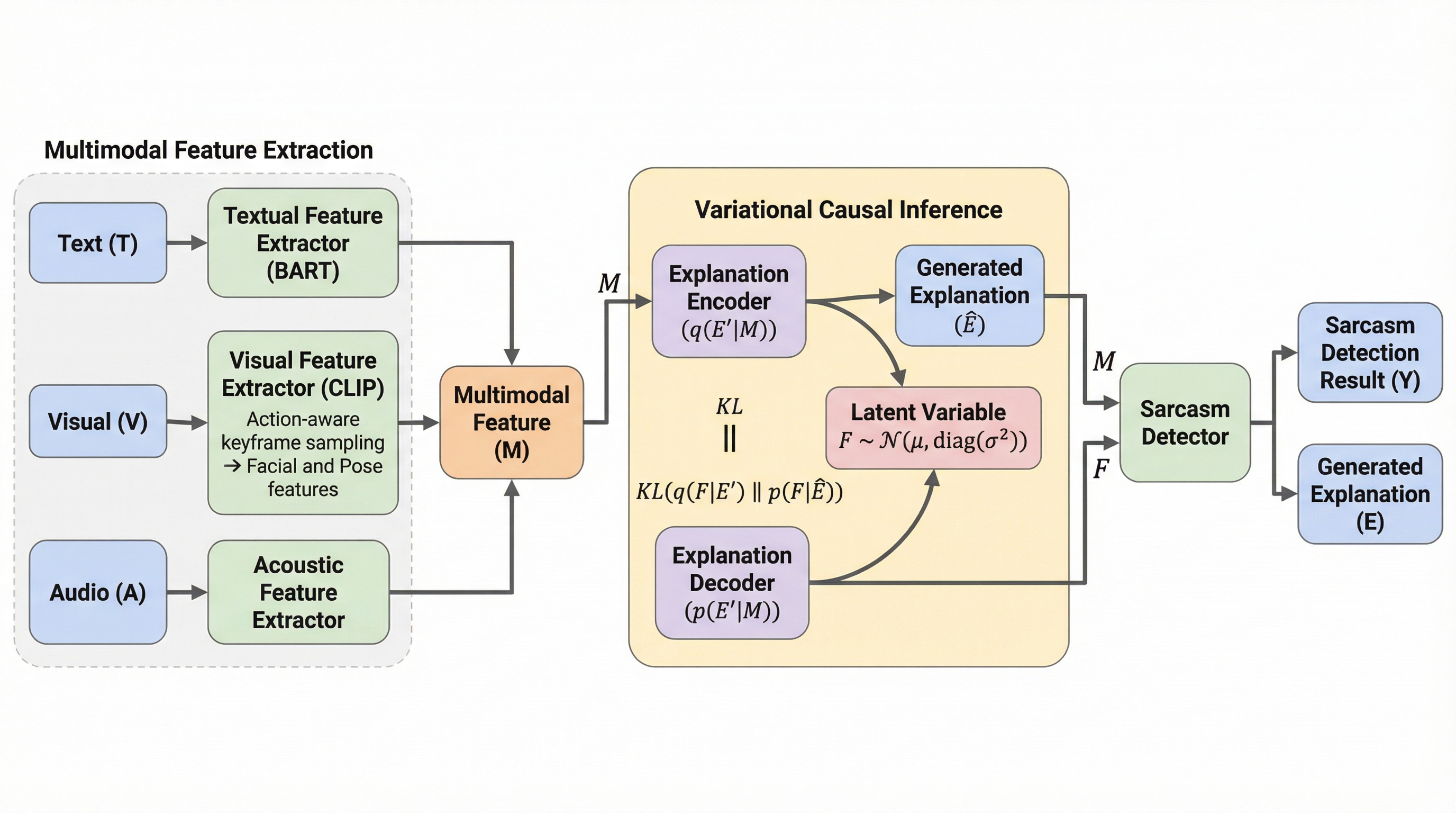
MuVaC:対話におけるマルチモーダルな皮肉理解のための変分因果フレームワーク
ソーシャルメディア上のマルチモーダルな対話における皮肉を理解するため、皮肉の検出(MSD)とその理由の説明(MuSE)を因果的な依存関係として捉える新しい変分因果推論フレームワーク「MuVaC」を提案した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
ソーシャルメディア上のマルチモーダルな対話における皮肉を理解するため、皮肉の検出(MSD)とその理由の説明(MuSE)を因果的な依存関係として捉える新しい変分因果推論フレームワーク「MuVaC」を提案した。
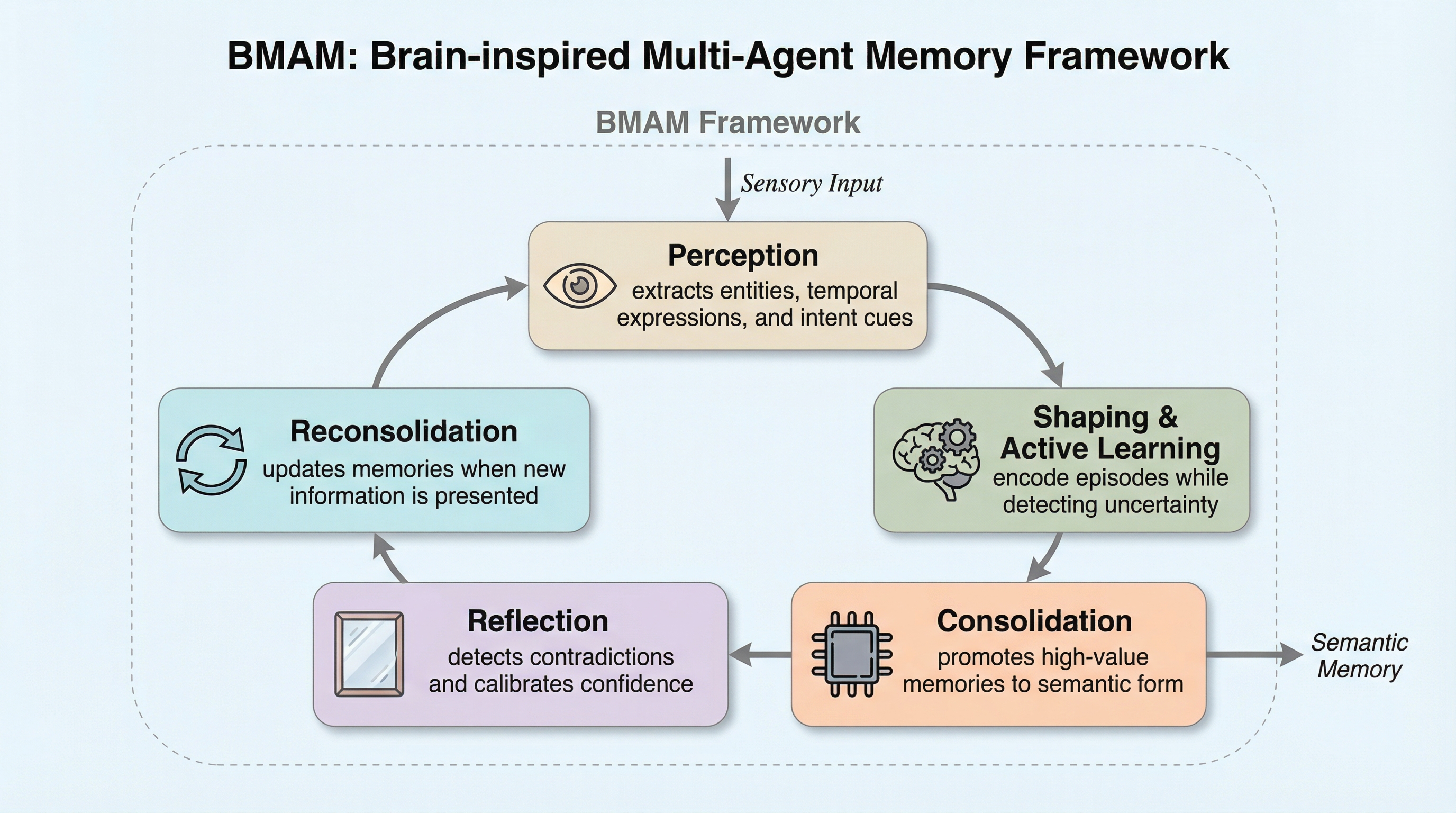
言語モデルベースのエージェントが長期間の対話で情報の整合性や個性を失う現象を「魂の摩耗(soul erosion)」と定義し、その解決策を提案している。 脳の記憶システムを模倣し、記憶をエピソード記憶、意味記憶、顕著性、制御といった機能的に分化されたサブシステムで構成する「BMAM」フレームワークを開発した。
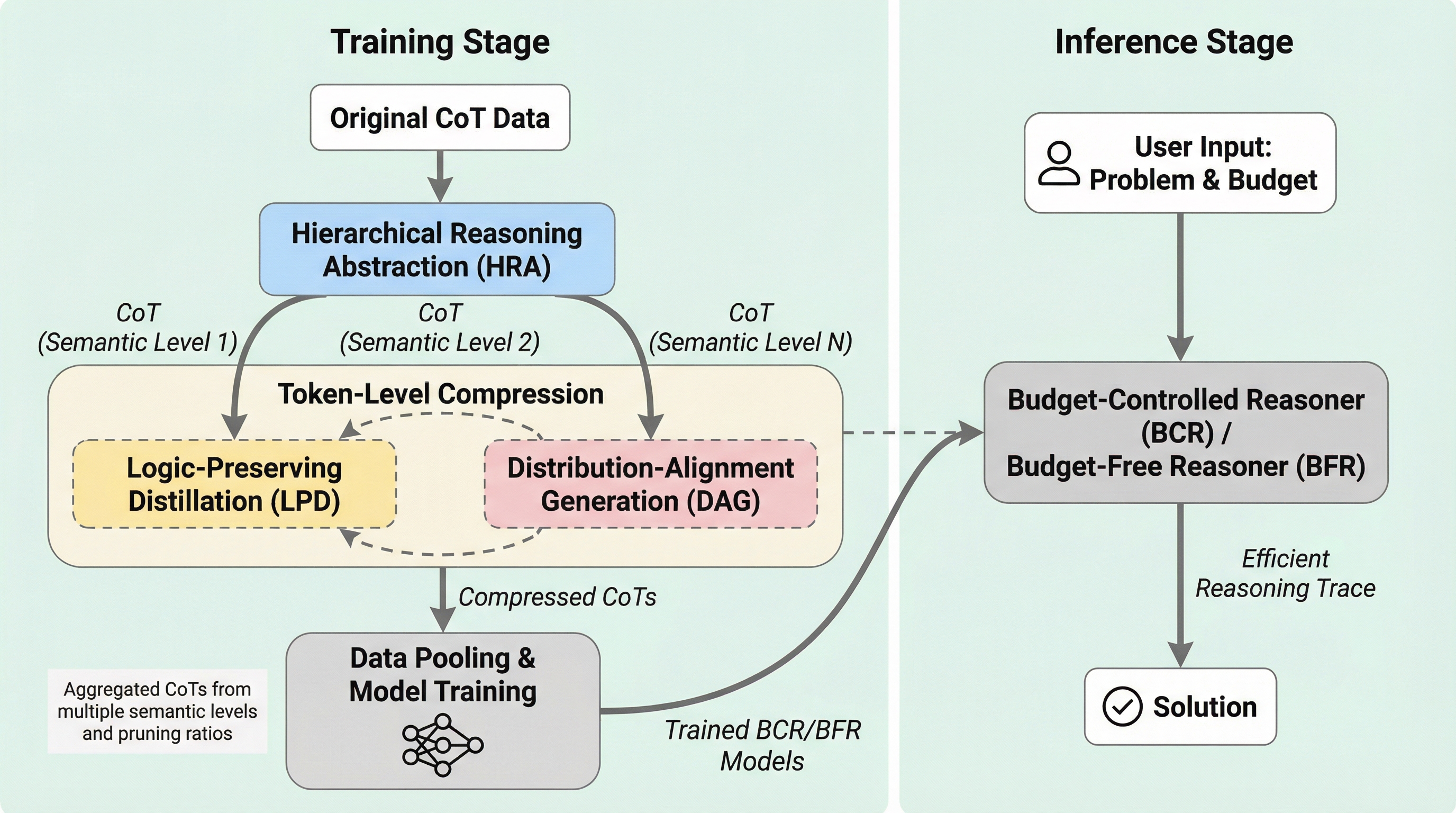
大規模言語モデルの思考の連鎖(CoT)における冗長性を排除するため、意味レベルの要約とトークンレベルの削減を統合した二重粒度フレームワーク「CtrlCoT」を提案し、推論精度を維持しながら計算コストを大幅に削減することに成功した。
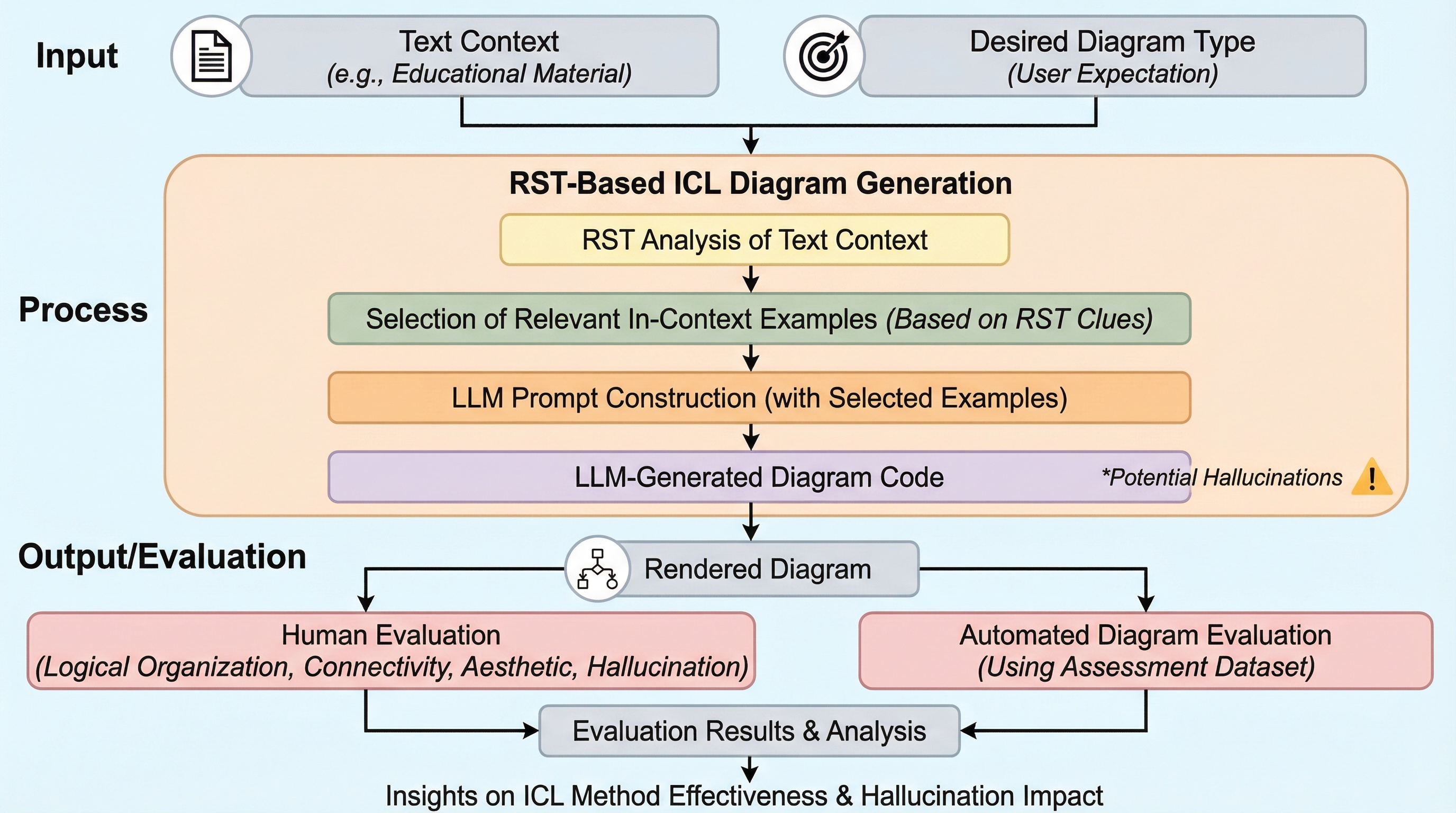
教育分野でのAI活用が進む中、図表生成におけるハルシネーションや不適切なレイアウトが学習者へのリスクとなっているため、修辞構造理論(RST)に基づいた新しい文脈内学習(ICL)手法が提案された。
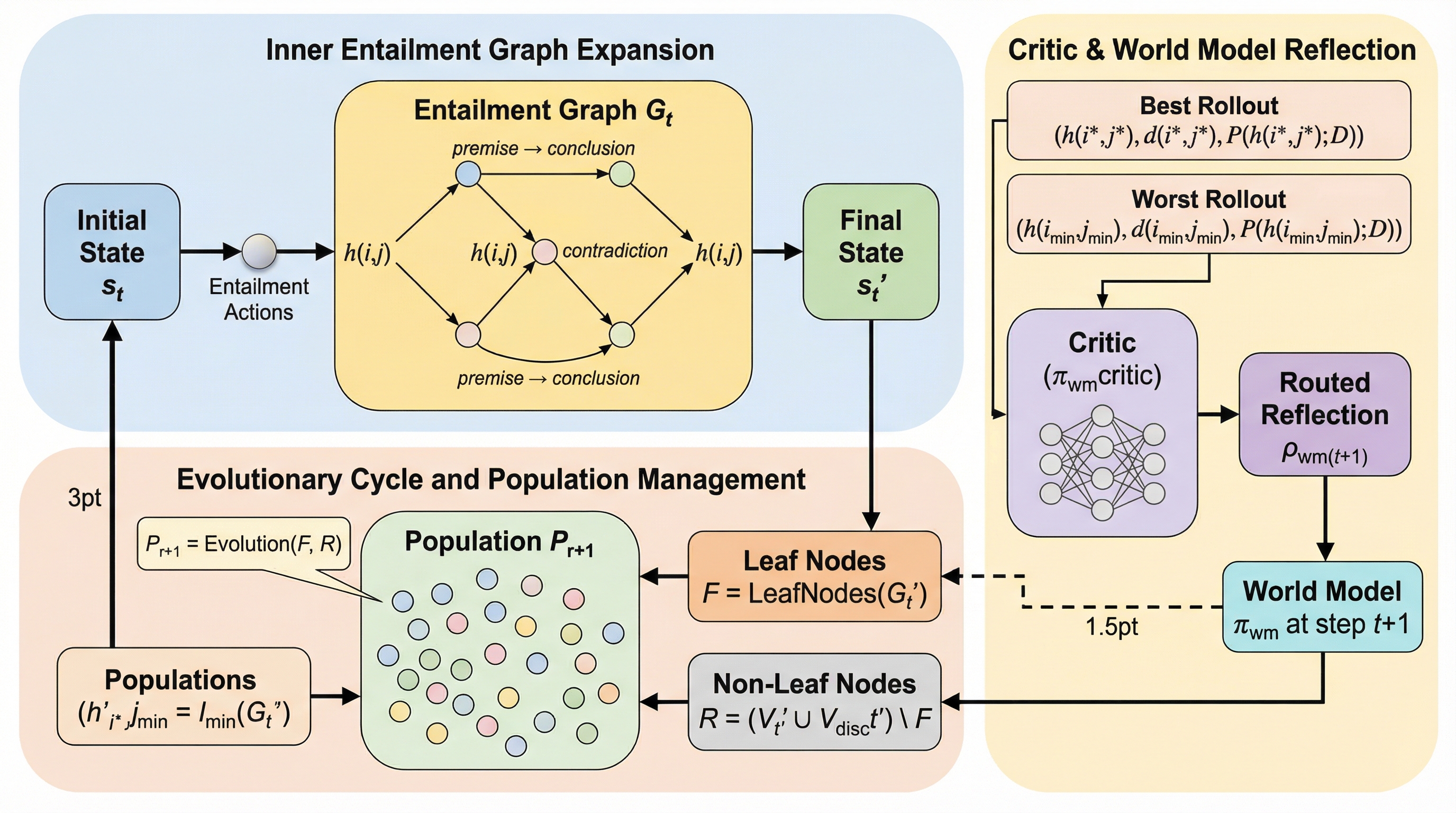
PathWiseは、組合せ最適化問題に対するヒューリスティック設計を、固定されたルールに基づく進化ではなく「帰結グラフ」を活用した逐次的な意思決定プロセスとして定式化する、新しいマルチエージェント推論フレームワークである。
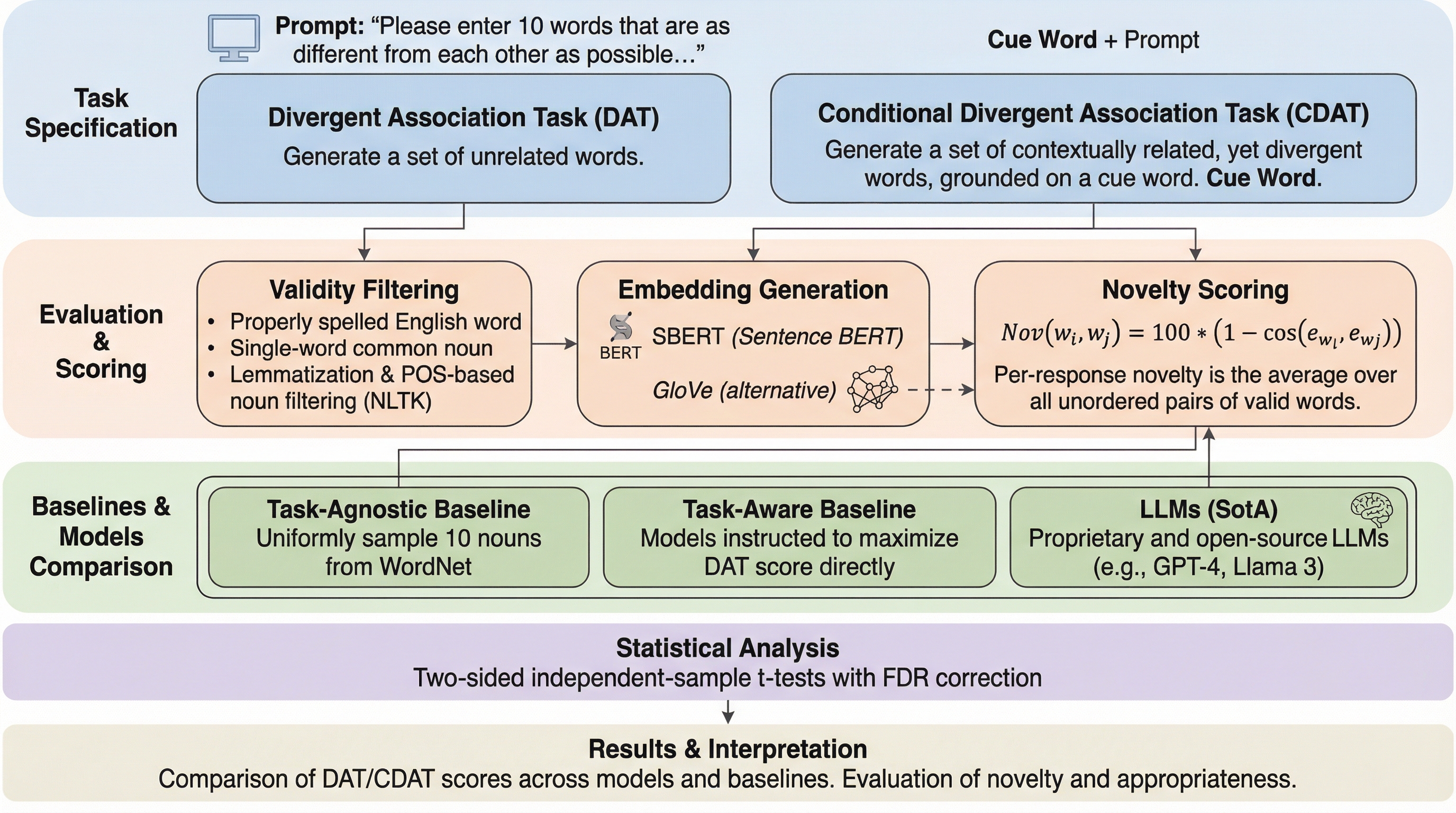
大規模言語モデルの創造性を評価する従来の指標であるDATは、単語間の意味的距離(新規性)のみを測定するため、ランダムな単語生成が最新モデルを上回るという妥当性の欠如が判明しました。本研究では、人間中心の創造性理論に基づき、新規性と文脈への適切性を両立させる新指標CDATを提案し、SBERTを用いた客観的な評価枠組みを構築することで、モデルの真の創造的能力を可視化しました。検証の結果、高度なモデルほど適切性を優先して新規性が低下する傾向があり、小規模なモデルの方が創造性のバランスに優れていることが明らかになり、学習やアライメントが創造性に与える影響が示唆されました。
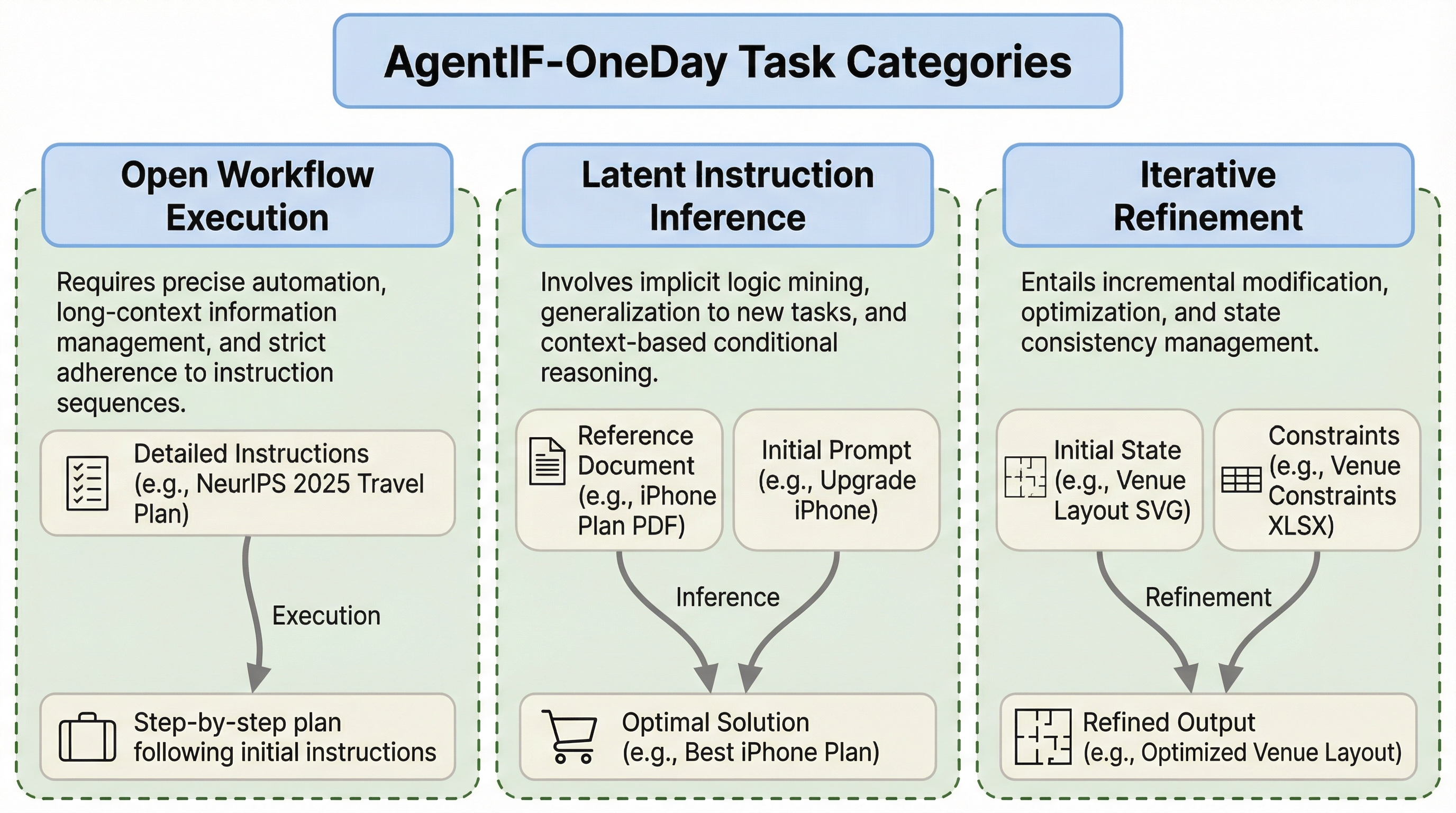
AgentIF-OneDayは、AIエージェントが一般ユーザーの日常生活、仕事、学習における多様なタスクをどの程度遂行できるかを評価するための新しいベンチマークであり、104の複雑なタスクと767の評価ポイントによって構成されています。
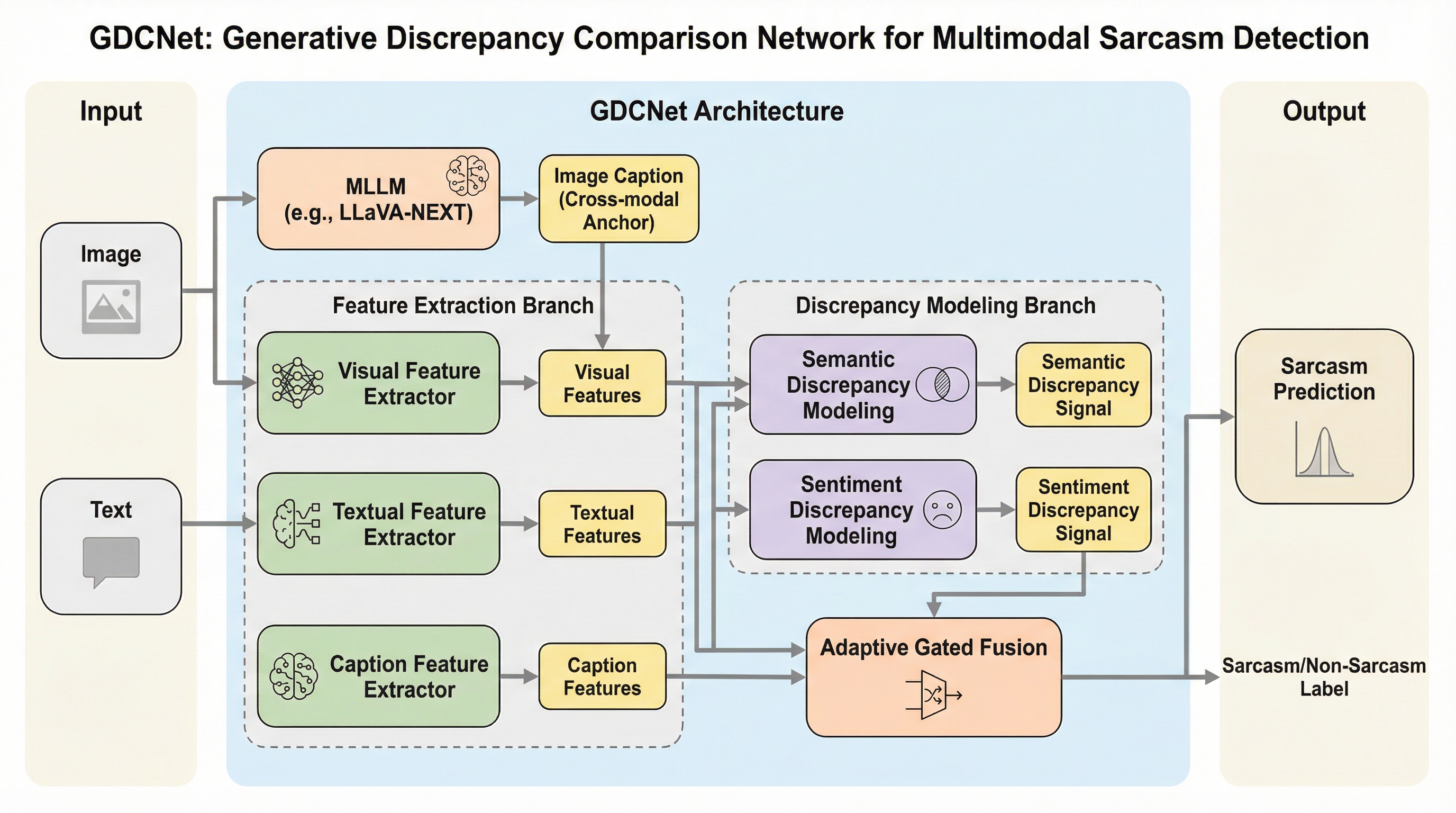
GDCNetは、画像とテキストのペアから皮肉を検出するために、マルチモーダル大規模言語モデル(MLLM)を「客観的な画像説明の生成器」として活用する新しいフレームワークである。従来のモデルがLLMに主観的な皮肉の理由を生成させていたのに対し、本手法は画像に基づいた事実的なキャプションを生成し、それを安定したセマンティック・アンカー(意味の指標)として活用することで、解釈の多様性によるノイズを抑制している。 このネットワークは、生成された客観的な画像説明と元のテキストとの間にある意味的な不一致、感情的な不一致、および画像とテキストの忠実度を測定する「生成的差異表現モジュール(GDRM)」を備えている。これにより、画像とテキストの間の微妙な矛盾や、文字通りの意味と意図された意味の乖離を、多角的な差異特徴として抽出することが可能になり、皮肉特有の複雑な不一致を捉えることができる。 大規模なベンチマークであるMMSD2.0を用いた実験において、GDCNetは既存のマルチモーダル手法や、GPT-4oなどの最新モデルを用いた直接的な推論手法を大幅に上回る最高精度を達成した。適応的なゲート付き融合メカニズムを導入することで、画像、テキスト、および差異情報の各モダリティの寄与を動的にバランスさせ、特定の情報の偏りを防ぎながら、頑健な皮肉検出を実現している。
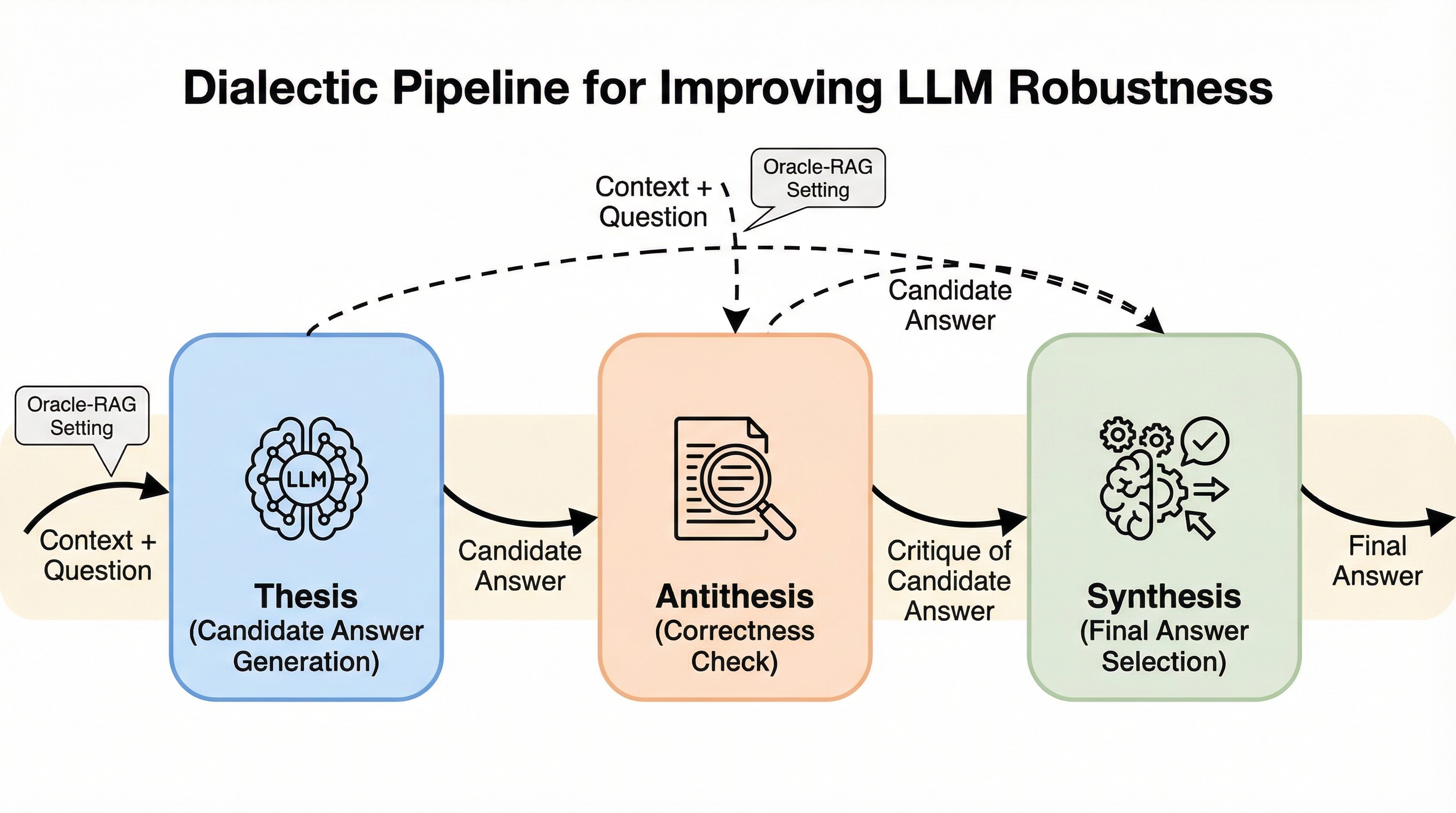
大規模言語モデル(LLM)の課題であるハルシネーションを抑制するため、ヘーゲル哲学の弁証法に着想を得た「対話的パイプライン(Dialectic Pipeline)」が提案されました。この手法は、モデルが「正(Thesis)」「反(Antithesis)」「合(Synthesis)」という3つの段階を経て自己対話を行うことで、初期の回答を批判的に検討し、最終的な結論を洗練させる仕組みです。 検証の結果、複数の知識源を統合する複雑なマルチホップ質問応答タスクにおいて、標準的な回答手法や既存の「思考の連鎖(Chain-of-Thought)」を大幅に上回る精度と信頼性を達成しました。また、外部知識を活用するRAG環境において、情報の要約や勾配ベースのフィルタリングを組み合わせることで、モデルの規模や種類を問わず回答の質がさらに向上することが確認されました。 本研究は、追加学習や特定のドメインへの特化を必要とせず、プロンプトの構造を工夫するだけでモデルの汎用性を維持したまま堅牢性を高められることを示しています。特に、推論能力と内容抽出能力の両方が求められる多段階の質問応答において、自己修正プロセスが極めて有効であることを実証し、実用的なフレームワークを提供しています。
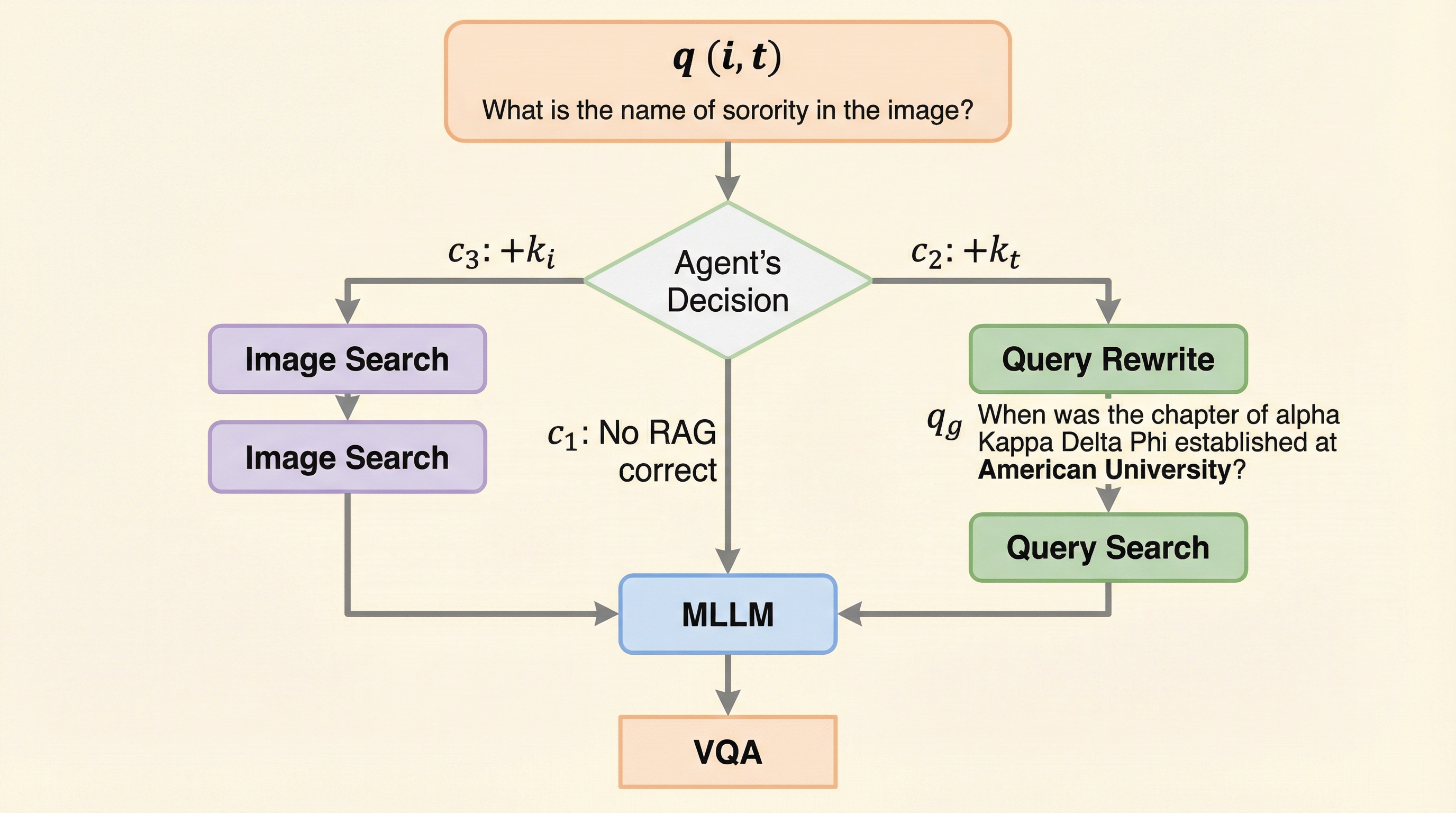
視覚的質問応答(VQA)におけるマルチモーダル検索拡張生成(mRAG)の非効率性を解消するため、画像検索やテキスト検索の必要性を動的に判断し、パイプラインを最適化する「マルチモーダル計画エージェント」を開発しました。