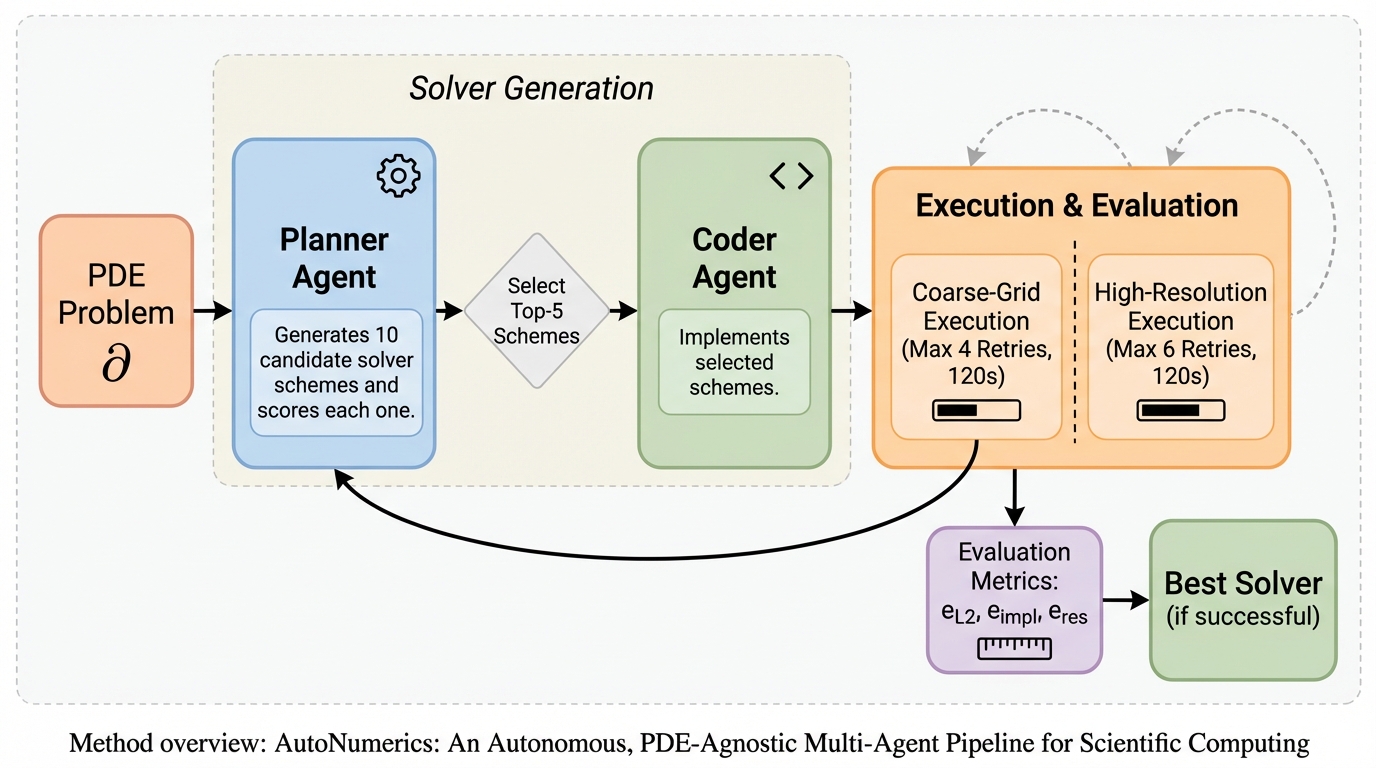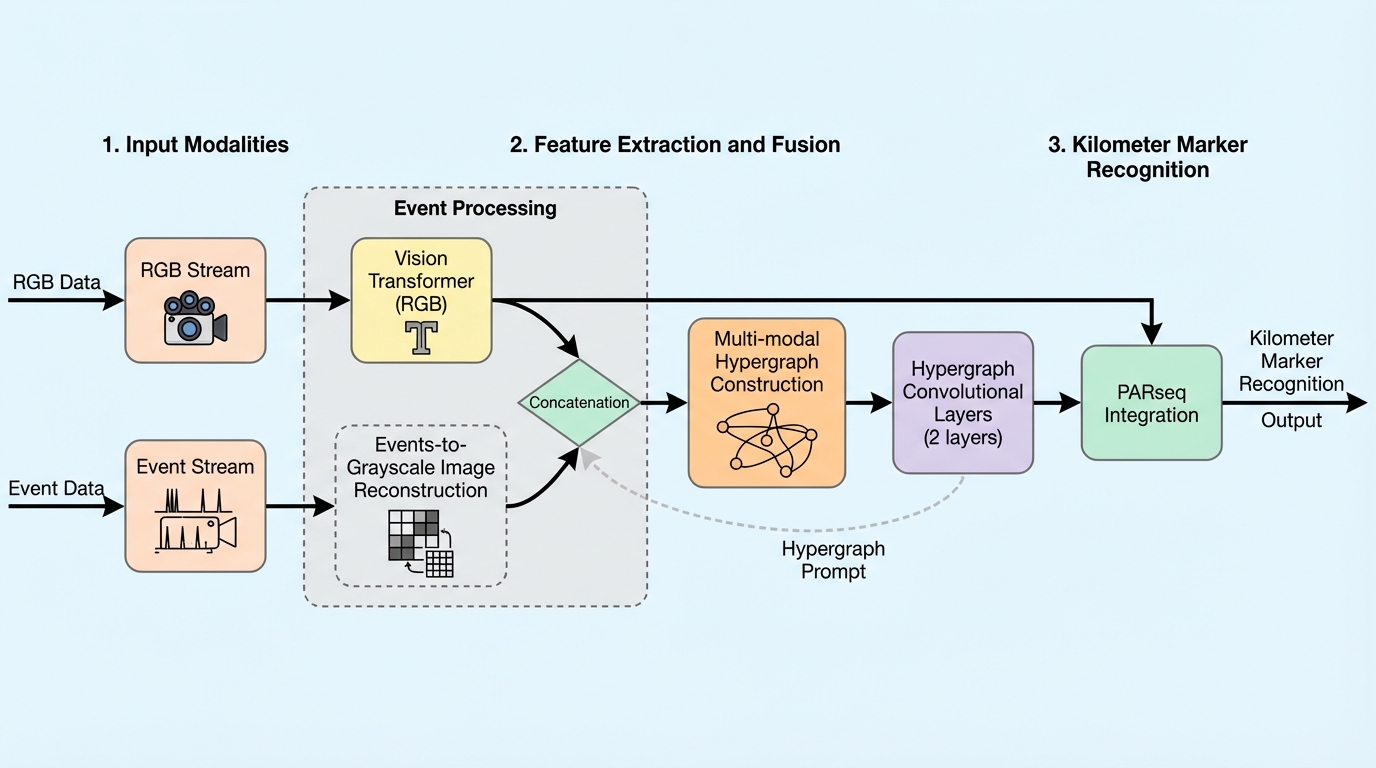
HGP-KMR:RGB とイベントカメラを組み合わせ、地下鉄のキロ程標認識を強くする
HGP-KMR は、通常の RGB 画像だけでは厳しい地下鉄環境のキロ程標認識に対し、イベントカメラ由来の情報を hypergraph prompt として foundation model 側へ注入することで精度を上げる手法です。 あわせて EvMetro5K という 5,599 組の RGB-Event ペアからなる専用データセットを整備し、EvMetro5K で 95.1% 精度、PARSeq 比 +3.4 ポイントを達成しています。 面白いのは、単に RGB と event を結合するだけでなく、両モダリティの高次関係を hypergraph として表現し、それを prompt 的に RGB backbone 各層へ注入した点です。単純融合より精度は高く、推論速度も 89 FPS と実用圏に収まっています。