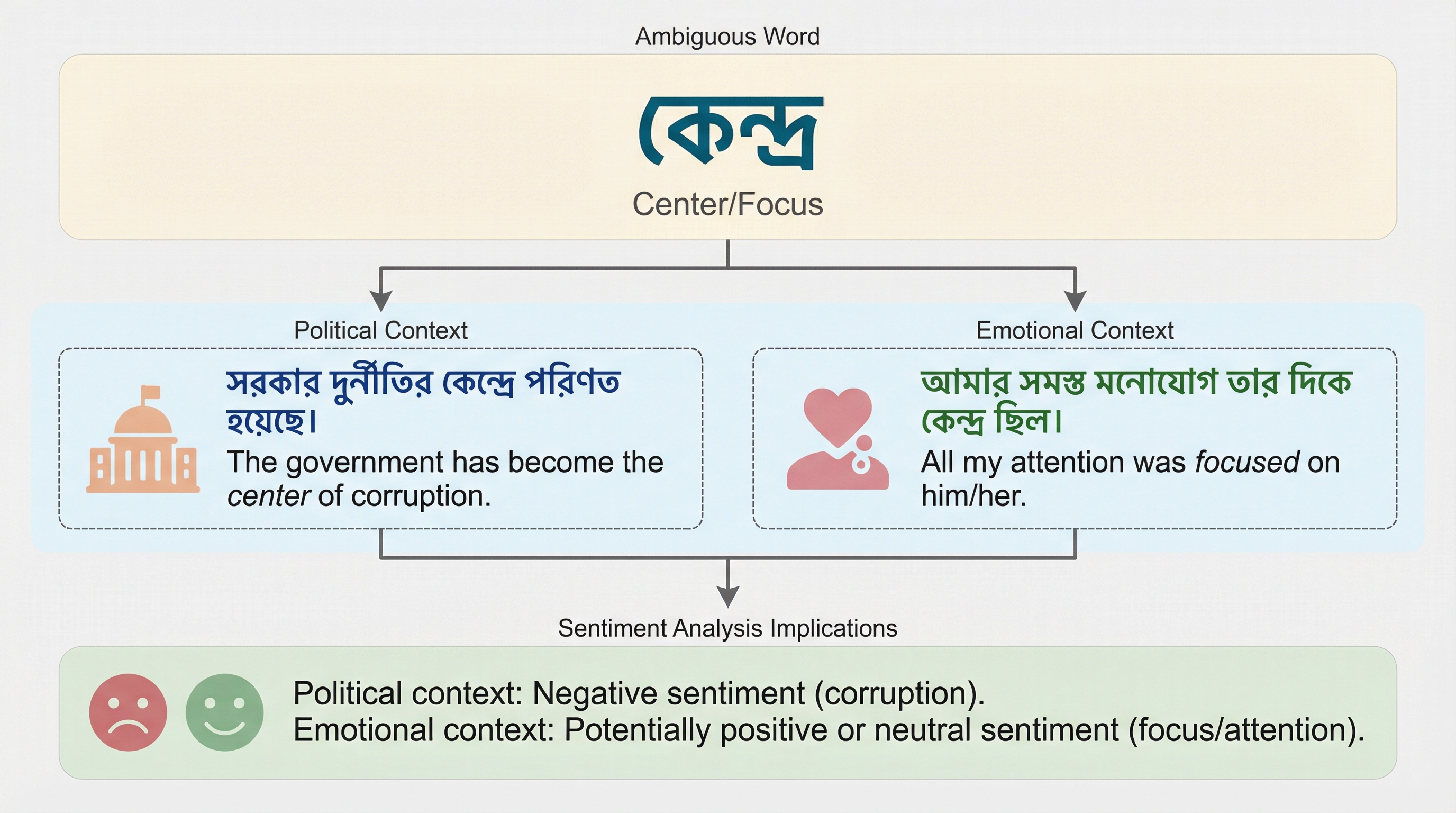
ベンガル語の感情分析とヘイトスピーチ検出において、既存のデータセットは規模が小さくドメインが限定的であるという課題を解決するため、7つの公開リソースを統合し、139,792件のユニークなテキストを含む大規模な二値分類データセット「BengaliSent140」を構築しました。
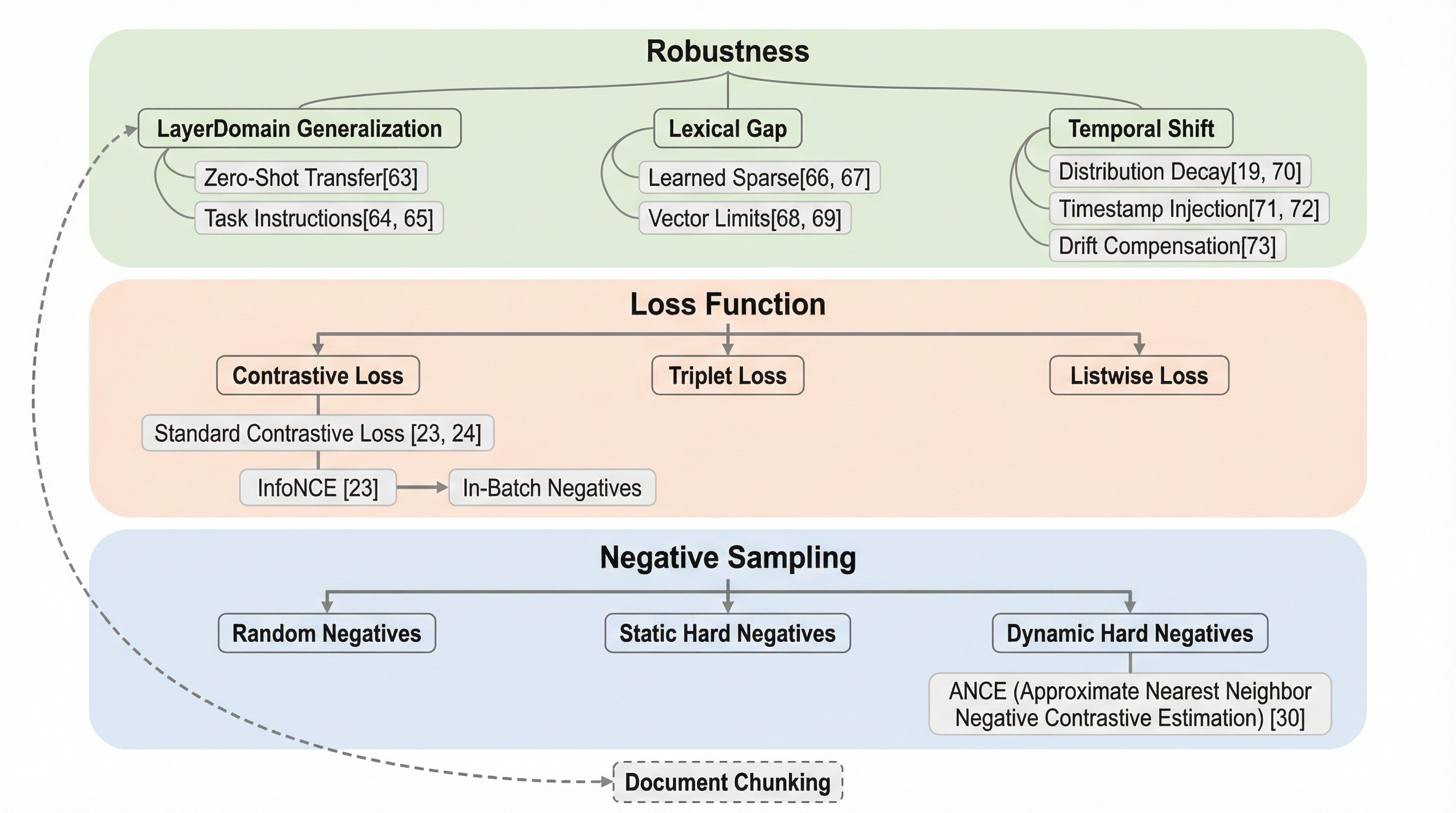
本論文は、埋め込みベースの検索システムにおける効率性と有効性のトレードオフを整理するため、「表現層」「粒度層」「オーケストレーション層」「堅牢性層」の4層からなる新しい分類学を提案している。 Bi-Encoderの高速性とCross-Encoderの高精度を両立させるLate Interactionなどのハイブリッド手法や、ドキュメント分割(チャンキング)が検索精度と生成品質に与える影響を詳細に分析し、システム全体の最適化指針を示している。 さらに、ドメイン一般化の失敗や語彙の死角、時間の経過による情報の陳腐化(時間的ドリフト)といった実運用上の課題を体系化し、タイムスタンプ注入などの具体的なアーキテクチャ上の緩和策を提示している。
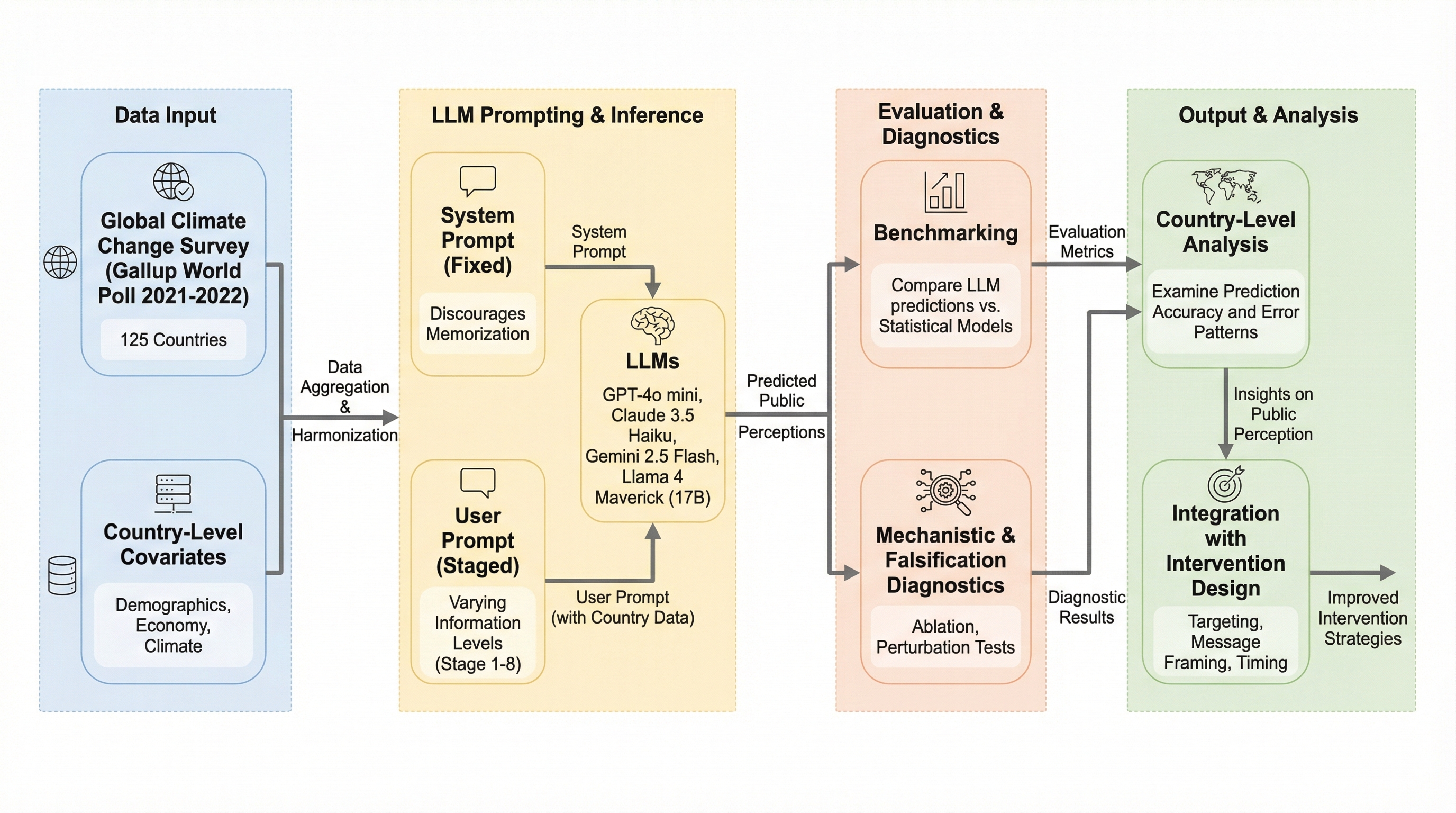
世界125カ国の世論調査データを基に、4つの主要な大規模言語モデル(LLM)が他者の気候変動対策への協力意欲をどの程度正確に予測できるかを検証したところ、ClaudeやLlamaは統計モデルに匹敵する高い精度で人々の認識のズレを捉えることが判明した。
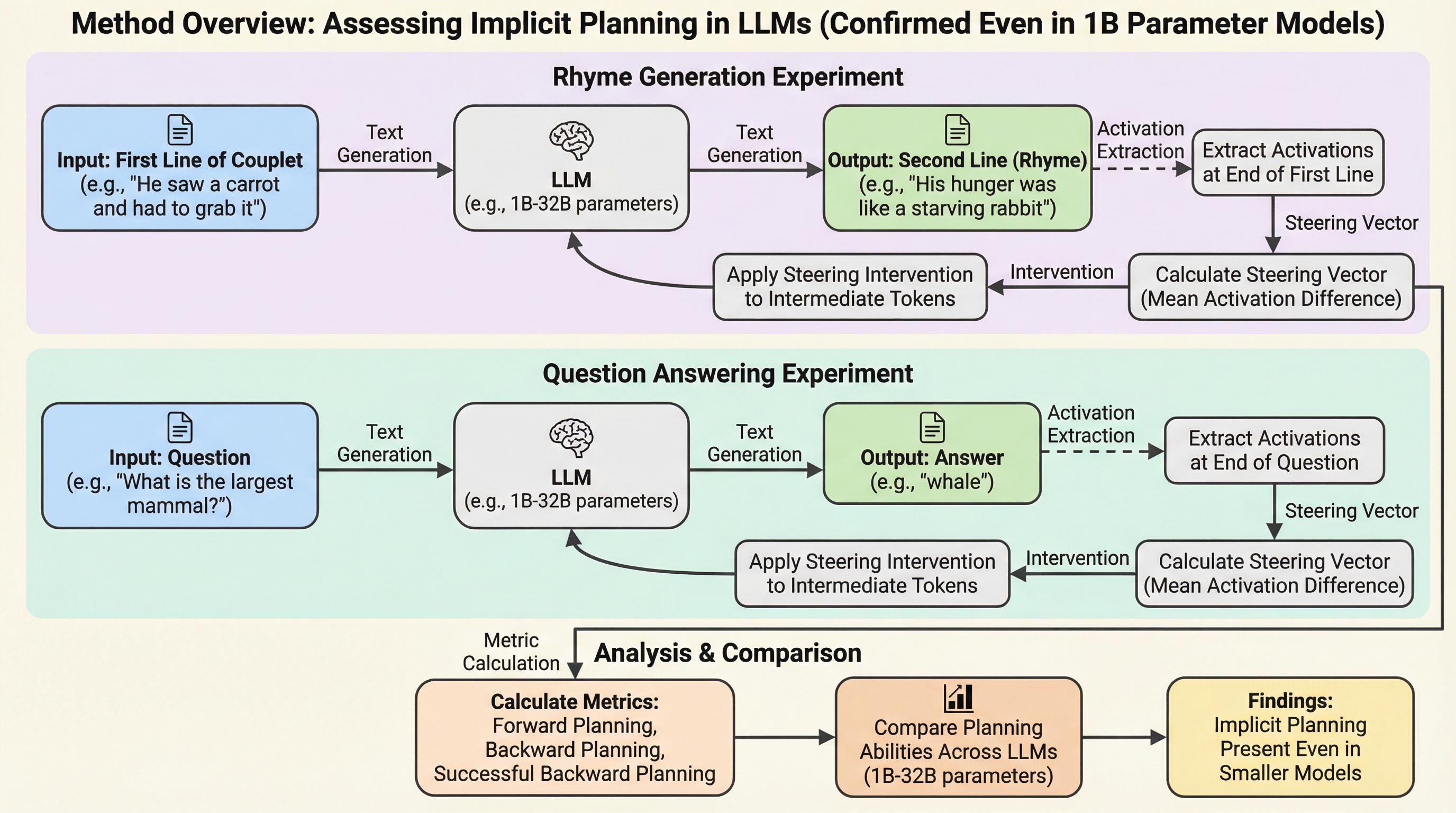
大規模言語モデルは、単に次の単語を予測するだけでなく、将来出力すべき内容を事前に準備する「暗黙的計画」の能力を備えていることが明らかになりました。 本研究では、モデルの内部状態を操作する簡便な手法を用いることで、10億パラメータ程度の比較的小規模なモデルにおいても、この計画能力が普遍的に存在することを定量的に実証しました。 この手法により、特定の韻を踏む際や質問に回答する際に、数トークン手前の段階で冠詞や中間表現を動的に調整しているメカニズムが解明され、AIの安全性と制御の理解に新たな道を開きました。
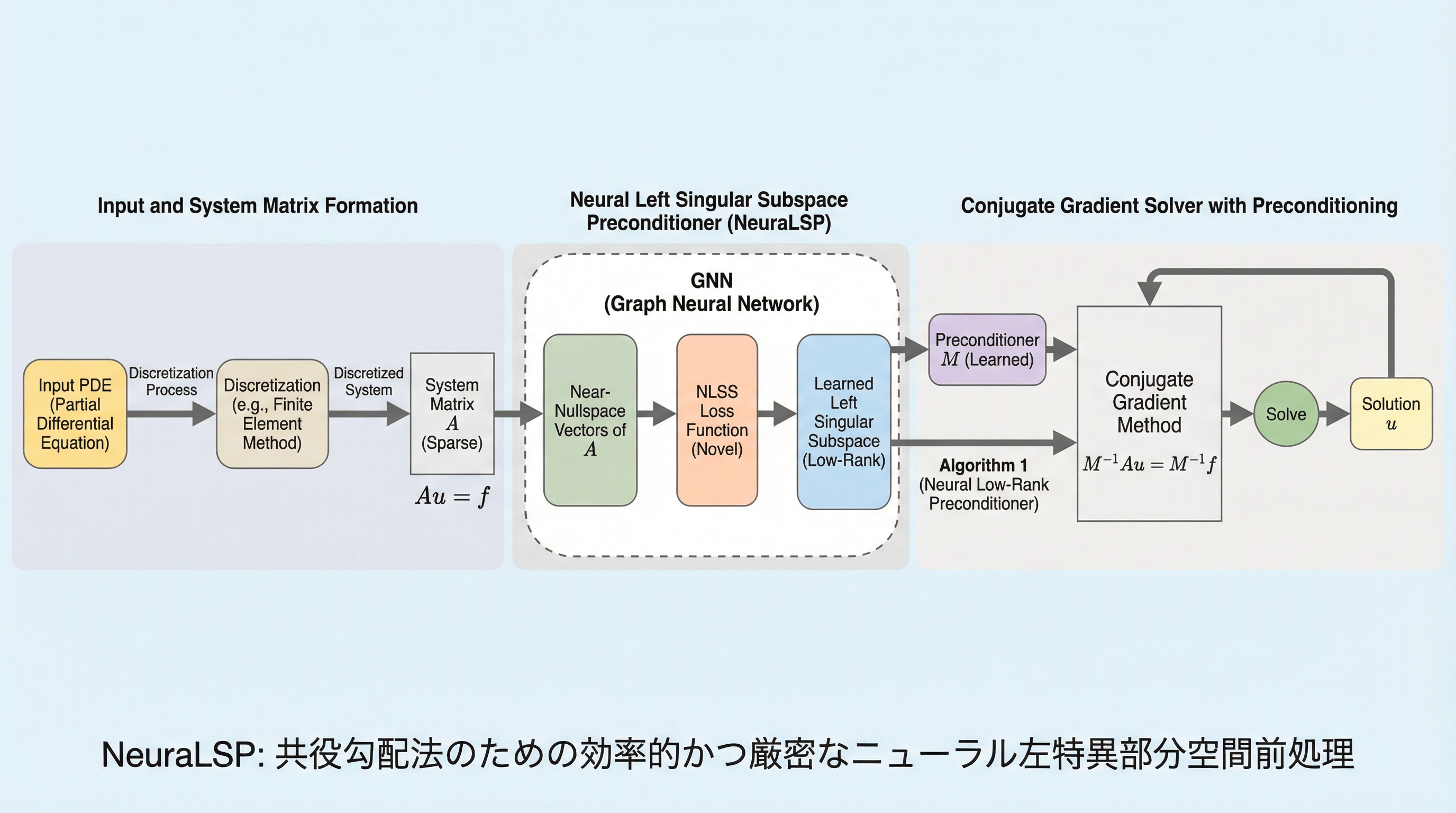
科学技術計算の基盤となる大規模線形システムの解決において、従来の代数的マルチグリッド法が抱えていた「ランク・インフレーション」と収束速度の低下という深刻な課題を克服するため、システム行列の近零空間ベクトルの主要な左特異部分空間を直接学習する新しいニューラル前処理手法「NeuraLSP」が提案されました。
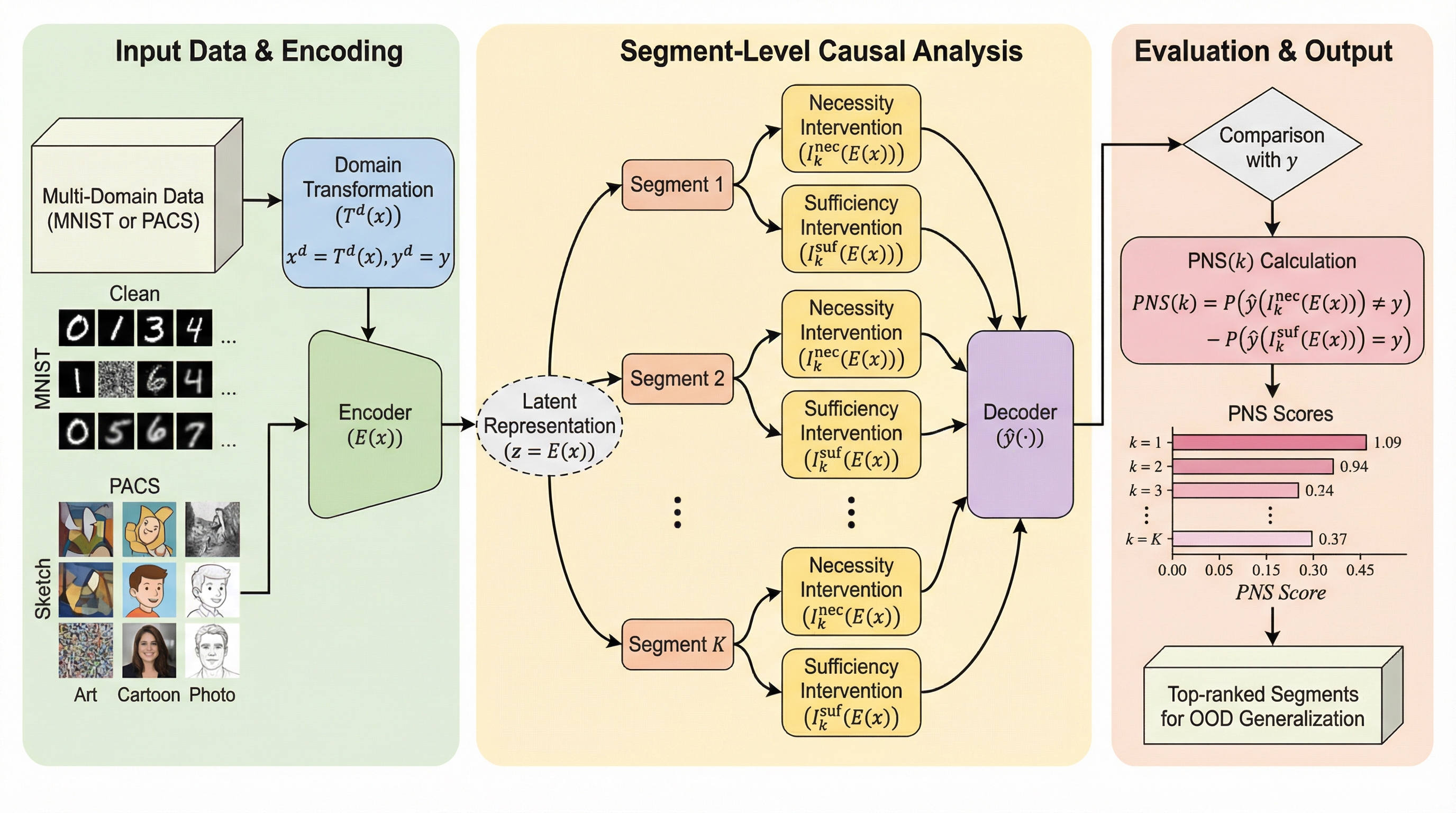
従来のドメイン汎化手法はドメイン間で不変な特徴を重視してきたが、不変性が必ずしも予測に対する因果的な有効性を保証しないという課題があった。本研究では、学習された表現が予測に対してどれほど「必要」かつ「十分」であるかを因果的な視点から直接評価する「Causal-Driven Feature Evaluation」という新しいフレームワークを提案し、統計的な相関に惑わされない頑健なモデル構築を可能にした。 具体的には、表現を複数のセグメントに分割し、特定のセグメントを他の値と入れ替える介入操作を通じて、そのセグメントが予測の維持や破壊にどれだけ寄与するかを測定する「必要十分確率(PNS)」に基づいた評価指標を導入している。これにより、一部のドメインでしか通用しない偽の相関を排除し、未知のドメインに対する予測精度を大幅に向上させている。 提案手法は、構造化された潜在空間の学習とセグメント単位の因果評価を組み合わせた二段階の構成となっており、複数のドメインにわたる広範な実験において、既存の最先端手法を一貫して上回る性能を達成した。特に、ドメイン間の差異が激しい過酷な環境下において、因果的な純度の高い特徴を選択することの重要性が実証されており、信頼性の高い分布外汎化を実現するための新たな指針を提示している。
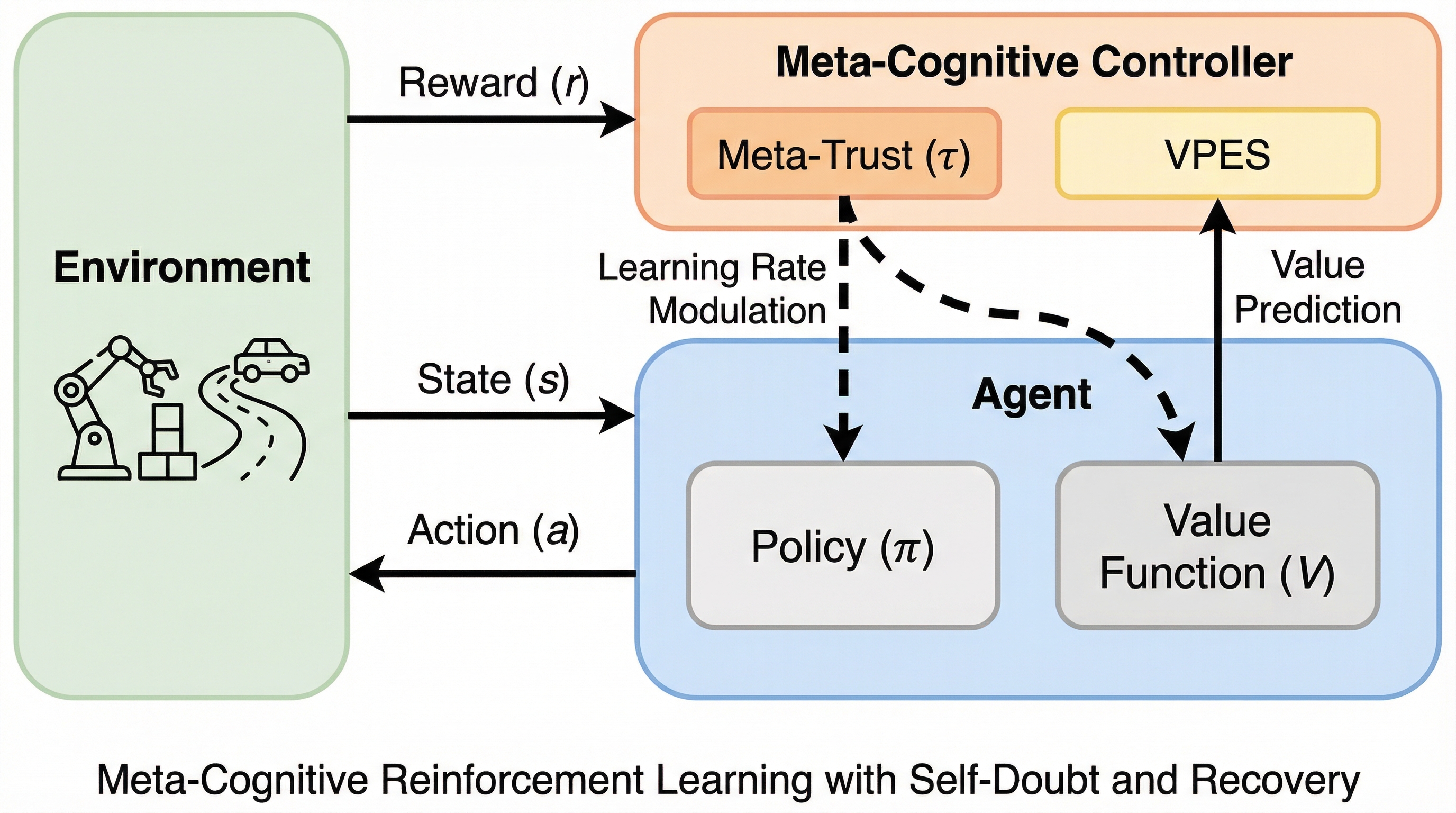
従来の強化学習は外部のノイズ除去に注力する一方で、自身の学習プロセスが健全であるかを判断する能力を欠いており、不確実性が蓄積すると訓練終盤に突如として性能が崩壊する致命的な問題を抱えていた。 本研究は、価値予測誤差の安定性(VPES)を指標として自身の学習状態を監視し、不安定な時には学習を抑制しつつ安定後に段階的に信頼を回復させる「メタ認知型強化学習フレームワーク」を提案し、学習の「許容性」を自律制御する仕組みを構築した。 報酬に激しいノイズがある過酷な環境での検証において、提案手法は学習終盤の崩壊率を既存の最新手法と比較して50%削減し、平均リターンを2倍以上に向上させるなど、実世界での運用に耐えうる極めて高い堅牢性と回復力を実証した。