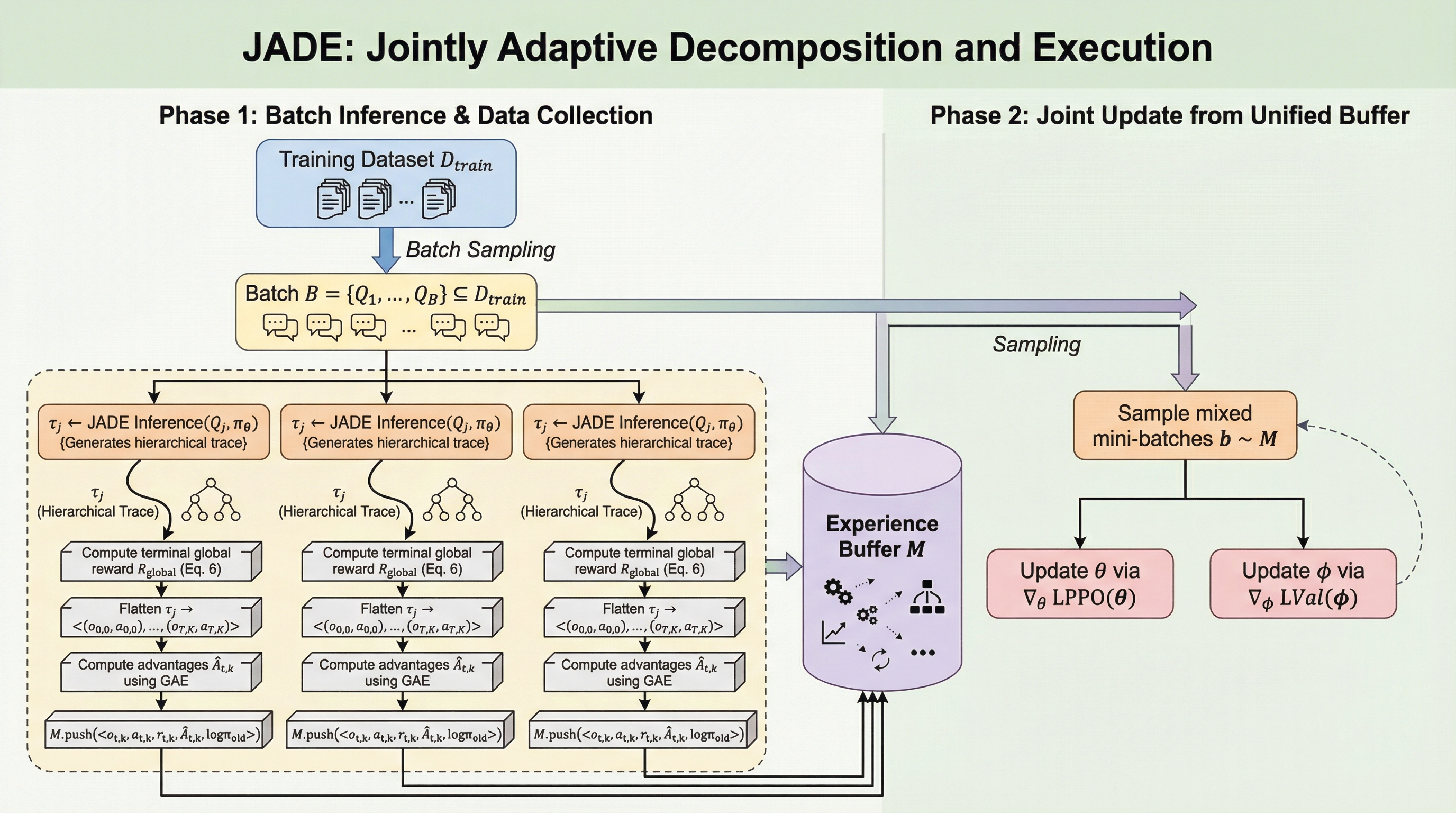
JADE: 動的なAgentic RAGにおける戦略と実行のギャップを埋める
従来の動的な検索拡張生成(RAG)システムでは、高度な計画を立案するプランナーと、実際のタスクを遂行する実行器が分離されていたため、計画が実行器の能力を超えたり、実行器が計画の意図を汲み取れなかったりする「戦略と実行のミスマッチ」が大きな課題となっていた。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来の動的な検索拡張生成(RAG)システムでは、高度な計画を立案するプランナーと、実際のタスクを遂行する実行器が分離されていたため、計画が実行器の能力を超えたり、実行器が計画の意図を汲み取れなかったりする「戦略と実行のミスマッチ」が大きな課題となっていた。
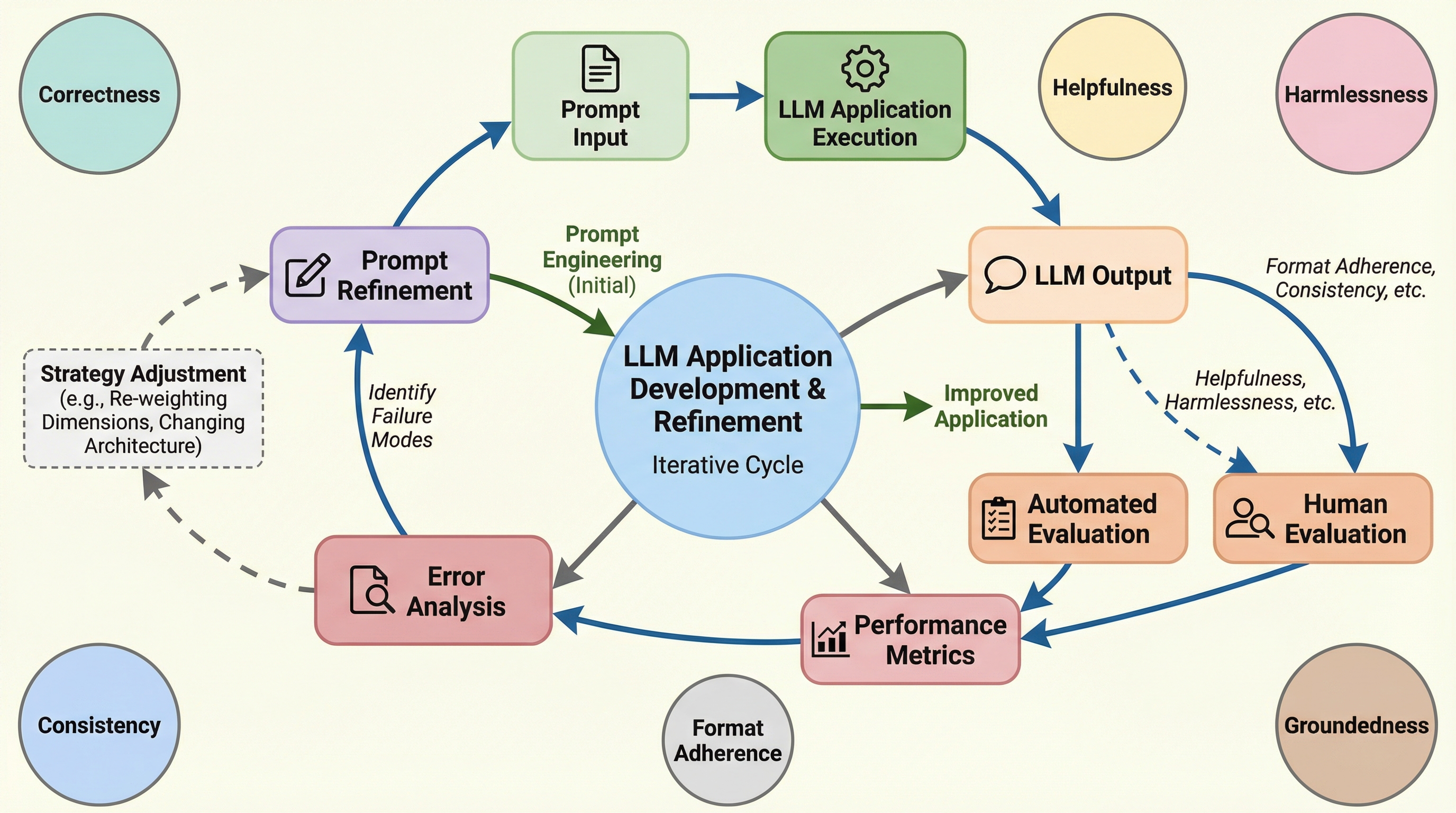
LLMの出力は非決定論的でモデル更新に敏感なため、従来の決定論的なテスト手法では不十分であり、「定義・テスト・診断・修正」の4フェーズからなる評価主導型の反復ワークフローを導入することで、場当たり的な調整から再現可能なエンジニアリングプロセスへの転換を提案する。
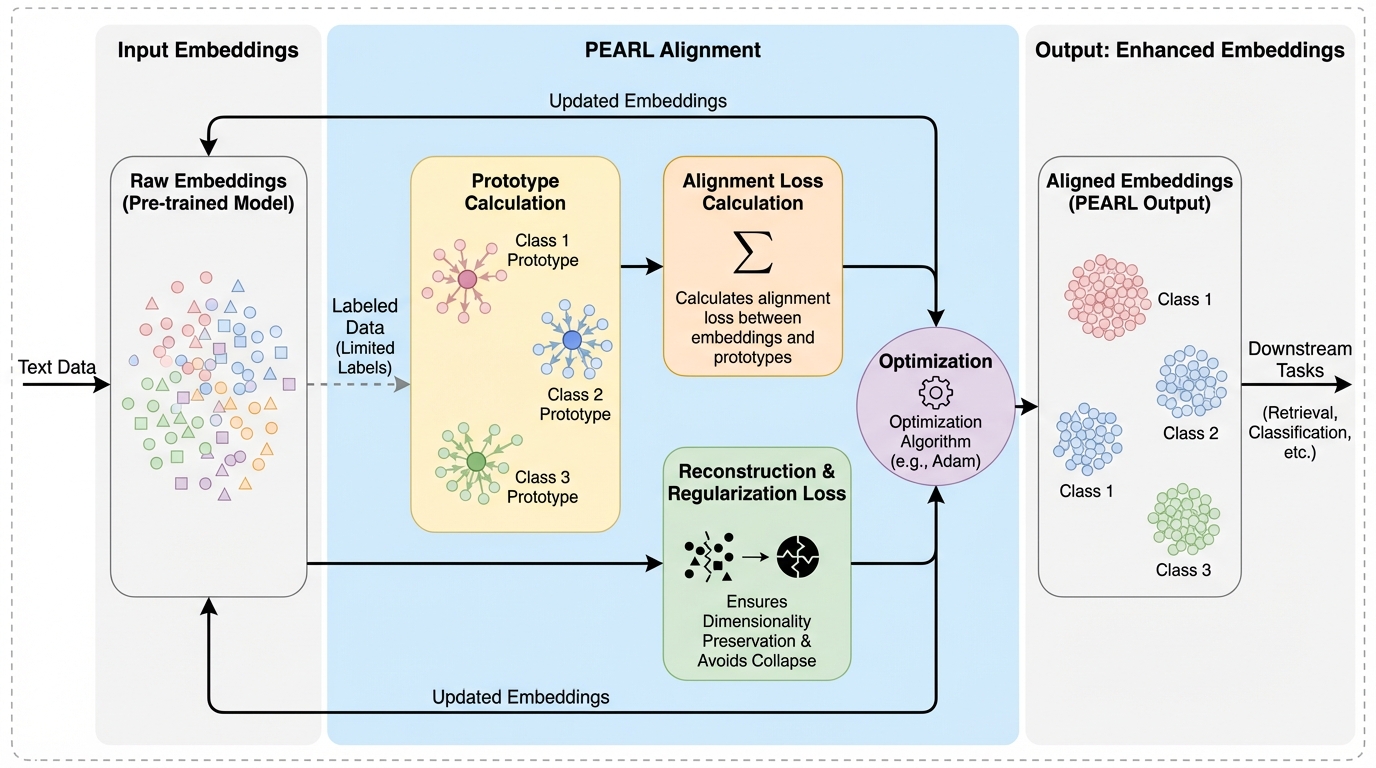
デジタルガバナンス等の実運用システムでは、固定された埋め込み表現の近傍構造が不正確で誤った事例を検索してしまう課題があるが、本研究が提案するPEARLは、限られたラベル情報を用いて埋め込みをクラスプロトタイプに軟らかく整列させることで、次元数を維持したまま近傍の幾何学的構造を劇的に改善する。
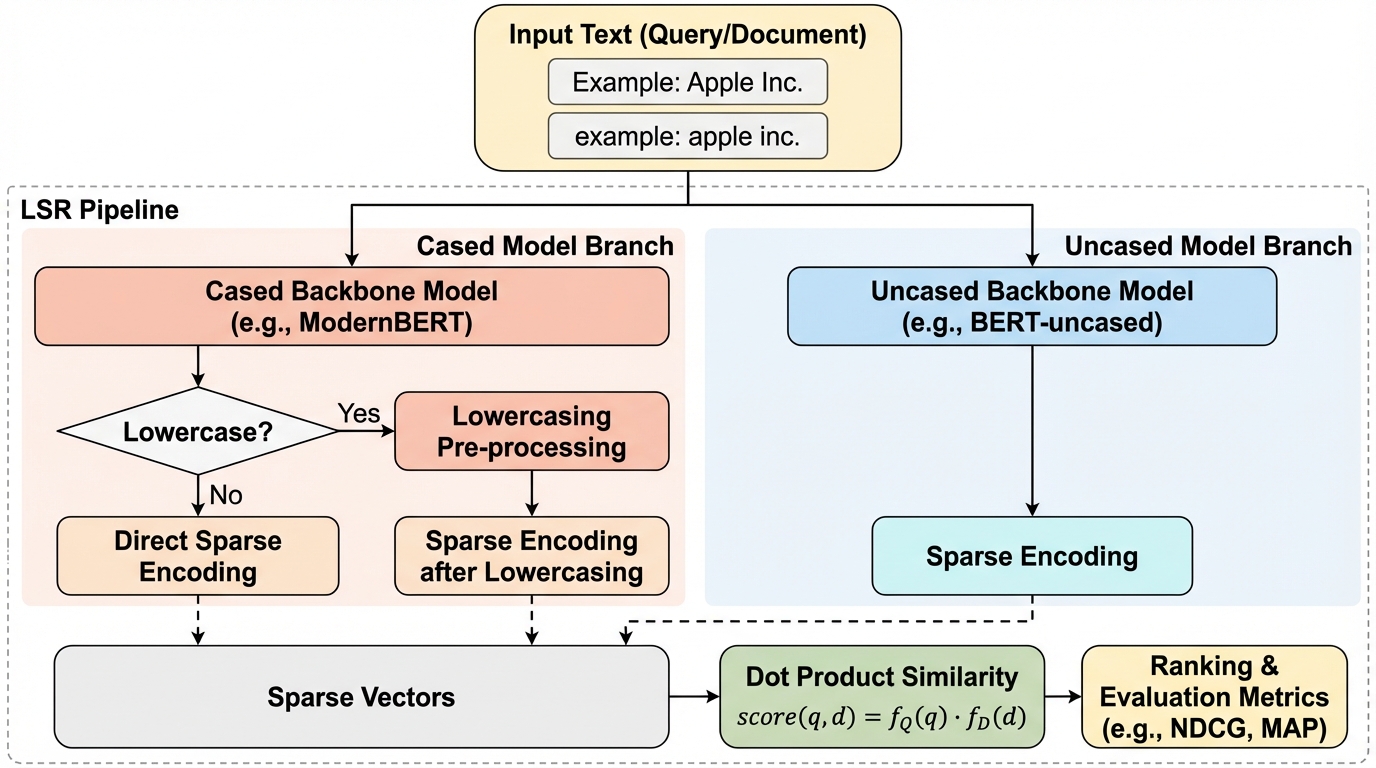
学習型スパース検索(LSR)において、従来主流だった小文字限定(uncased)モデルに対し、最新の言語モデルで一般的な大文字・小文字区別(cased)モデルが与える影響を調査した結果、標準状態では検索精度が大幅に低下することが判明した。
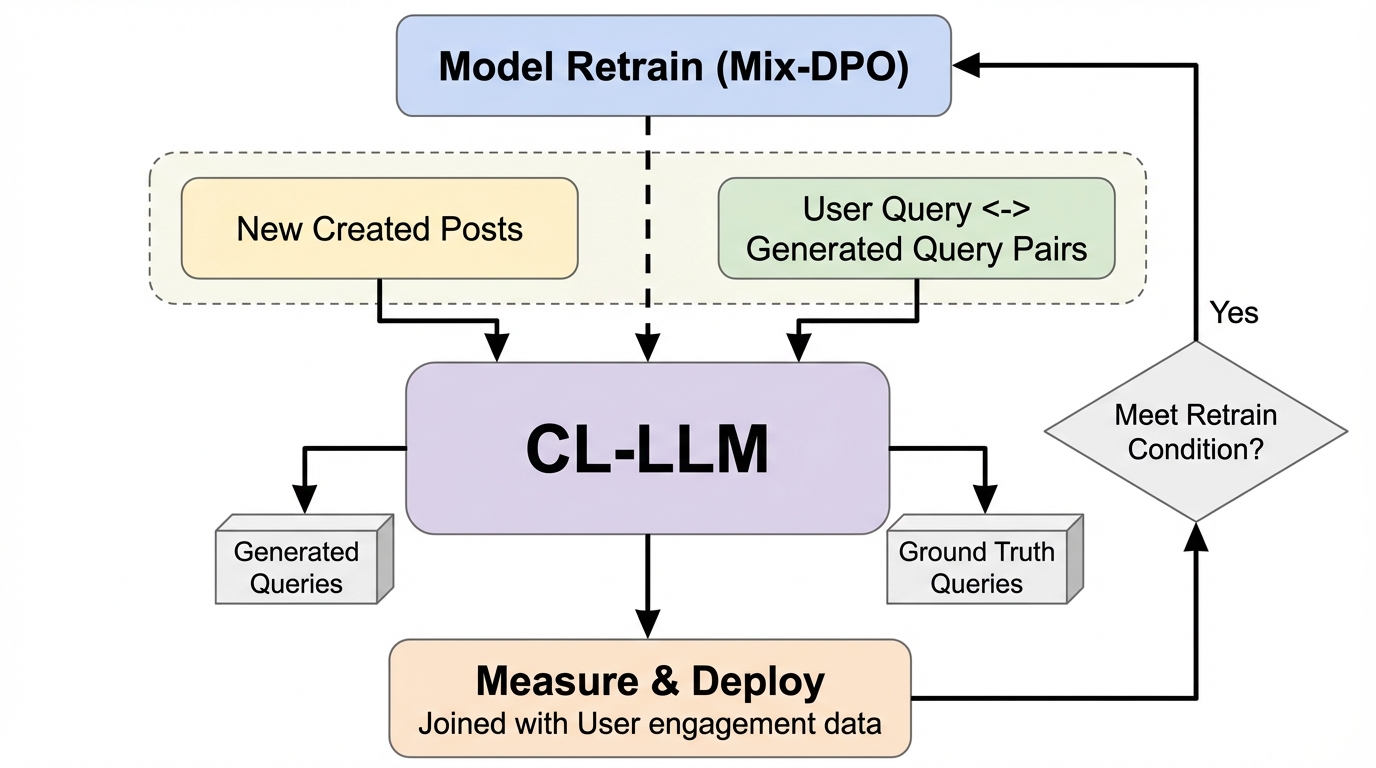
検索トラフィックが少ない環境では、従来のクエリ量に基づくトレンド検出が困難であるため、投稿内容から直接検索クエリを生成して合成シグナルを作るRTTPフレームワークが提案されました。 このシステムは、継続学習型の大規模言語モデル(CL-LLM)と、新旧のデータを適切に混合して学習させるMix-Policy DPOという新しい最適化手法を採用しており、モデルの知的な推論能力を維持しながら最新の話題に適応し続けることが可能です。 FacebookやMeta AIの製品規模で導入された結果、トレンド検出の精度が相対的に91.4%向上し、クエリ生成の正確性も従来手法より19%改善しており、ユーザーが検索を開始する前の極めて早い段階でトレンドを予測できることが実証されました。
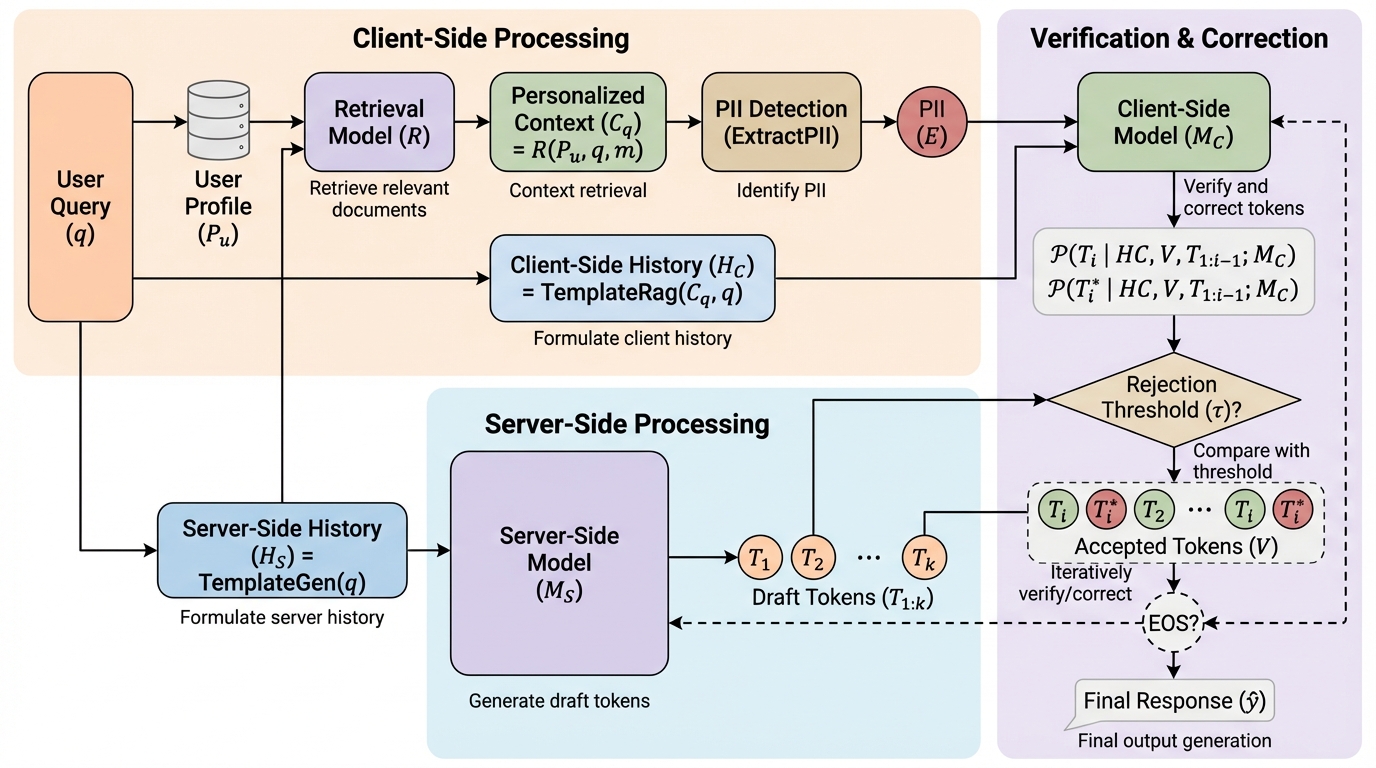
大規模言語モデル(LLM)のパーソナライズにおいて、ユーザーの機密情報をクラウドサーバーに一切開示することなく、高品質な回答を生成するための新しい対話型フレームワーク「P3」が提案されました。 この手法は、サーバー側の強力なモデルが回答候補を生成し、ユーザー手元の小規模モデルが個人のプロフィールに基づき内容を検証・修正する「推測、検証、修正」のプロセスを繰り返すことで、プライバシーと性能を両立させます。 実験では、個人情報を完全に公開した場合の9割以上の性能を維持しつつ、情報漏洩を最小限に抑え、従来のローカルモデル単体や非パーソナライズモデルを平均で7.4%から9%上回る精度を達成することに成功しました。
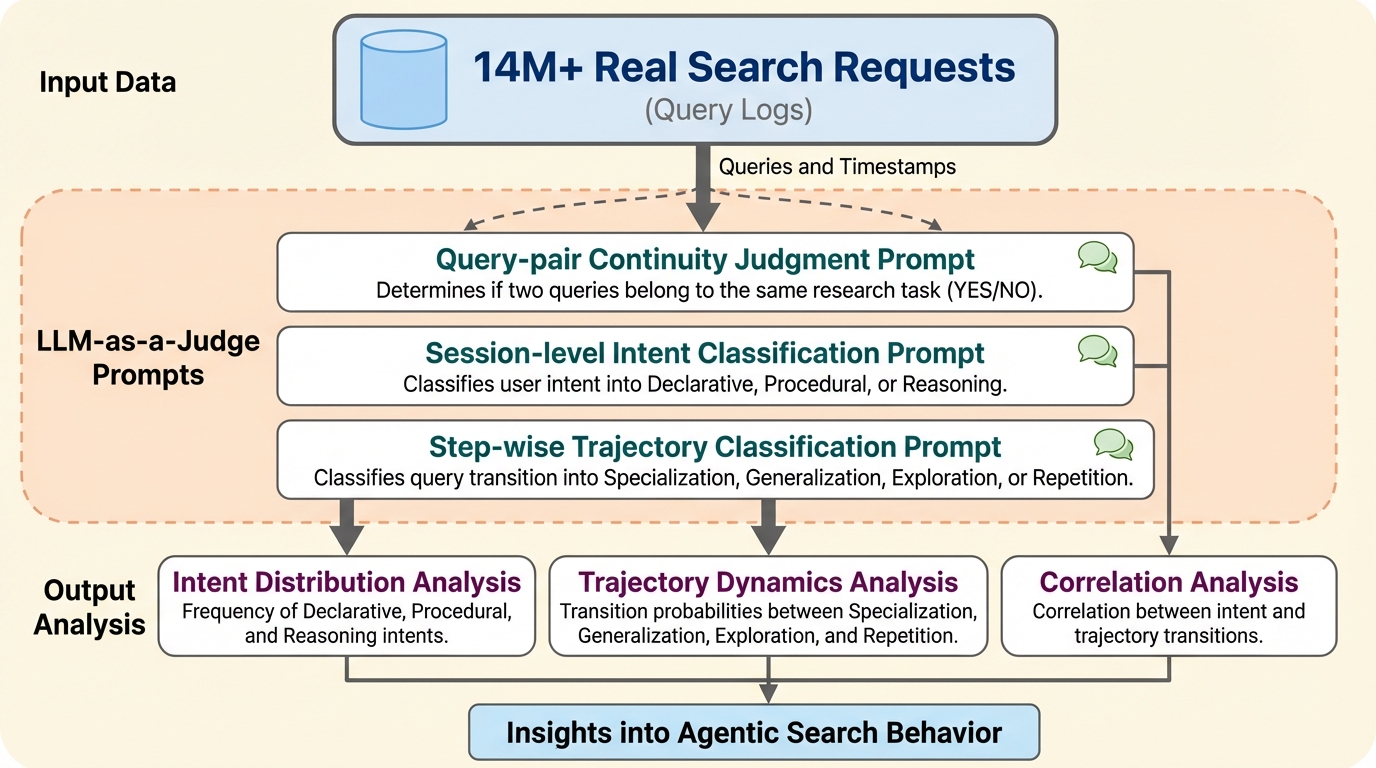
本研究は、1444万件以上の実検索リクエストと397万件のセッションを含む大規模ログを分析し、自律型エージェントの検索行動を世界で初めて包括的に解明しました。 エージェントの検索意図(事実確認、手続き、推論)によって行動パターンが大きく異なり、特に事実確認では非効率な重複が発生しやすい一方で、推論では広範な探索が行われることを特定しました。 新規クエリ用語の54%が過去の検索結果に由来することを示す新指標「CTAR」を提案し、エージェントがセッション全体を通じて蓄積された文脈をクエリの洗練に活用していることを定量的に証明しました。
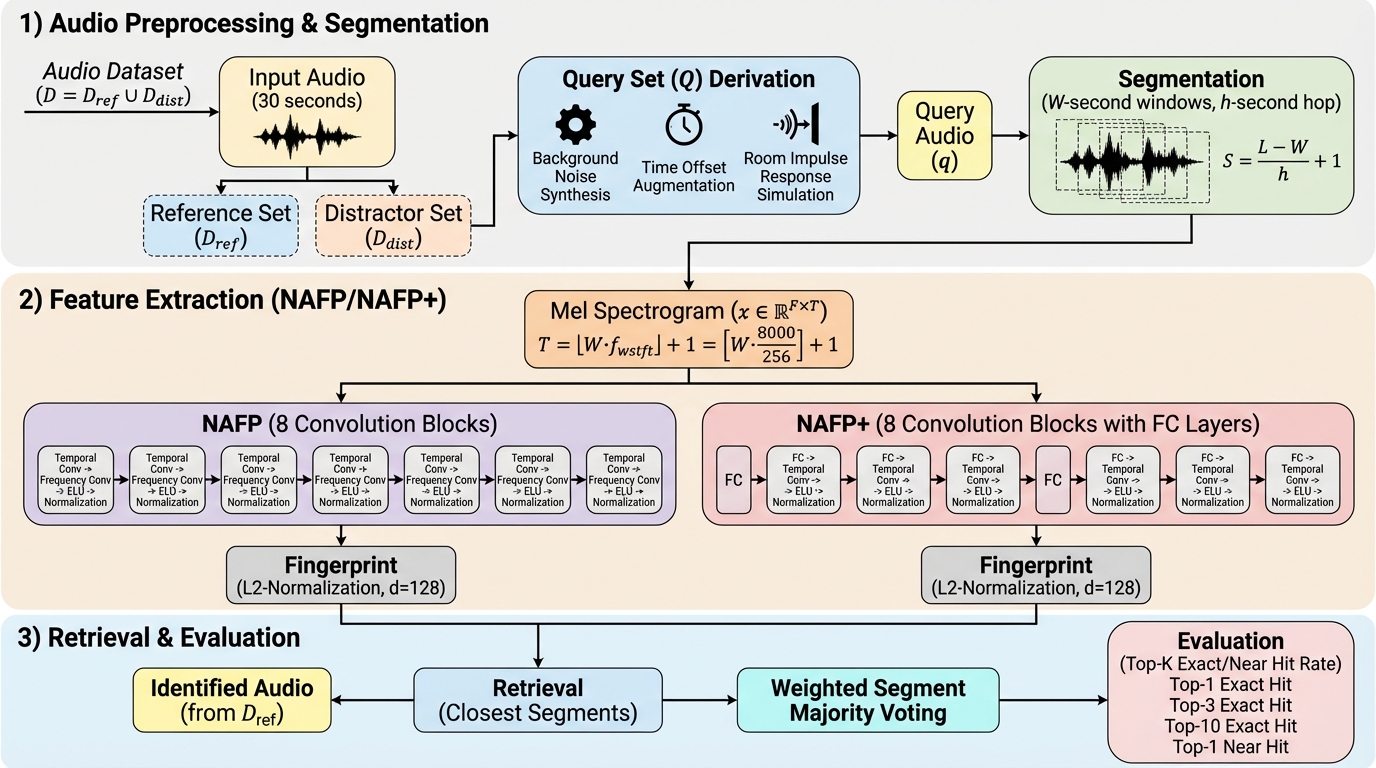
本研究は、音声指紋照合システムにおいて音声を切り出す際の「セグメント長」が照合精度に与える影響を、既存モデルを拡張したNAFP+を用いて詳細に調査したものです。 実験の結果、0.5秒という短いセグメント長が、特に3秒未満の短いクエリにおいて最も高い照合精度を達成し、クエリ長が4秒を超えると精度の向上が飽和する傾向が明らかになりました。 また、最適なセグメント長を提案する能力を大規模言語モデルで比較したところ、GPT-5-miniが実際の実験結果と最も合致する1秒前後の設定を一貫して推奨し、システム設計における高い信頼性を示しました。
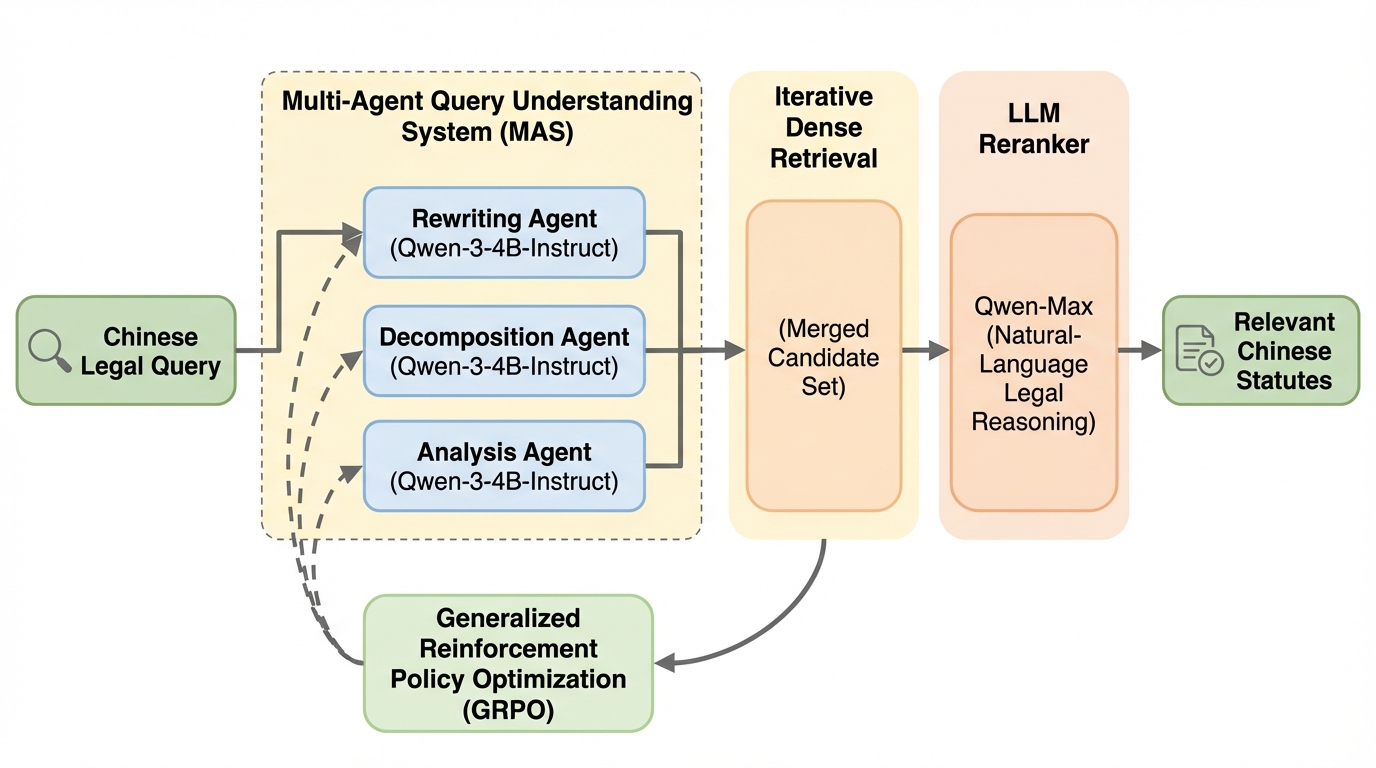
LegalMALRは、口語的で複雑な法的クエリに対し、複数のAIエージェントが多様な視点からクエリを再構成し、反復的に検索を行うことで候補の網羅性を劇的に向上させる新しいフレームワークである。このシステムは、GRPO(Generalized Reinforcement Policy Optimization)を用いてエージェントの挙動を安定化させるとともに、Qwen-Maxを活用したゼロショットのリランキングにより、従来の手法では困難だった高度な法的推論に基づく条文特定を実現している。独自の難関データセットCSAIDおよび公開ベンチマークSTARDを用いた検証の結果、LegalMALRは既存のRAGパイプラインを大幅に上回る精度を達成し、暗黙的な法的論点を含む実務的な検索課題に対して極めて有効であることが証明された。
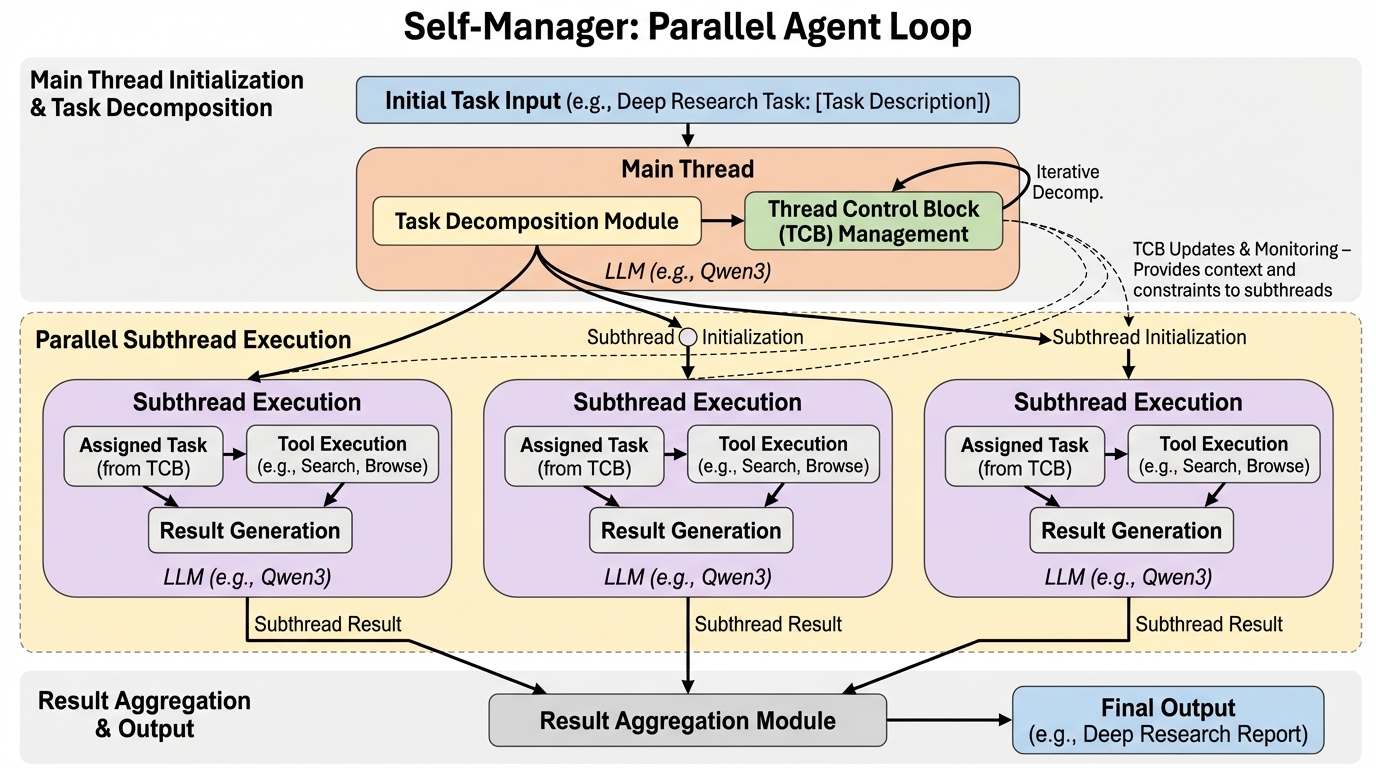
長文の深掘り調査において、従来のエージェントが抱えていた文脈の線形な蓄積による情報の希釈や、逐次実行による処理の停滞という課題を解決するため、非同期かつ並列な実行を可能にする新しいアーキテクチャ「Self-Manager」が提案されました。