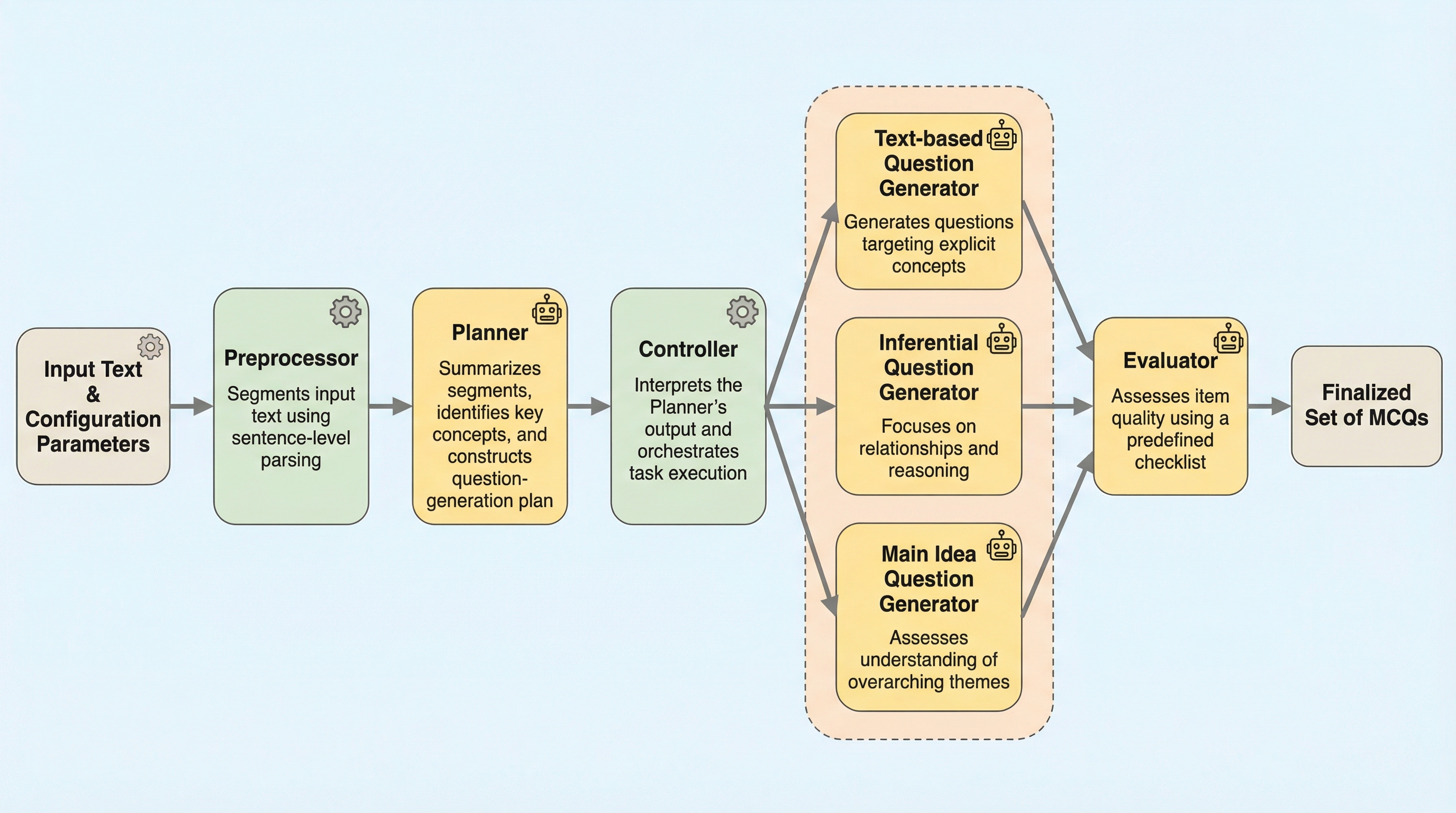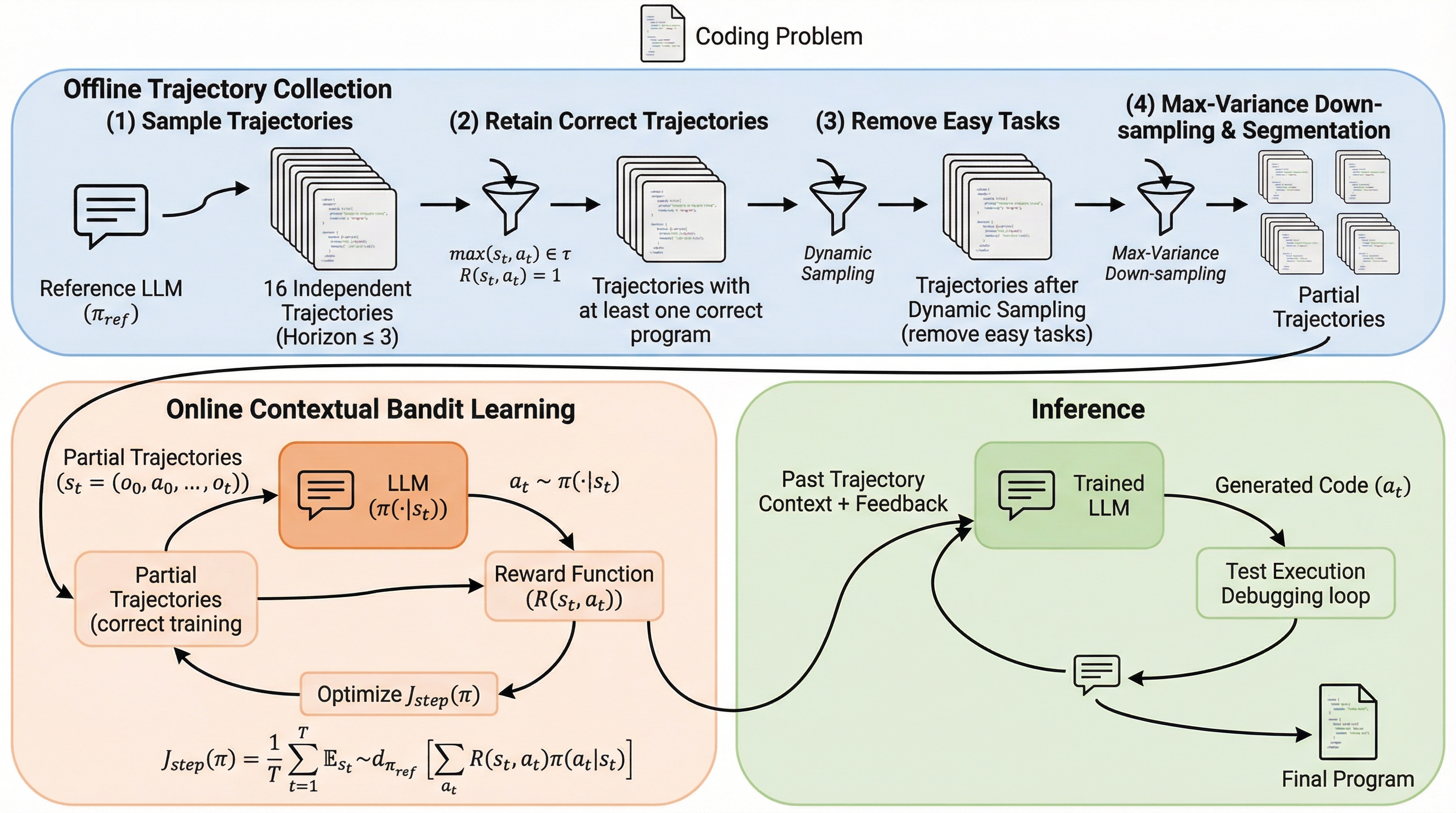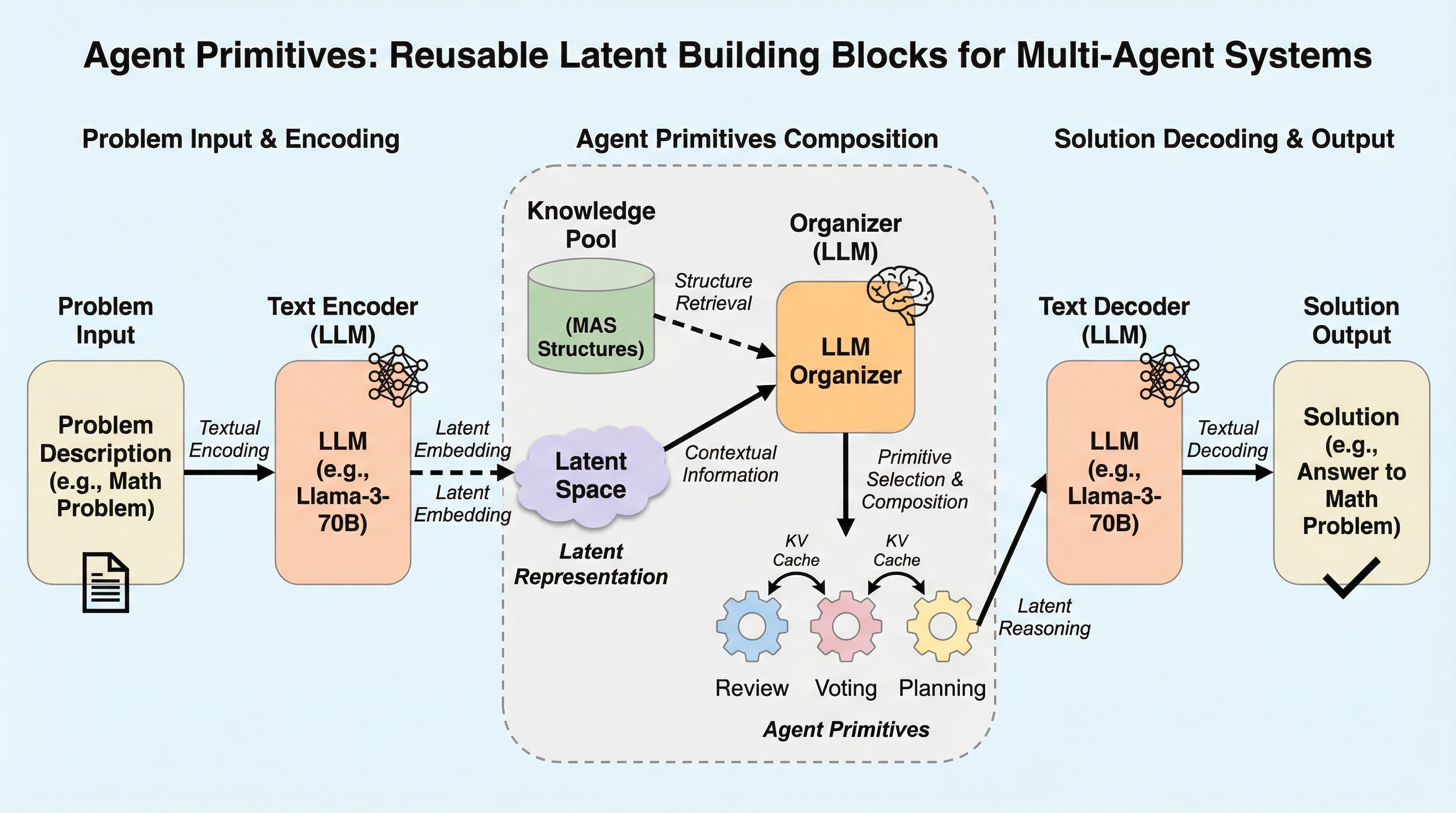
エージェント・プリミティブ:マルチエージェントシステムのための再利用可能な潜在的構成要素
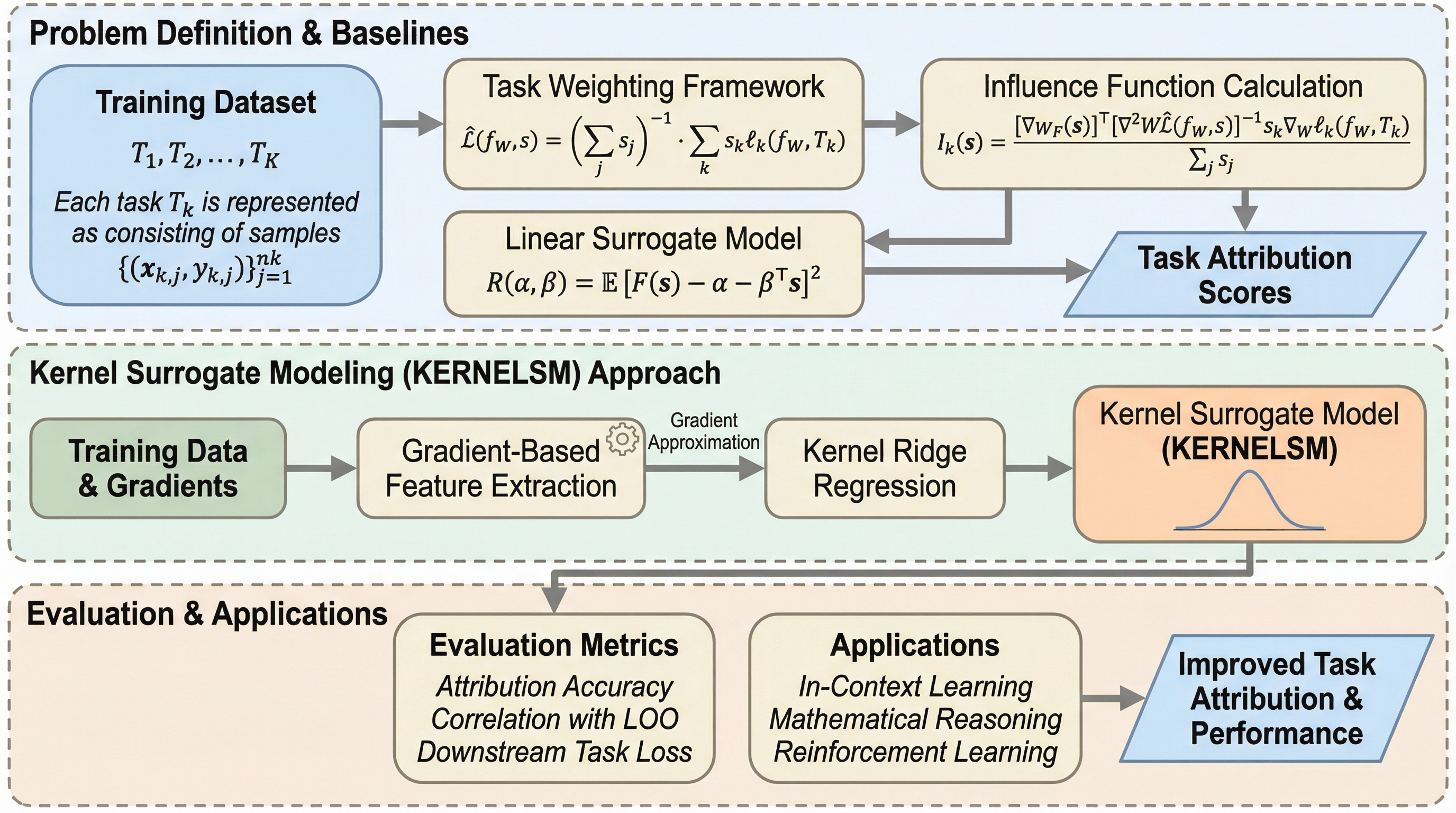
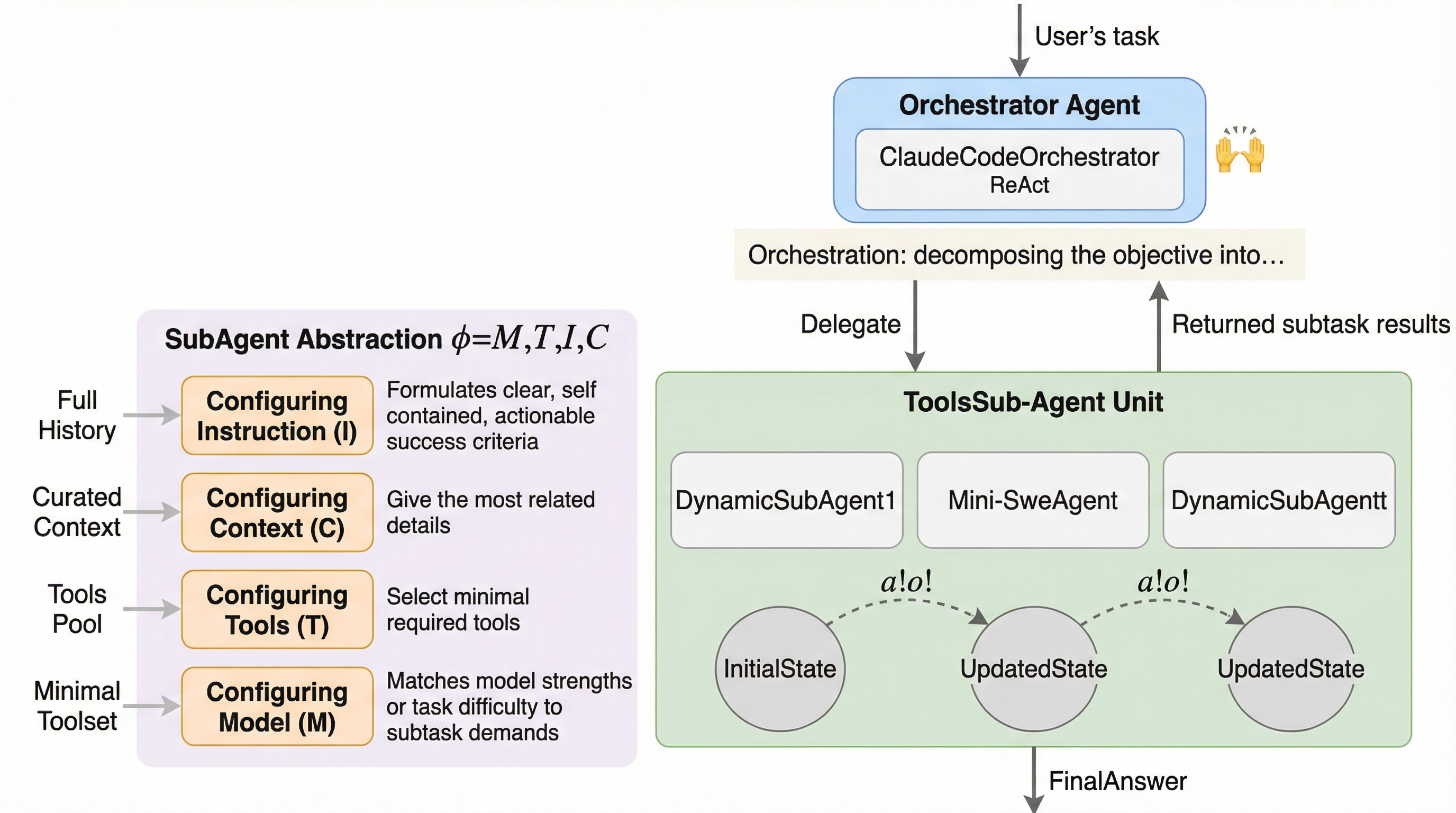
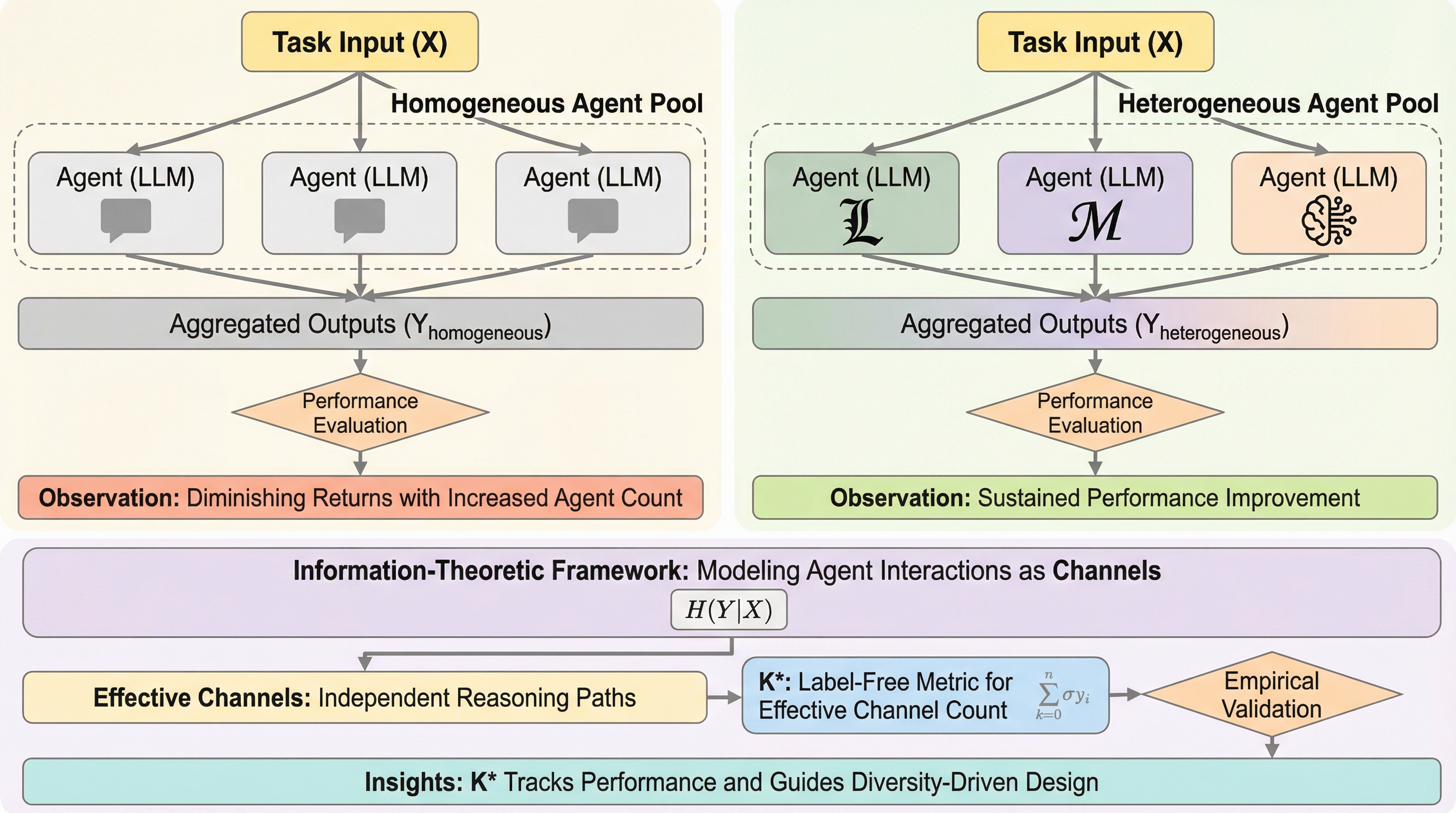
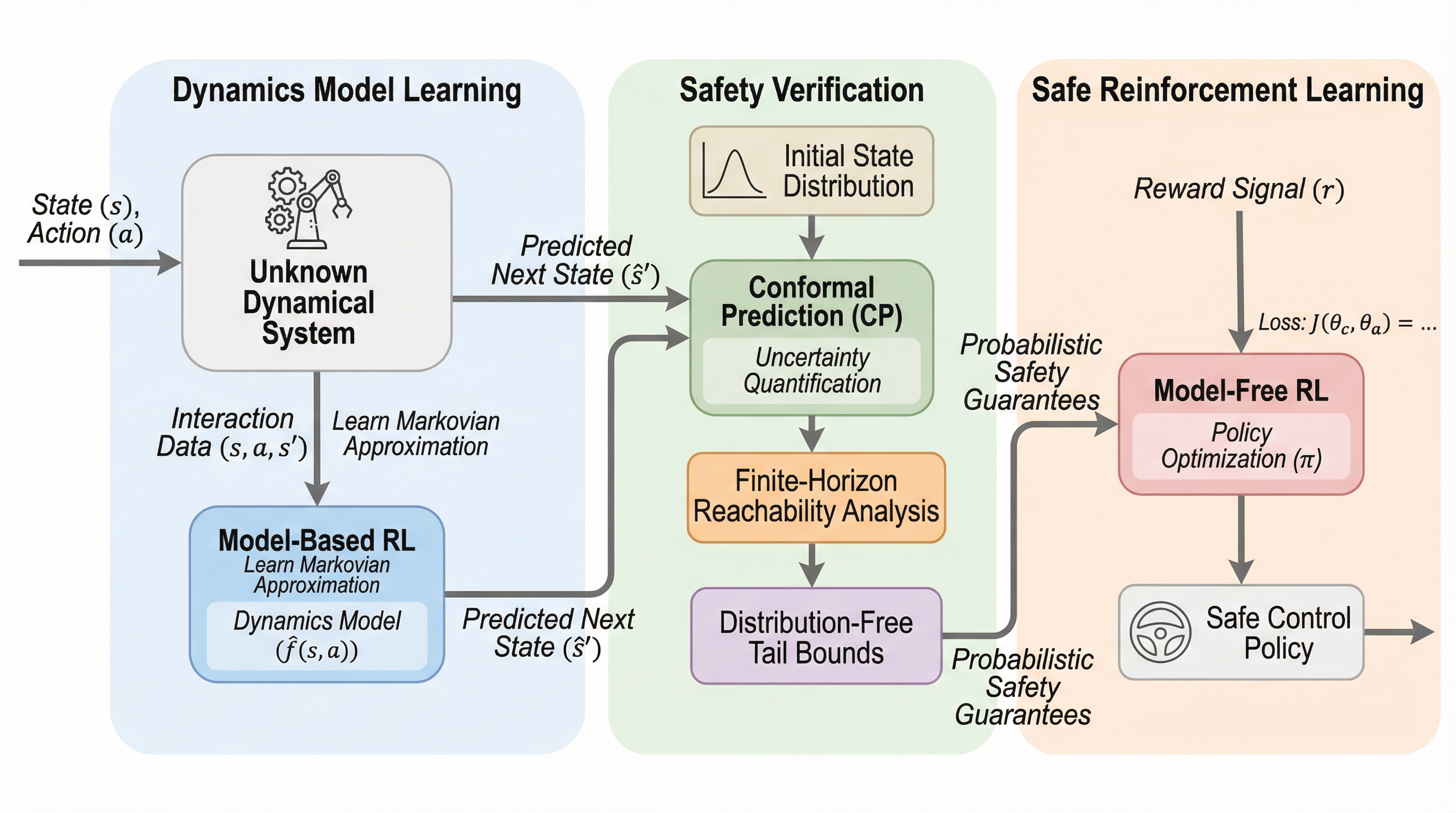
従来のマルチエージェントシステム(MAS)が抱えていた、タスクごとに手動でプロンプトや役割を設計しなければならない構築コストの高さと、自然言語による通信が長文コンテキストやノイズによって劣化するという二つの根本的な課題を解決するため、ニューラルネットワークの構成要素に着想を得た「Agent Primitives」という再利用可能な潜在的構成ブロックが提案されました。 これは、Review(推敲)、Voting and Selection(投票と選択)、Planning and Execution(計画と実行)という、多くのシステムで共通して見られる計算パターンを抽象化したものであり、エージェント間の通信にテキストではなくキー・バリュー(KV)キャッシュを直接受け渡す潜在的通信を採用することで、情報の劣化を防ぎつつ処理の高速化を実現しています。 数学的推論やコード生成などのベンチマークを用いた検証の結果、単一エージェントと比較して平均精度が12.0〜16.5%向上し、従来のテキストベースのシステムよりもトークン使用量と推論遅延を3〜4倍削減することに成功したほか、長文の文脈における指示遵守率が自然言語通信の15.6%から73.3%へと劇的に改善されるなど、高い堅牢性が確認されました。