線形関数近似を用いた外生的MDPにおいて純粋な活用だけで十分か?
外生的MDP(Exo-MDP)は、需要や価格などの外部要因が意思決定者の行動に依存せず進化するモデルであり、本研究は探索を一切行わない「純粋な活用(Pure Exploitation)」のみで理論的に最適な学習が可能であることを初めて証明しました。
TL;DR(結論)
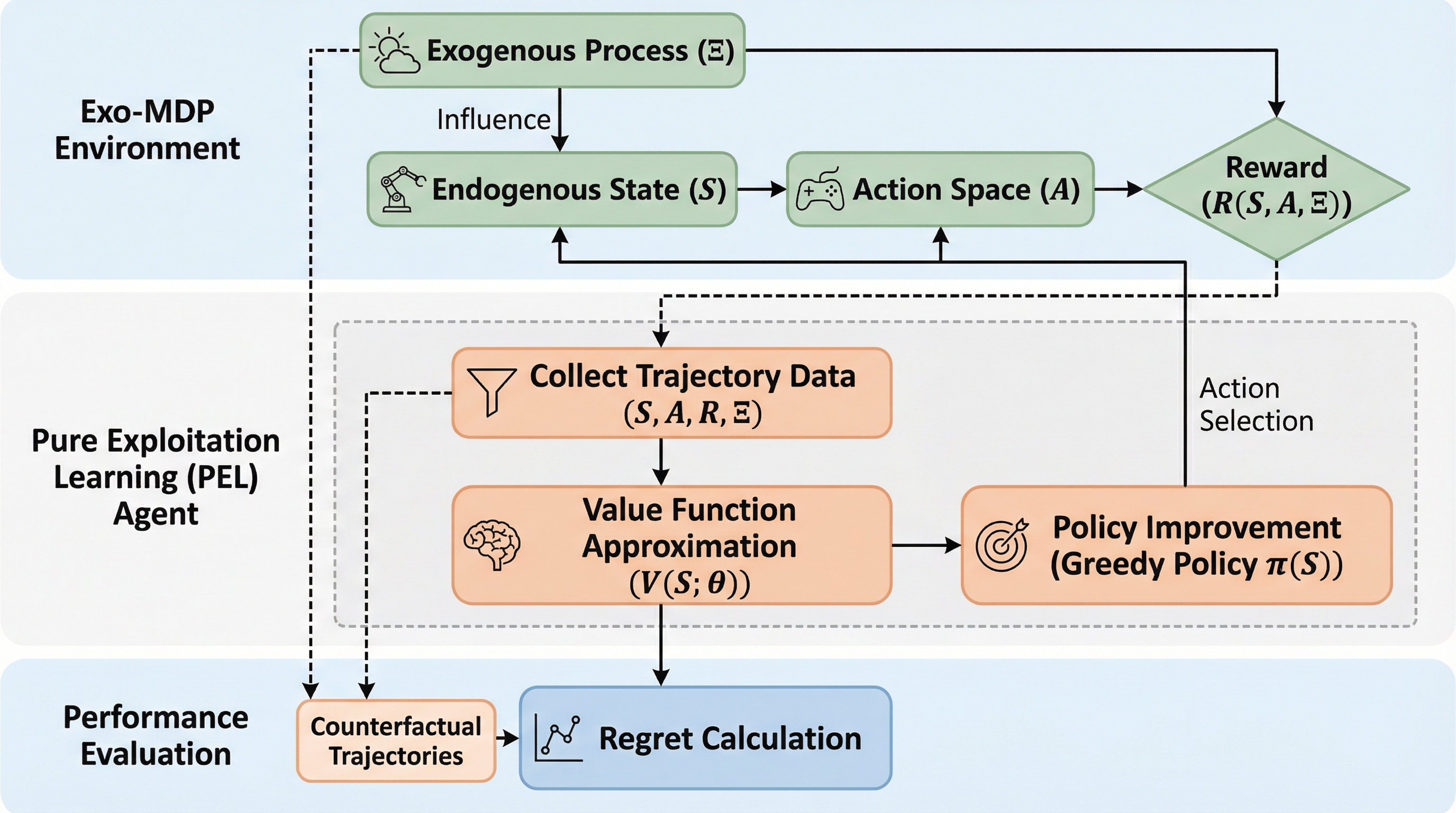
外生的MDP(Exo-MDP)は、需要や価格などの外部要因が意思決定者の行動に依存せず進化するモデルであり、本研究は探索を一切行わない「純粋な活用(Pure Exploitation)」のみで理論的に最適な学習が可能であることを初めて証明しました。 大規模な連続状態空間に対応するため、線形関数近似を用いた新手法「LSVI-PE」を提案し、過去の外部データの履歴を再利用する反事実的軌道の概念を導入することで、内生的な状態空間の大きさに依存しない効率的な後悔最小化を実現しました。 これにより、実務で広く使われている「探索なしの貪欲な手法」に強固な理論的裏付けを与え、システムの内部構造が既知であれば、複雑な探索アルゴリズムや楽観的なバイアスを追加せずとも効率的に最適方策へ収束することを示しました。
なぜこの問題か
現実世界の意思決定シーン、例えば在庫管理、エネルギー貯蔵、クラウド資源管理、サプライチェーンといった分野では、不確実性の大部分が外部要因に起因しています。具体的には、商品の需要、荷物の到着、市場価格の変動などが挙げられますが、これらはエージェントがどのような行動を選択したとしても、その影響を受けて変化することはありません。このような構造を持つモデルは外生的MDP(Exo-MDP)と呼ばれ、状態がエージェントの行動によって変化する「内生的なシステム状態」と、行動から独立して進化する「外生的な入力」に明確に分離されるのが特徴です。 実務の現場では、探索を行わずに現在の推定値に基づいて最善と思われる行動を常に選択する「純粋な活用」の手法が、驚くほど高い性能を発揮することが長年観察されてきました。古典的な近似動的計画法(ADP)やオペレーションズ・リサーチ(OR)の技術は、意図的な探索を行わずに、実際に観測された軌道から価値関数を更新し続ける手法を大規模なシステムに展開しています。…
核心:何を提案したのか
本研究では、外生的MDPにおいて探索を一切行わない学習パラダイムである「純粋な活用学習(PEL: Pure Exploitation Learning)」を提案しました。PELは、各エピソードにおいて観測された軌道から経験的な価値関数を繰り返し構築し、その推定値に対して常に貪欲に行動を選択する手法の総称です。このパラダイムの核心は、外生的なプロセスがエージェントの行動から完全に独立して進化するという構造的特徴を最大限に活用することにあります。具体的には、一度得られた外生的なデータの履歴(トレース)は、どのような方策を採用した場合の結果であっても、偏りなく評価するための貴重な情報として再利用できるという点に着目しました。 これにより、未知の領域を調査するための意図的な探索行動をあえて行う必要がなくなります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related