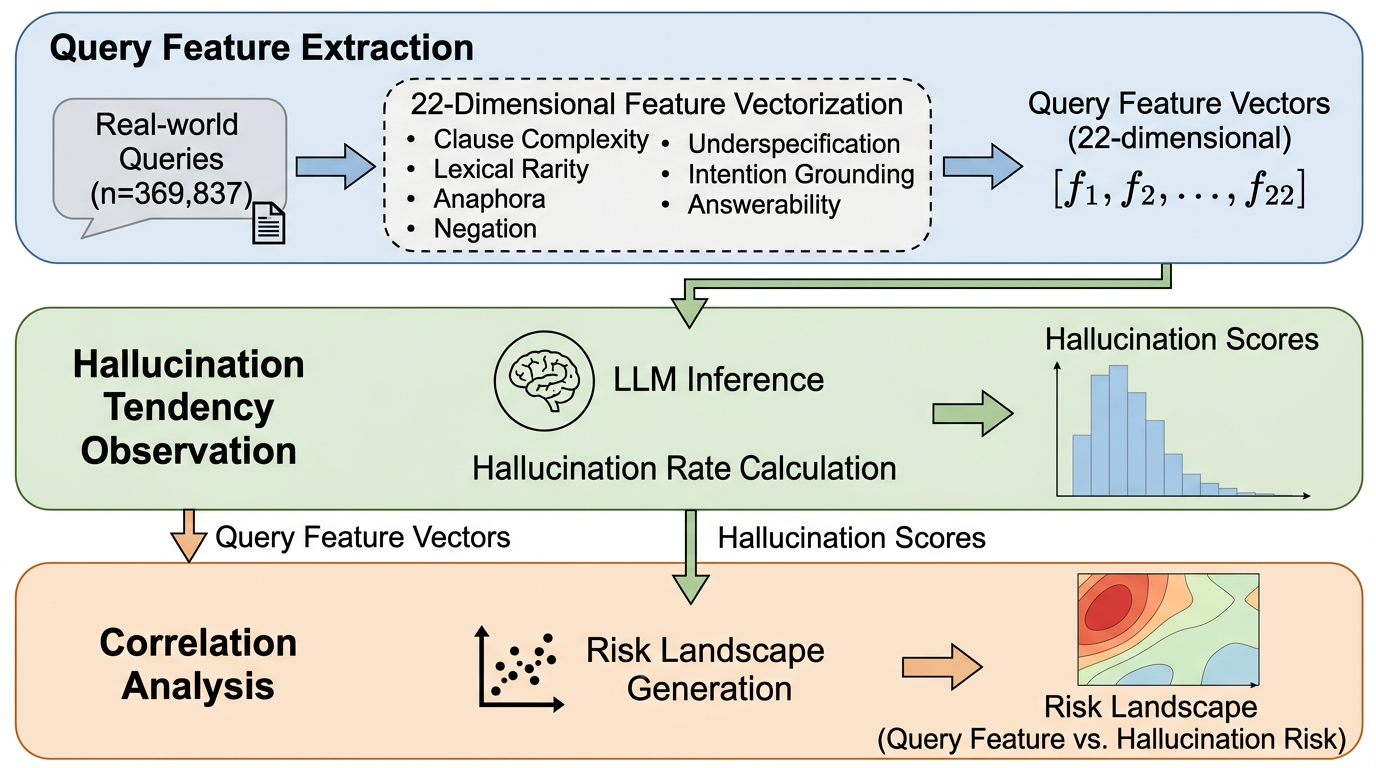
LLM憲法的マルチエージェント統治:協力を増やしつつ自律性と公正性を守れるか
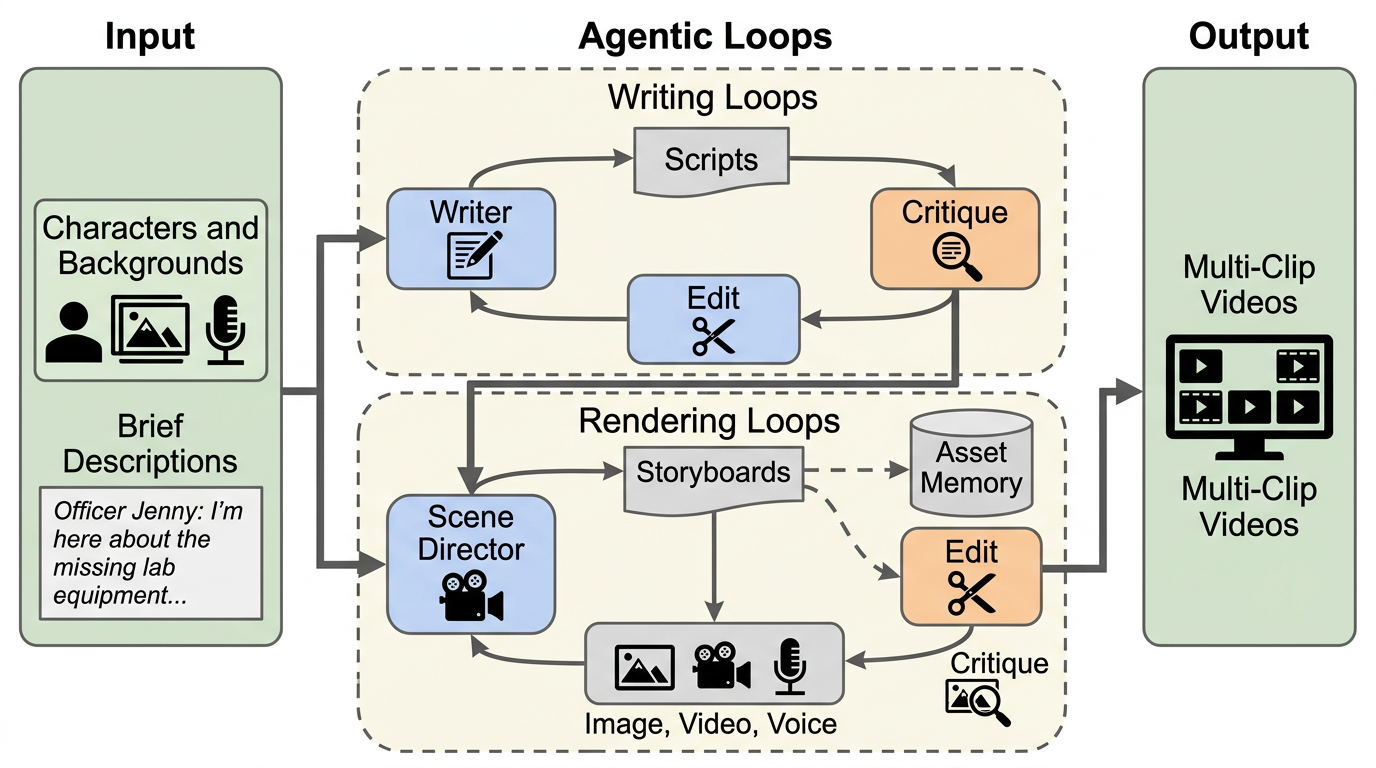
LLM が集団の協力行動を高める影響戦略を作れてしまう一方で、その協力が自律性や公正性を壊した「操作された協力」になり得る点を問題にしています。 / 著者らは Constitutional Multi-Agent Governance(CMAG)という二段階の統治枠組みを提案し、禁止テーマや誇張表現を弾く hard constraints と、協力・自律性・整合性・公平性の釣り合いで選ぶ soft optimization を組み合わせます。 / 80エージェントのスケールフリーネットワーク実験では、無制約最適化が生の協力率では最高でも倫理協力スコアでは最悪になり、CMAG は協力率を少し落とす代わりに自律性・整合性・公平性を大きく守る結果になりました。