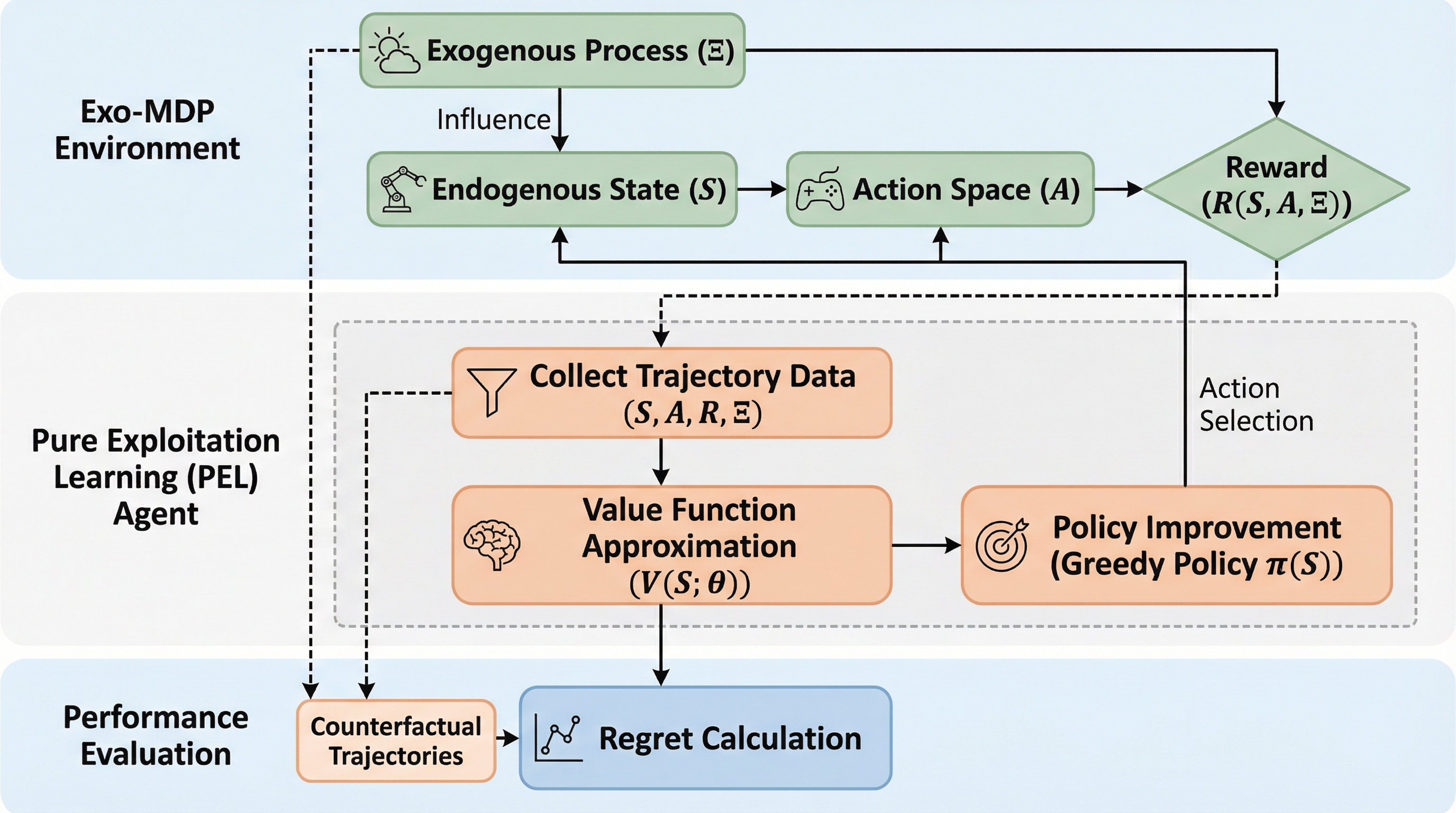
線形関数近似を用いた外生的MDPにおいて純粋な活用だけで十分か?
外生的MDP(Exo-MDP)は、需要や価格などの外部要因が意思決定者の行動に依存せず進化するモデルであり、本研究は探索を一切行わない「純粋な活用(Pure Exploitation)」のみで理論的に最適な学習が可能であることを初めて証明しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
外生的MDP(Exo-MDP)は、需要や価格などの外部要因が意思決定者の行動に依存せず進化するモデルであり、本研究は探索を一切行わない「純粋な活用(Pure Exploitation)」のみで理論的に最適な学習が可能であることを初めて証明しました。
製造業の企業資源計画(ERP)において不可欠なジョブショップ・スケジューリング(JSP)やナップサック問題(KP)といった組合せ最適化に対し、複数のアテンション機構を統合した「マルチタイプTransformer(MTT)」を適用し、異なる構造を持つ課題を統一的に解決するフレームワークを構築しました。
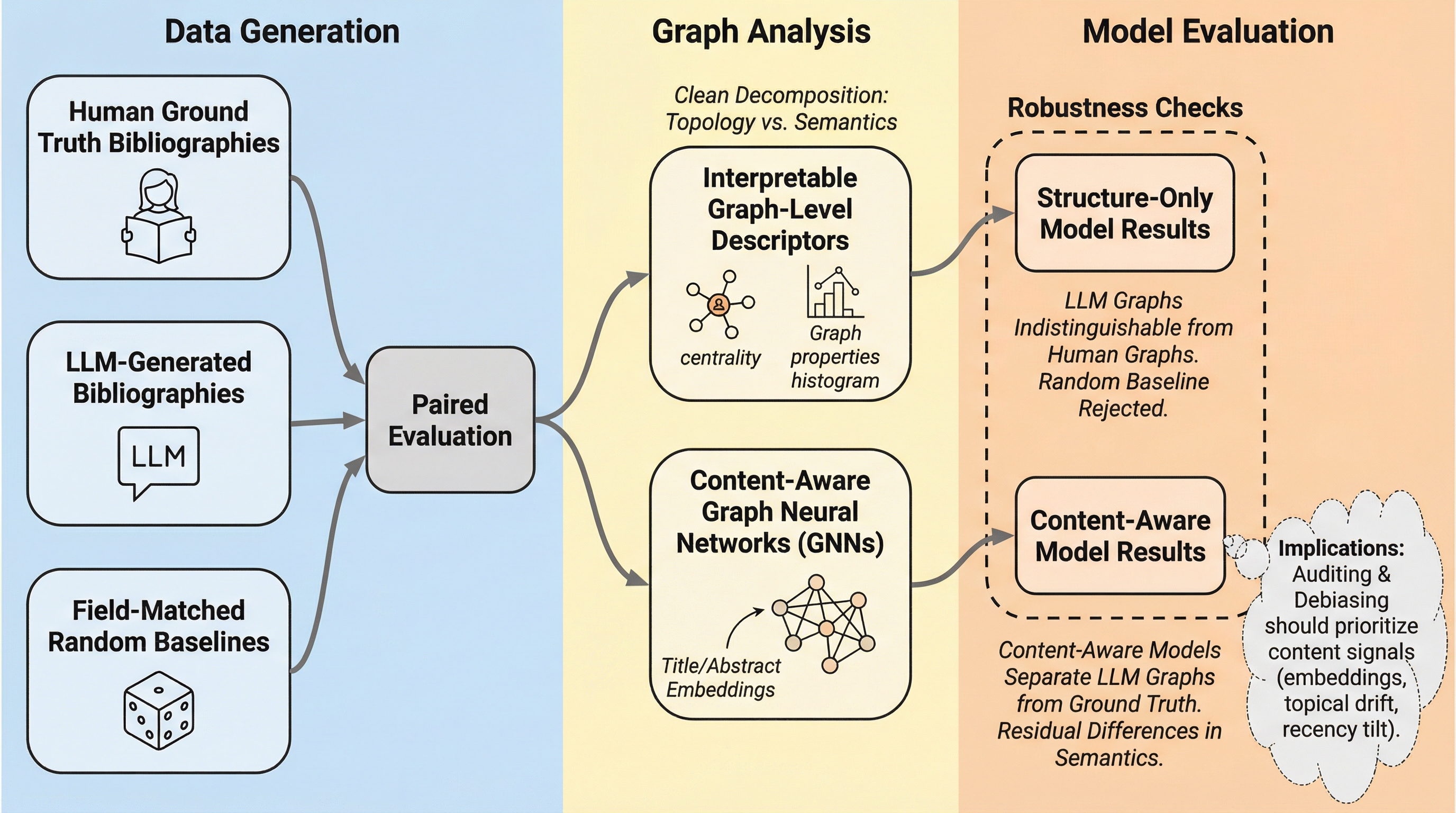
大規模言語モデル(LLM)が生成する参考文献リストは、引用ネットワークの構造的側面(中心性やクラスター係数など)において人間が作成したものと極めて高い類似性を持っており、従来のグラフ解析のみでは識別が困難であることが判明しました。
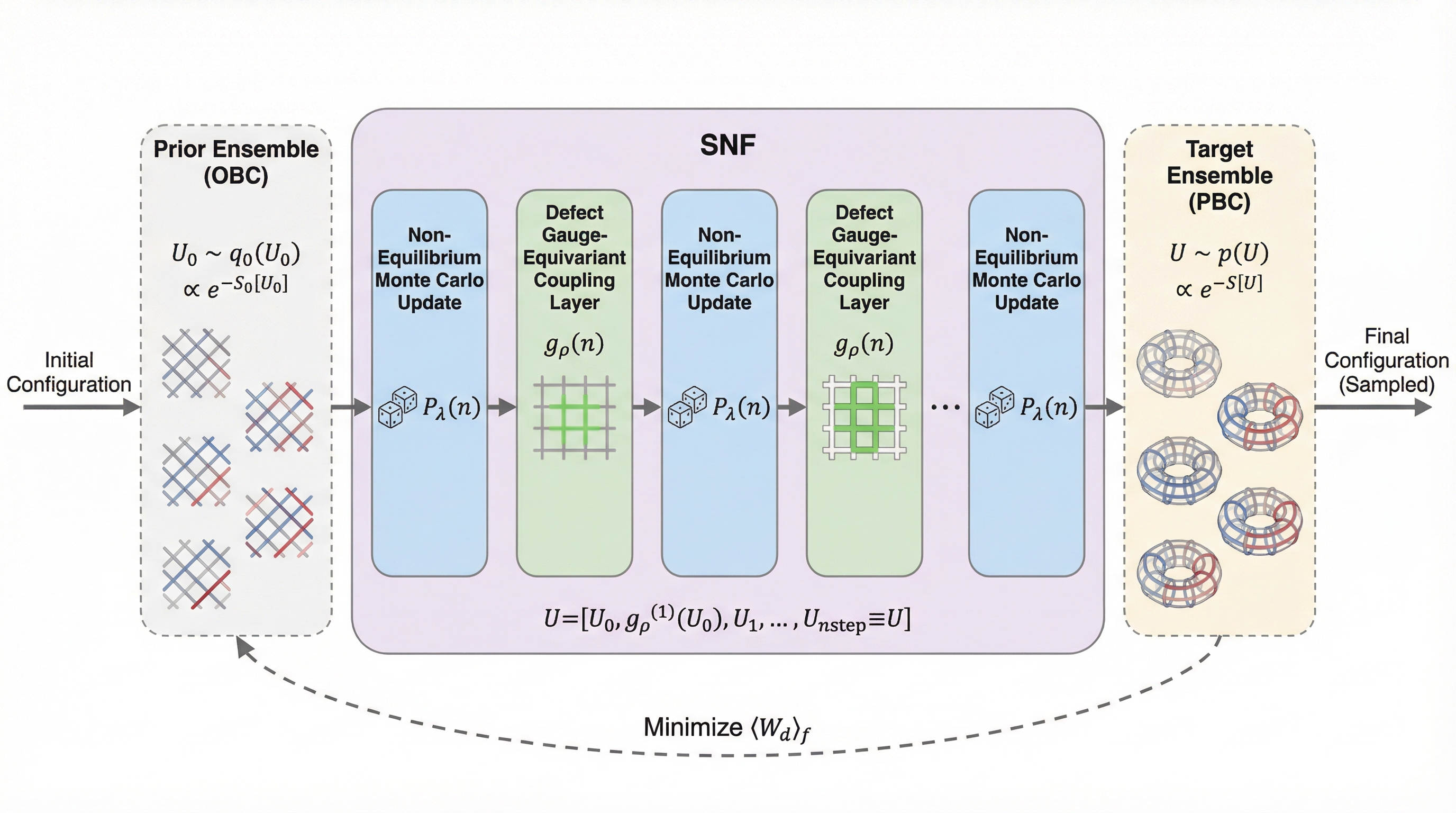
4次元SU(3)ゲージ理論の格子シミュレーションにおいて、連続極限でトポロジカルなサンプリングが困難になる「トポロジカルな凍結」を解決するため、確率的正規化フロー(SNF)を用いた新しい手法が提案されました。
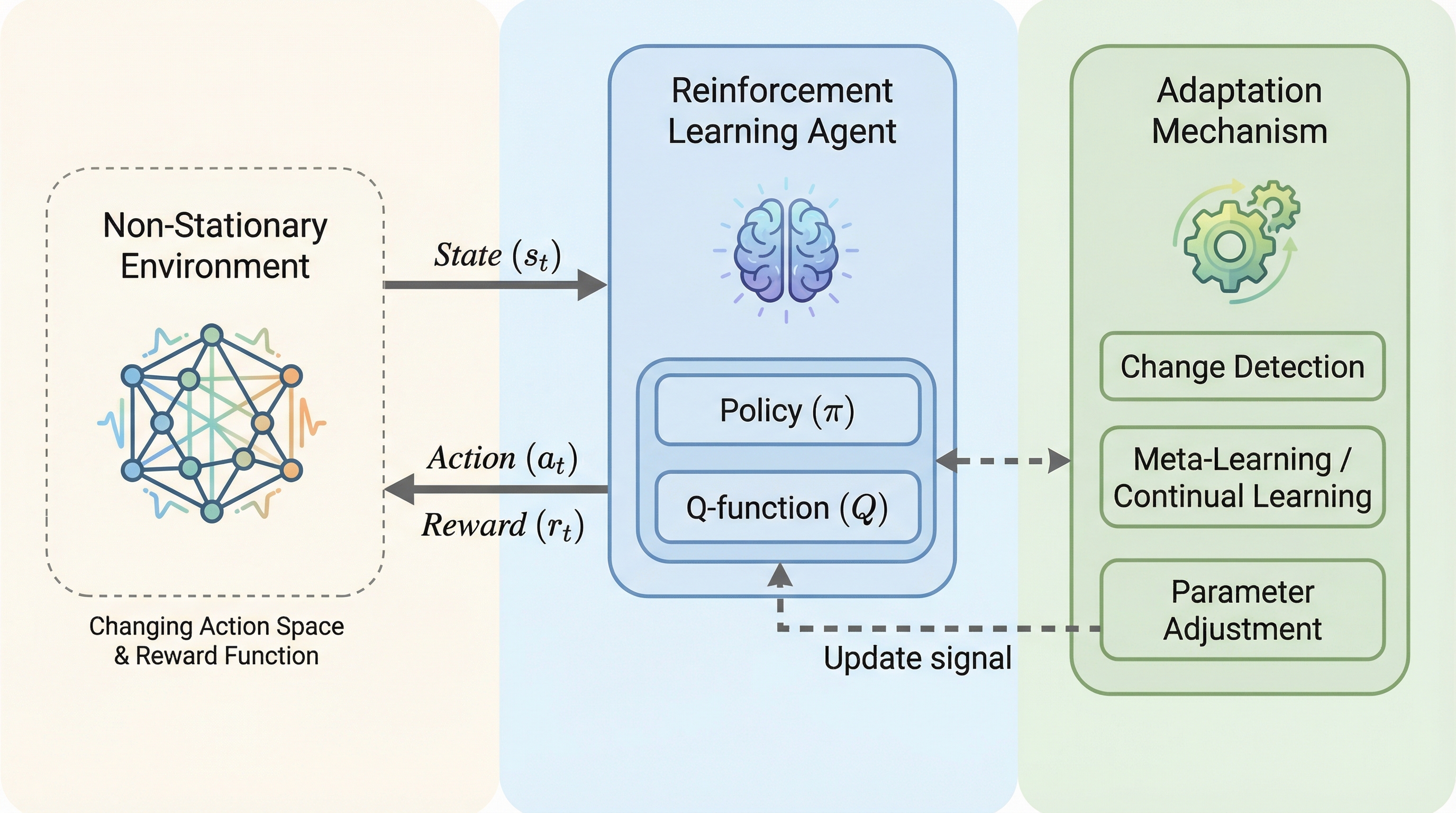
本研究は、報酬関数の変化や行動空間の拡大といった非定常な環境において、モデルを最初から再学習させることなくリアルタイムで適応可能な自己適応型強化学習フレームワーク「MORPHIN」を提案している。
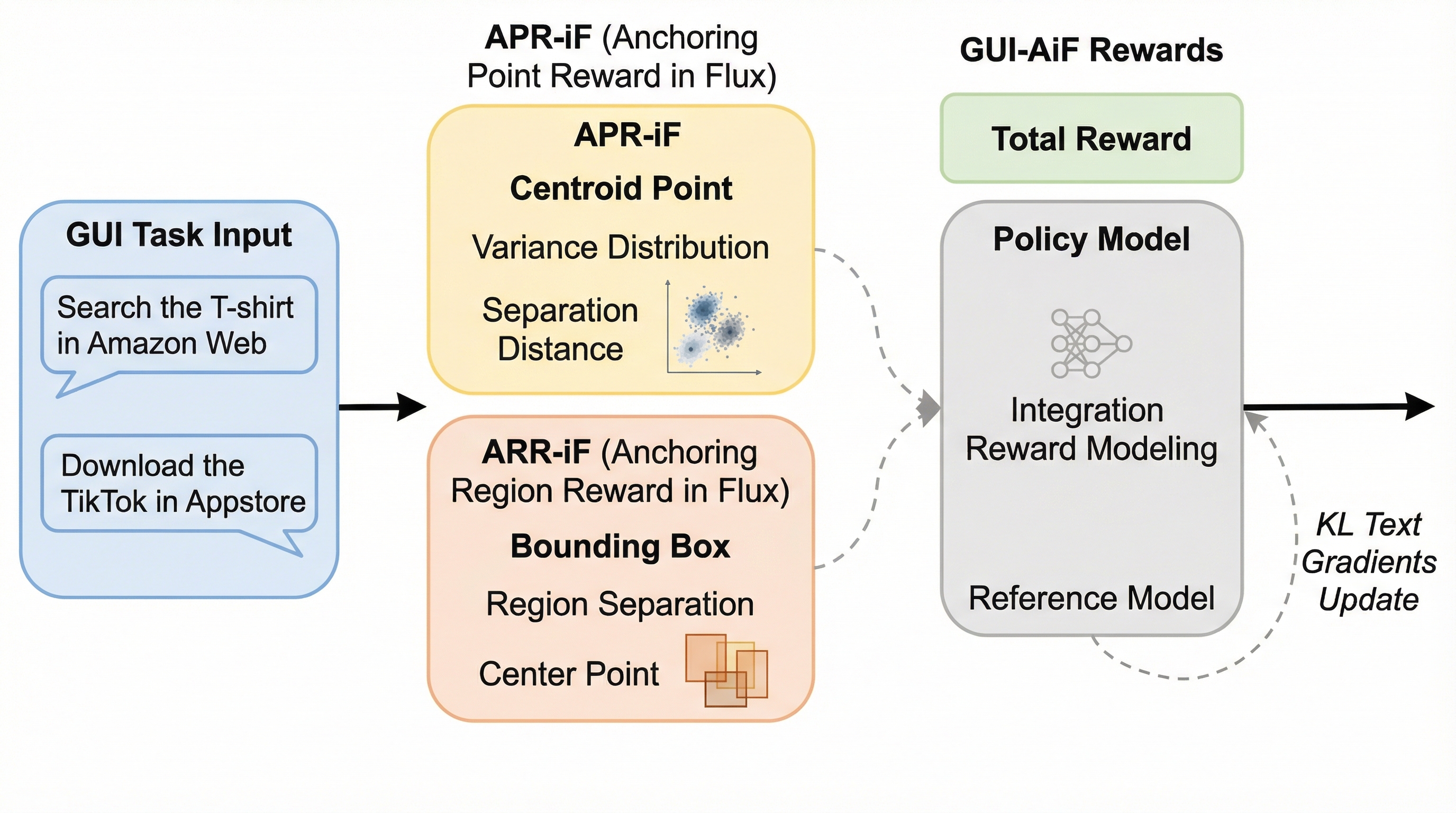
デジタル環境は新しいドメインや解像度の導入により常に変化しており、固定されたデータセットで学習した従来のGUIエージェントは性能が低下するという課題があります。 本研究では、変化する環境下で継続学習を行う「Continual GUI Agents」という新しいタスクと、多様な相互作用点と領域のアンカリングを強化する報酬枠組み「GUI-AiF」を提案しました。 検証の結果、提案手法はScreenSpot-V1、V2、Proの各ベンチマークにおいて、既存の教師あり微調整や強化学習ベースの手法を上回る世界最高水準の性能を達成しました。
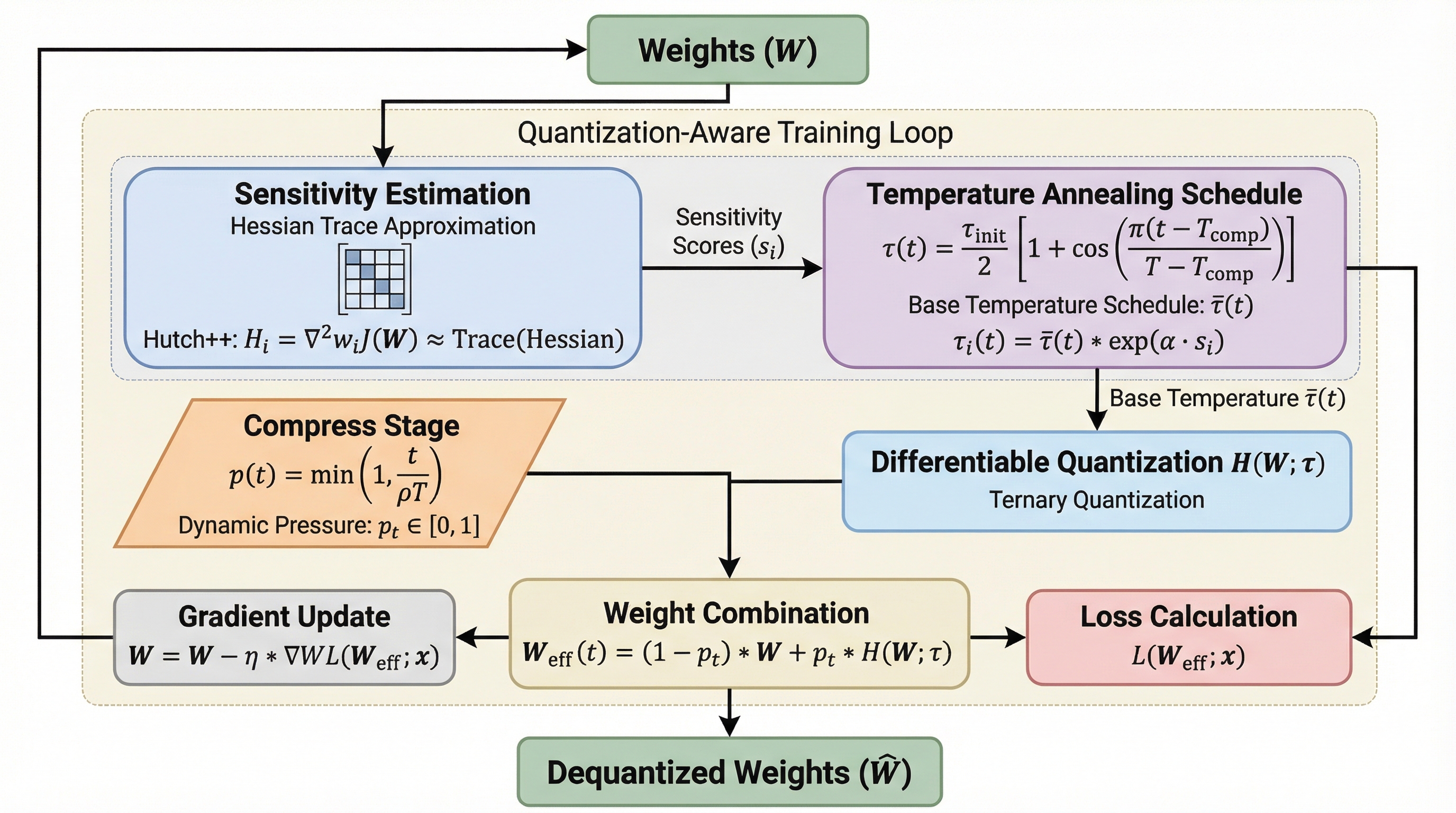
大規模言語モデル(LLM)のメモリ消費を抑えるため、重みを{-1, 0, 1}の3値に圧縮する1.58ビット量子化が注目されていますが、従来の量子化手法では硬い丸め処理による勾配の不一致や、重みの更新が停滞する「デッドゾーン問題」が性能向上の大きな障壁となっていました。
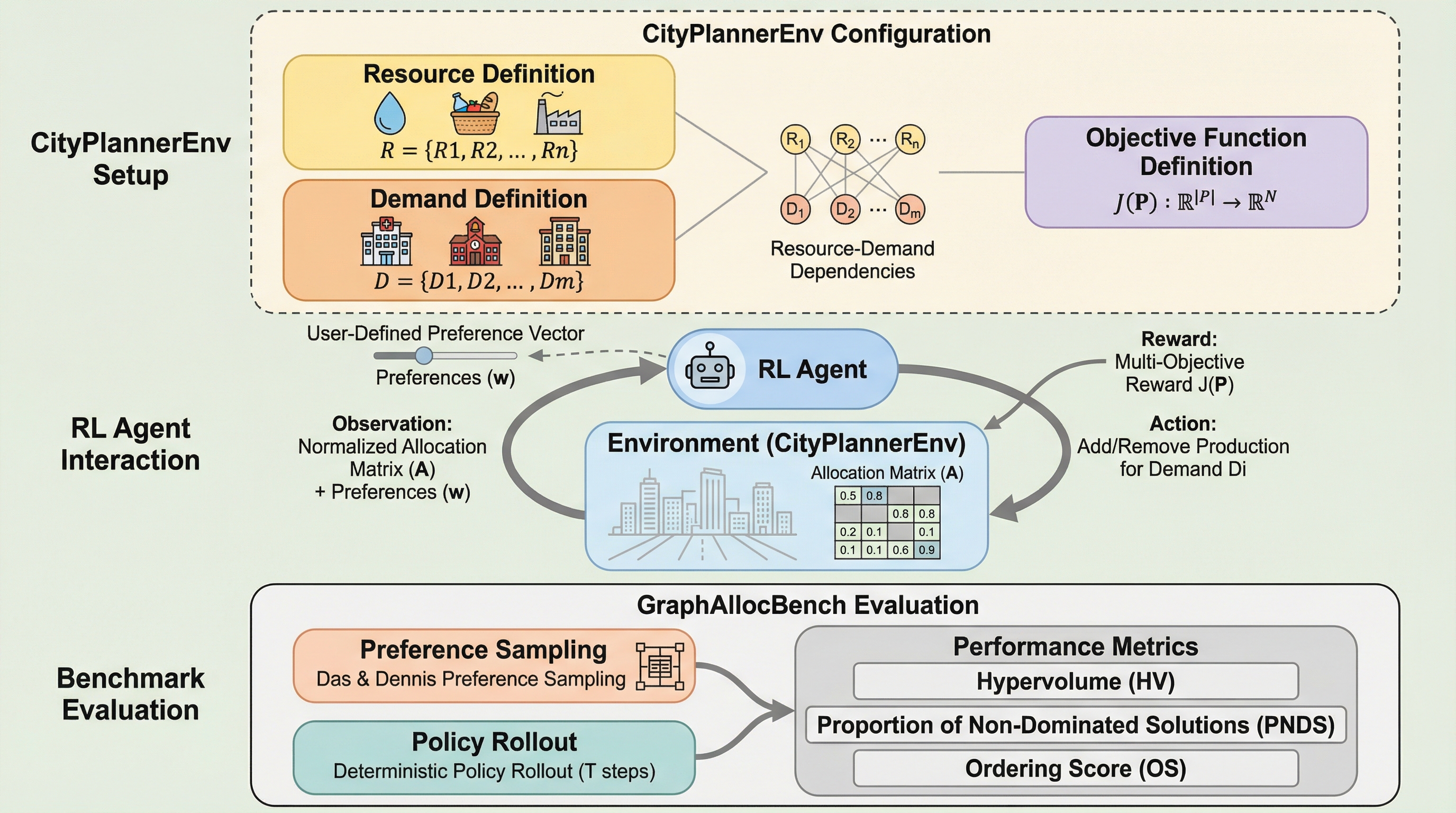
多目的強化学習における選好条件付き方策学習(PCPL)は、ユーザーが指定した目的間の選好(重み)に基づいて、単一のモデルで多様なパレート最適解を近似することを目指す手法であり、実行時に任意のトレードオフへ柔軟に適応できる利点を持つ。
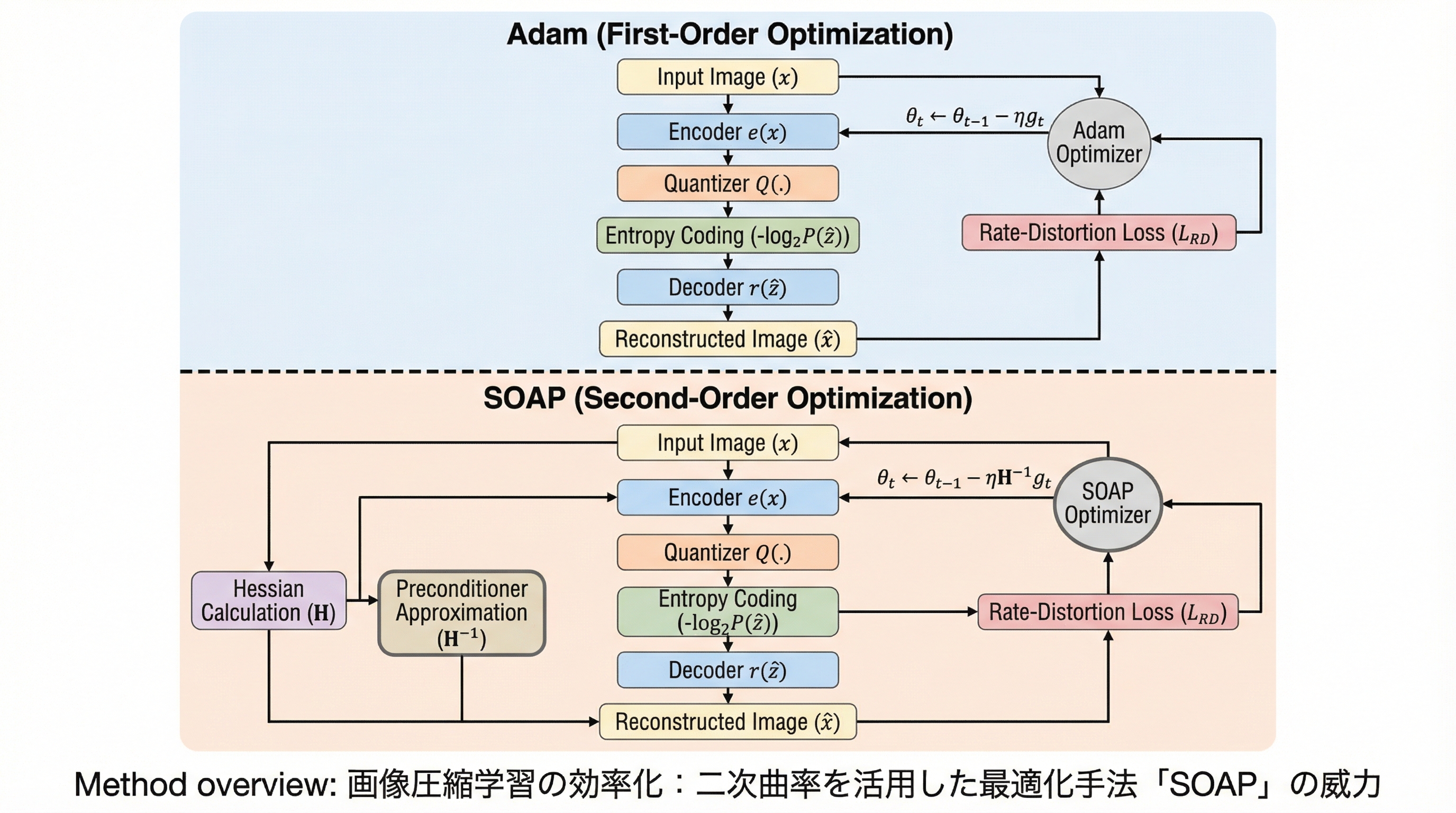
学習ベースの画像圧縮(LIC)モデルの訓練において、ビットレート削減と歪み最小化という相反する目的が引き起こす「勾配の衝突」を解決するため、二次曲率情報を活用する準ニュートン最適化手法「SOAP」を導入した。
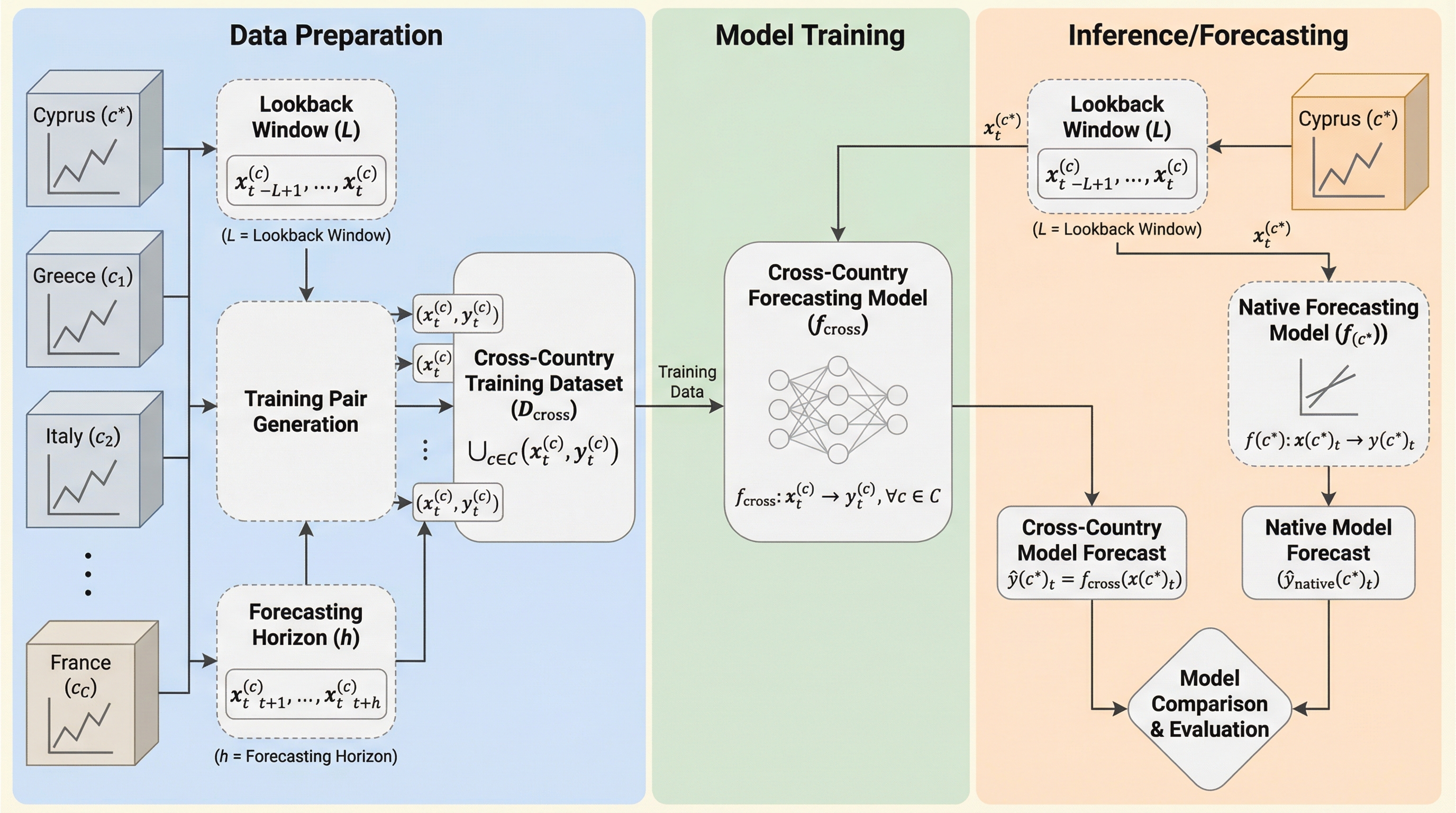
感染症予測において、単一国のデータのみでは学習サンプルが不足し精度が制限されるが、欧州諸国のデータを統合して学習する「クロス・カントリー学習」により、共通の疫学的動態を活用して予測精度を大幅に向上させることが可能である。