構造的には人間的、意味的にはバイアス的:埋め込みとGNNを用いたLLM生成リファレンスの検出
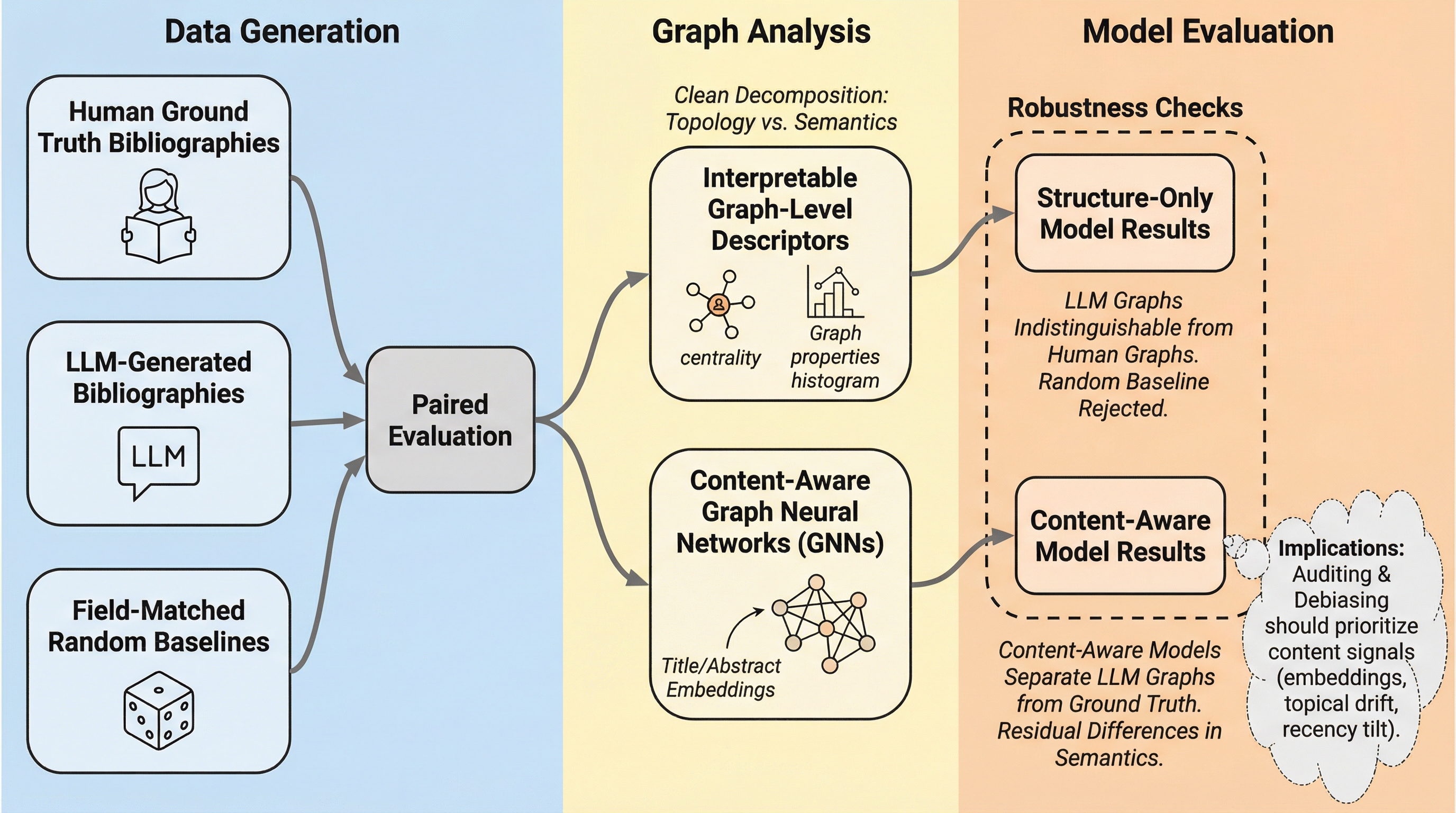
大規模言語モデル(LLM)が生成する参考文献リストは、引用ネットワークの構造的側面(中心性やクラスター係数など)において人間が作成したものと極めて高い類似性を持っており、従来のグラフ解析のみでは識別が困難であることが判明しました。
TL;DR(結論)
大規模言語モデル(LLM)が生成する参考文献リストは、引用ネットワークの構造的側面(中心性やクラスター係数など)において人間が作成したものと極めて高い類似性を持っており、従来のグラフ解析のみでは識別が困難であることが判明しました。一方で、論文タイトルの意味的な埋め込み表現を解析すると、LLM特有の「指紋」とも呼べる独自のバイアス(有名な論文や新しい論文を過度に好む傾向など)が検出可能であり、これを利用することで高い精度での識別が可能になることが本研究で示されました。 グラフニューラルネットワーク(GNN)に構造情報と意味情報を統合して学習させた結果、人間とLLMの文献リストを93%という高い精度で区別できることが、SciSciNetから抽出した1万件の論文データを用いた検証で明らかになりました。この結果は、LLMが科学的知識の構造を高度に模倣しつつも、内容の選択パターンにおいて非人間的な偏りを残していることを示唆しており、将来的な学術コンテンツの真偽判定やデバイアス技術の確立に向けた重要な指針となります。 本研究は、単一の引用の正誤を判定する従来のファクトチェックを超え、文献リスト全体の構造的なまとまりや意味的な凝集性に着目することで、LLMが科学的知識をどのように内面化し再構成しているかを解明しました。
なぜこの問題か
近年、大規模言語モデル(LLM)は科学的な知識を統合し、文献レビューを自動で草稿する能力を急速に高めています。しかし、LLMが生成する文献リストが、学術的な知識の基盤となる引用行動の構造的・意味的な規則性をどの程度再現できているのかという点は、これまで十分に解明されていませんでした。既存の研究では、LLMが生成する参考文献は一見するともっともらしく見えるものの、意味的な信頼性に欠ける場合があることが指摘されています。もしLLMが生成する文献リストが人間によるものと区別がつかないほど精緻であれば、自動化された文献調査ツールの信頼性は向上しますが、同時に既存のバイアスを強化したり、誤った情報を拡散したりするリスクも孕んでいます。特に、LLMが外部データベースにアクセスせず、自身のパラメータ内に蓄積された知識のみから文献を提案する場合、その選択には特有の偏りが生じる可能性があります。…
核心:何を提案したのか
本研究は、LLMが生成した参考文献リストを検出するための、解釈可能な特徴量から深層学習モデルに至るまでの段階的なモデリング戦略を提案しています。具体的には、SciSciNetデータベースから抽出した1万件の焦点論文(約27万5千件の引用を含む)を対象に、人間による引用グラフと、GPT-4oによって生成された引用グラフを対比させる大規模な実験フレームワークを構築しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related