モデルが審査員より賢くなるとベンチマークは飽和する
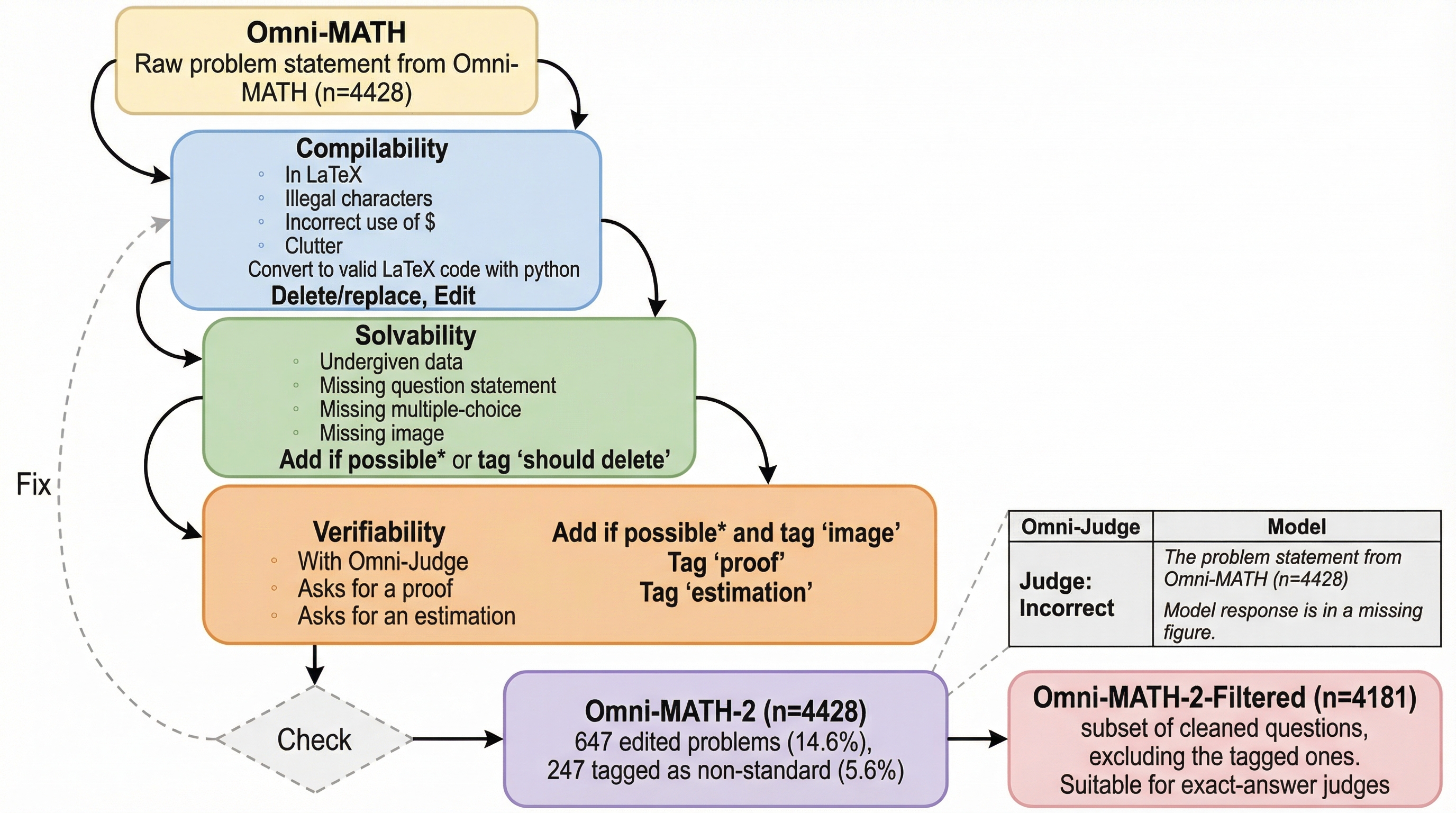
大規模言語モデル(LLM)の数学能力を測定する既存ベンチマーク「Omni-MATH」を精査し、データセットの不備修正と詳細なタグ付けを行った改訂版「Omni-MATH-2」を構築した。 検証の結果、評価役のモデル(審査員)が被評価モデルの実力向上に追いつけず、正解の同等性を正しく判定できないことで、モデル間の真の性能差が隠蔽される「審査員による飽和」現象が確認された。 特に難易度が高い問題ほど審査員間の不一致が増大し、従来の審査員は不一致事例の96.4%で誤判定を下していたことから、今後の評価には被評価モデルを上回る高度な審査員の存在が不可欠である。