視覚的質問応答のための効率的なマルチモーダル計画エージェント
視覚的質問応答(VQA)におけるマルチモーダル検索拡張生成(mRAG)の非効率性を解消するため、画像検索やテキスト検索の必要性を動的に判断し、パイプラインを最適化する「マルチモーダル計画エージェント」を開発しました。
TL;DR(結論)
視覚的質問応答(VQA)におけるマルチモーダル検索拡張生成(mRAG)の非効率性を解消するため、画像検索やテキスト検索の必要性を動的に判断し、パイプラインを最適化する「マルチモーダル計画エージェント」を開発しました。 質問を「検索不要」「テキスト検索のみ」「画像検索のみ」「両方必要」という4つのカテゴリに分類し、モデルの内部知識で解決可能な場合は検索を省略、必要な場合のみ特定のステップを実行することで、従来の固定的な手法と比較して検索時間を60%以上短縮し、計算資源の浪費を大幅に抑制しました。 6つの多様なデータセットを用いた検証により、提案手法はDeep Researchエージェントなどの強力なベースラインを精度と速度の両面で上回り、特に複雑な知識を要する質問において高い回答性能と実用的な推論効率を両立できることを証明しました。
なぜこの問題か
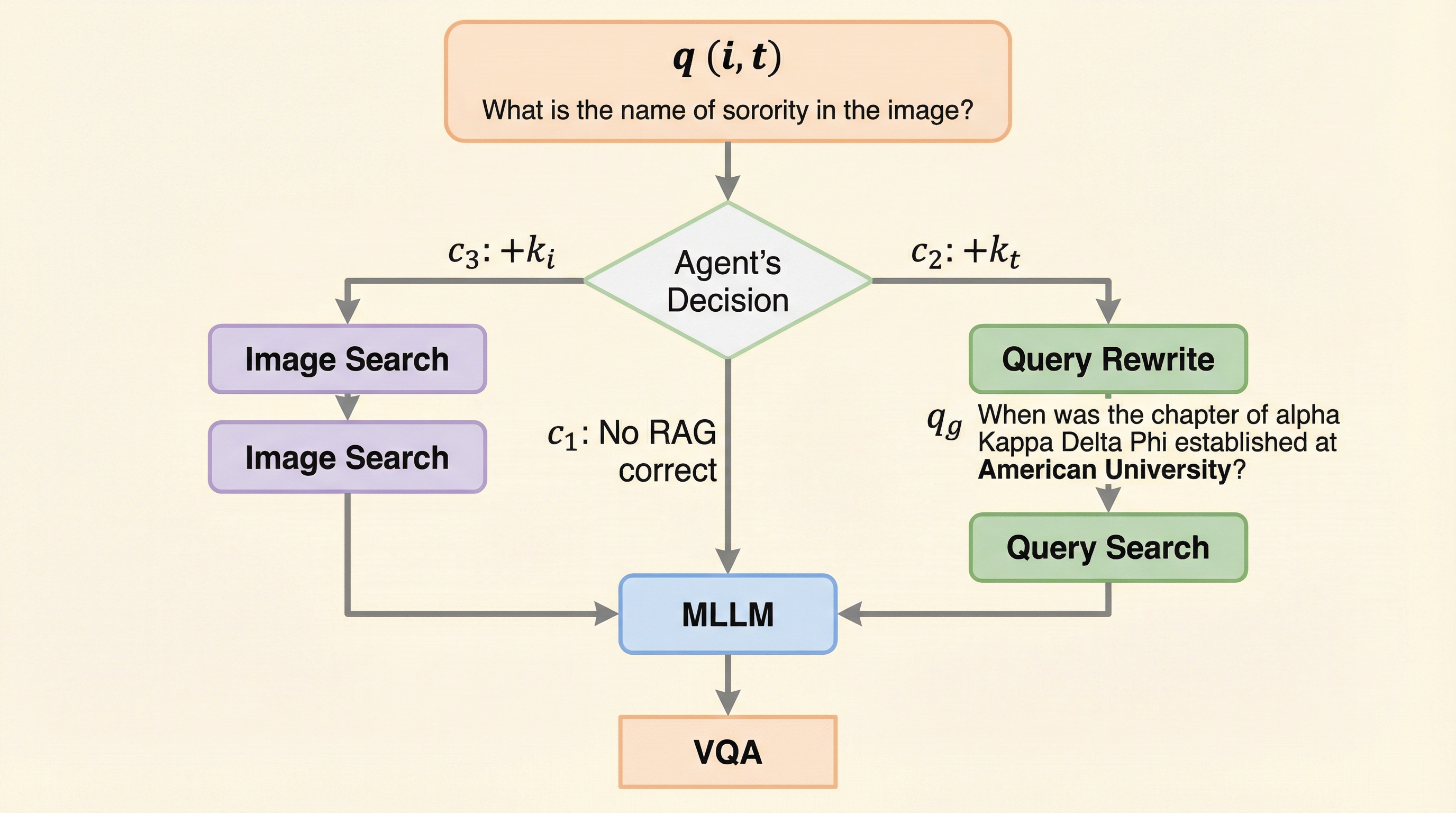
視覚的質問応答(VQA)は、画像とテキストの両方の情報を統合して正確な回答を生成する必要がある、マルチモーダル人工知能における基本的かつ困難な課題です。近年、外部の事実情報を必要とする知識集約型の質問や、時間の経過とともに回答が変化する動的な質問に対応するため、マルチモーダル検索拡張生成(mRAG)を用いたシステムが注目されています。しかし、既存のmRAGシステムには、実用的な効率性とスケーラビリティを制限する大きな課題が存在しています。現在の実装の多くは、画像のグラウンディング、画像検索、クエリの書き換え、そしてテキストパッセージの検索といった、固定された多段階のパイプラインを採用しています。これらのステップには固有の依存関係があり、例えば効果的なクエリの書き換えには画像内容に関する追加情報を提供する画像検索が事前に必要であり、テキスト検索はクエリの書き換えに依存しています。 このような静的なワークフローは、入力データの特性を考慮しないデータ非依存的なものであり、処理段階を動的に選択するメカニズムが欠如しているため、極めて非効率的です。…
核心:何を提案したのか
本論文では、VQAタスクにおけるmRAGパイプラインの効率を劇的に向上させるために、動的にワークフローを適応させる「マルチモーダル計画エージェント」を提案しています。このエージェントは、与えられたVQAクエリに対して、画像検索が必要か、テキスト検索が必要か、あるいはその両方か、もしくはどちらも不要かをインテリジェントに判断する役割を担います。具体的には、エージェントは4つの経路を選択することができます。第1の経路は、モデルの固有の能力で解決可能な単純なクエリに対して、外部処理を一切行わずに直接回答を生成するものです。第2および第3の経路は、外部知識や専門的なツールが必要な場合に、mRAGワークフローを戦略的に分解し、正確な回答生成に不可欠なコンポーネントのみを選択的に実行します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related