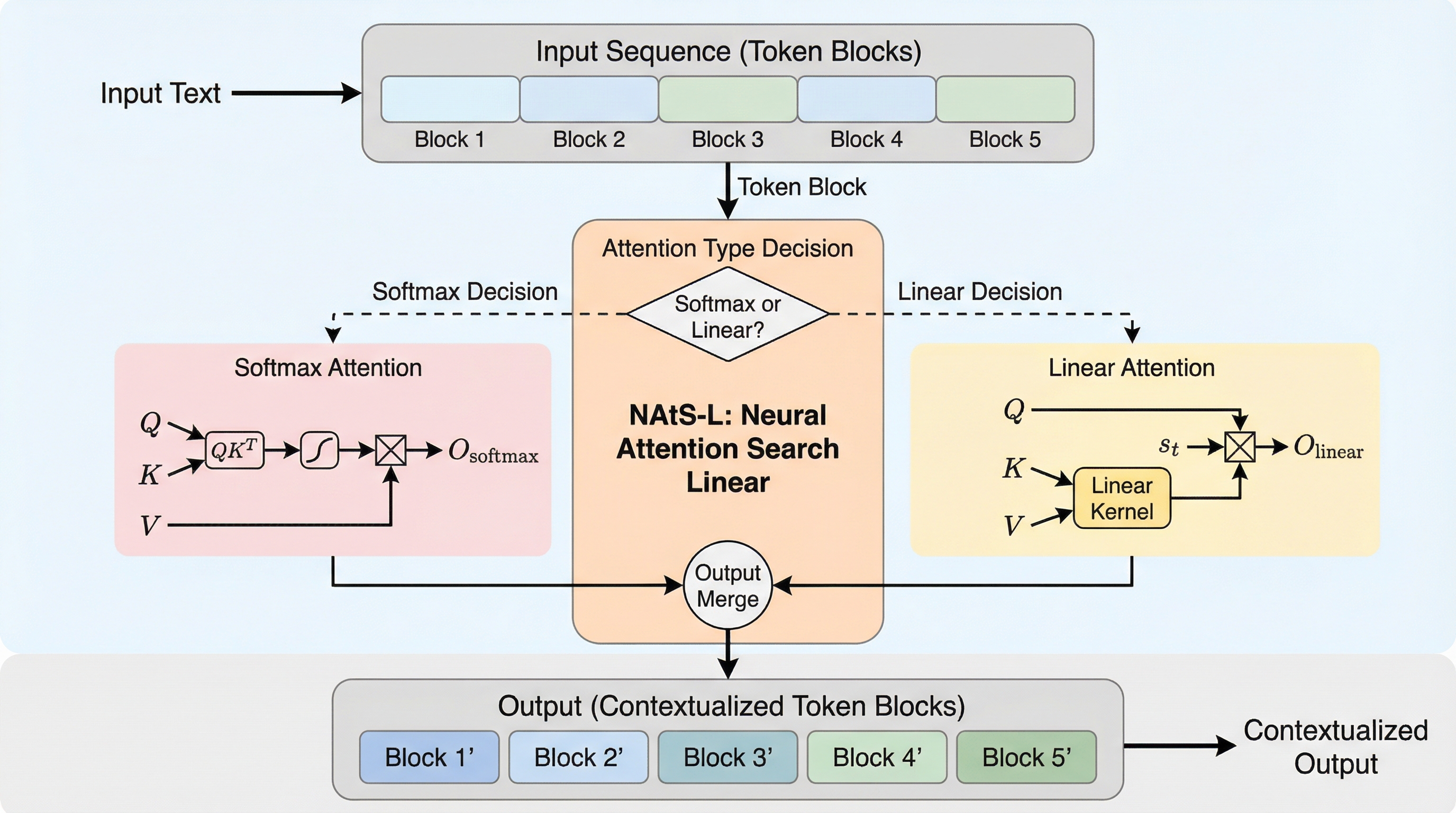
Neural Attention Search Linear:適応的なトークンレベルのハイブリッド・アテンション・モデルに向けて
従来のTransformerが抱える計算量の課題と線形アテンションの表現力の限界を解決するため、同一レイヤー内でトークンごとに最適な演算を適応的に選択するフレームワーク「NAtS-L」が開発されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来のTransformerが抱える計算量の課題と線形アテンションの表現力の限界を解決するため、同一レイヤー内でトークンごとに最適な演算を適応的に選択するフレームワーク「NAtS-L」が開発されました。
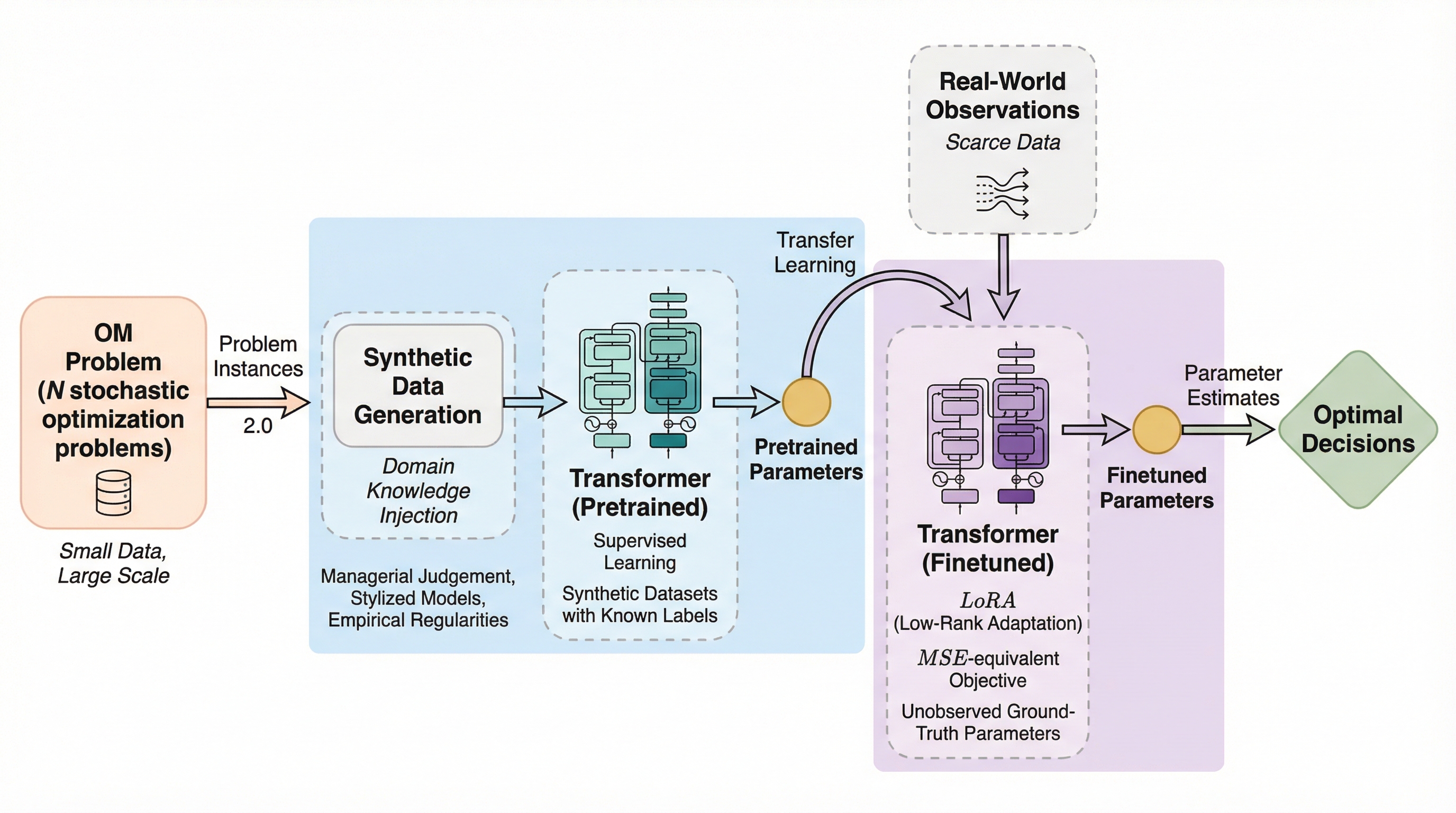
本研究は、少数のデータ点しか得られない大規模な意思決定問題に対し、大規模言語モデル(LLM)の成功に触発された「事前学習と微調整(Pretrain-then-Finetune)」という新しい枠組みを提案している。
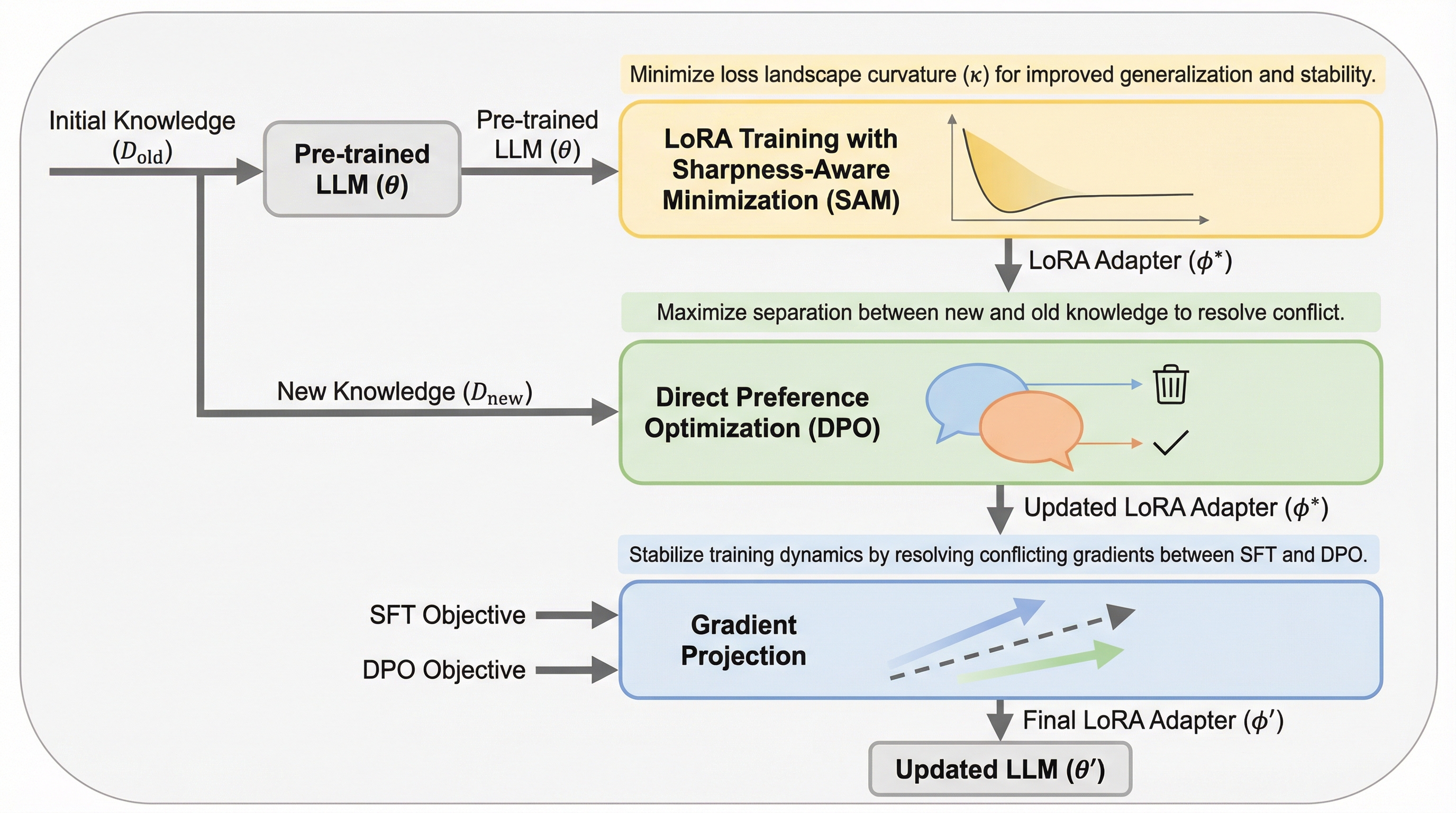
大規模言語モデルの内部知識を効率的に更新する手法として、モデル編集やLoRAなどのパラメータ効率的な微調整が検討されてきましたが、入力形式の変化への弱さや複数回の更新における不安定さ、そして古い知識との衝突が実用上の大きな課題となっていました。
石油生産の最適化と安全管理に不可欠な坑底圧力(BHP)を、高コストで故障しやすい物理センサに頼らず、地上の計測データから高精度に推定する「ソフトセンサ」を開発した。 深層学習のLSTMモデルを採用し、さらに大規模油田で学習した知識を別の油田へ適用する「転移学習」を導入することで、データが不足している環境や異なる運用条件下でも、平均絶対誤差率(MAPE)2%未満という極めて高い推定精度を達成した。 ブラジルのプレソルト油田における13年間の膨大な実データを用いた検証により、複雑な多相流条件下でも従来の経験式や標準的なニューラルネットワークを凌駕する性能が確認され、物理センサの代替やデジタルツインへの応用によるコスト削減と運用効率化が期待される。
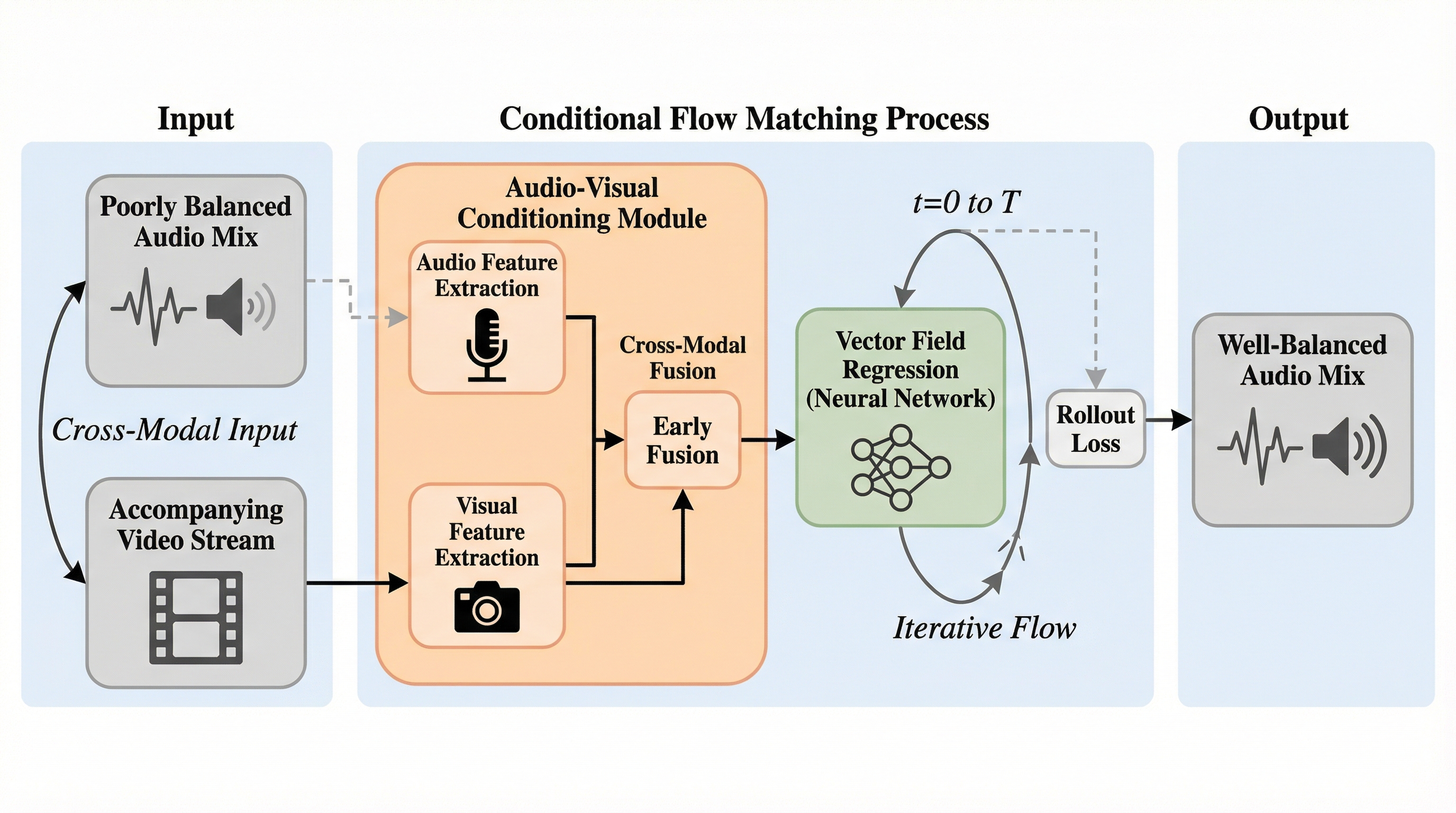
映像の視覚情報に基づいて音声のバランスを調整する「視覚誘導型音響ハイライティング(VisAH)」において、従来の識別モデルの限界を克服するため、生成モデルである条件付きフローマッチング(CFM)を用いた新手法「VisAH-FM」を提案した。
大規模言語モデルの学習においてデータの質がボトルネックとなる中、従来のドメイン混合(マクロ)とサンプル選択(ミクロ)を個別に扱う手法では、コードのような厳密な論理構造を持つデータの整合性が損なわれるという課題があった。
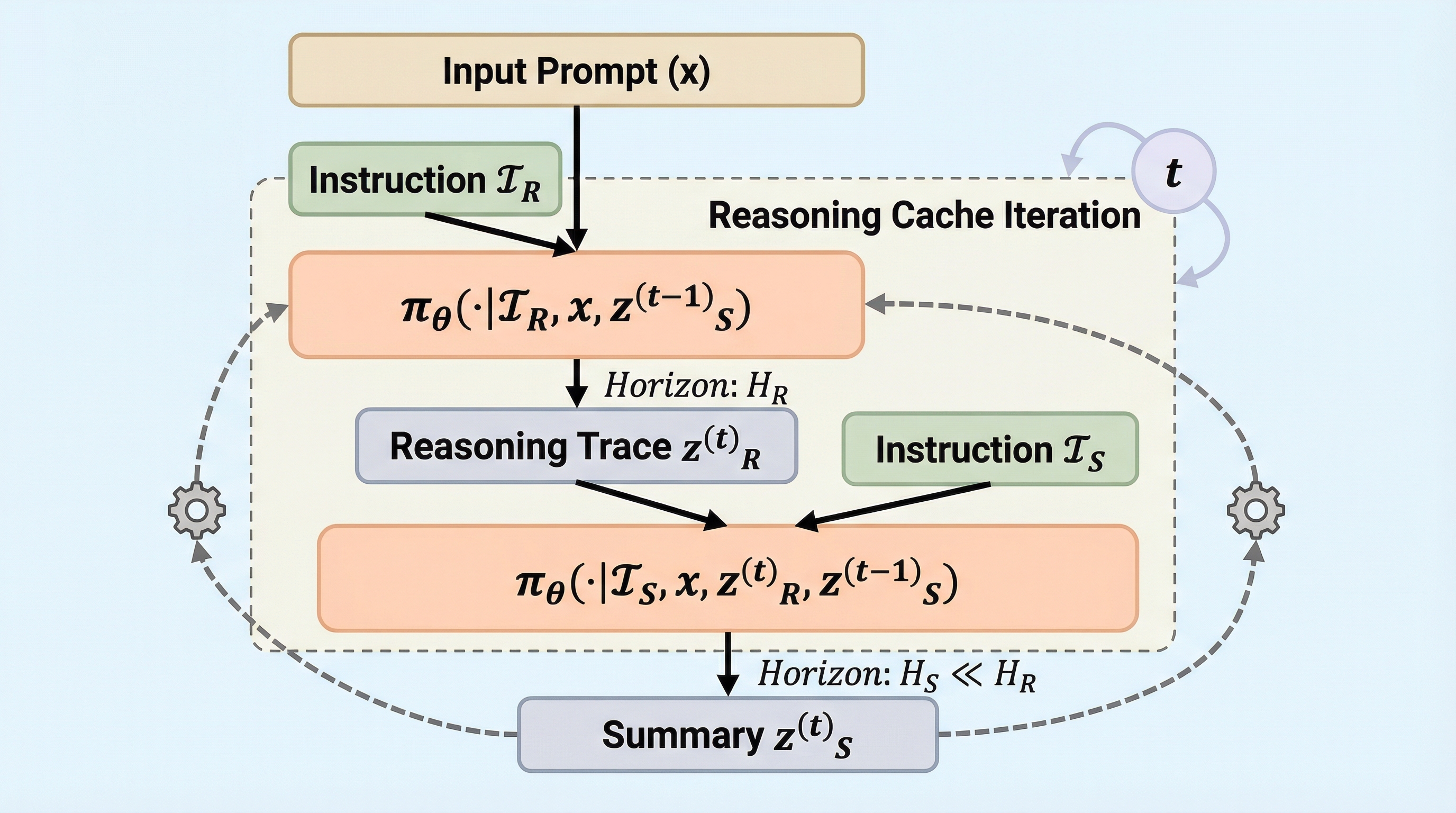
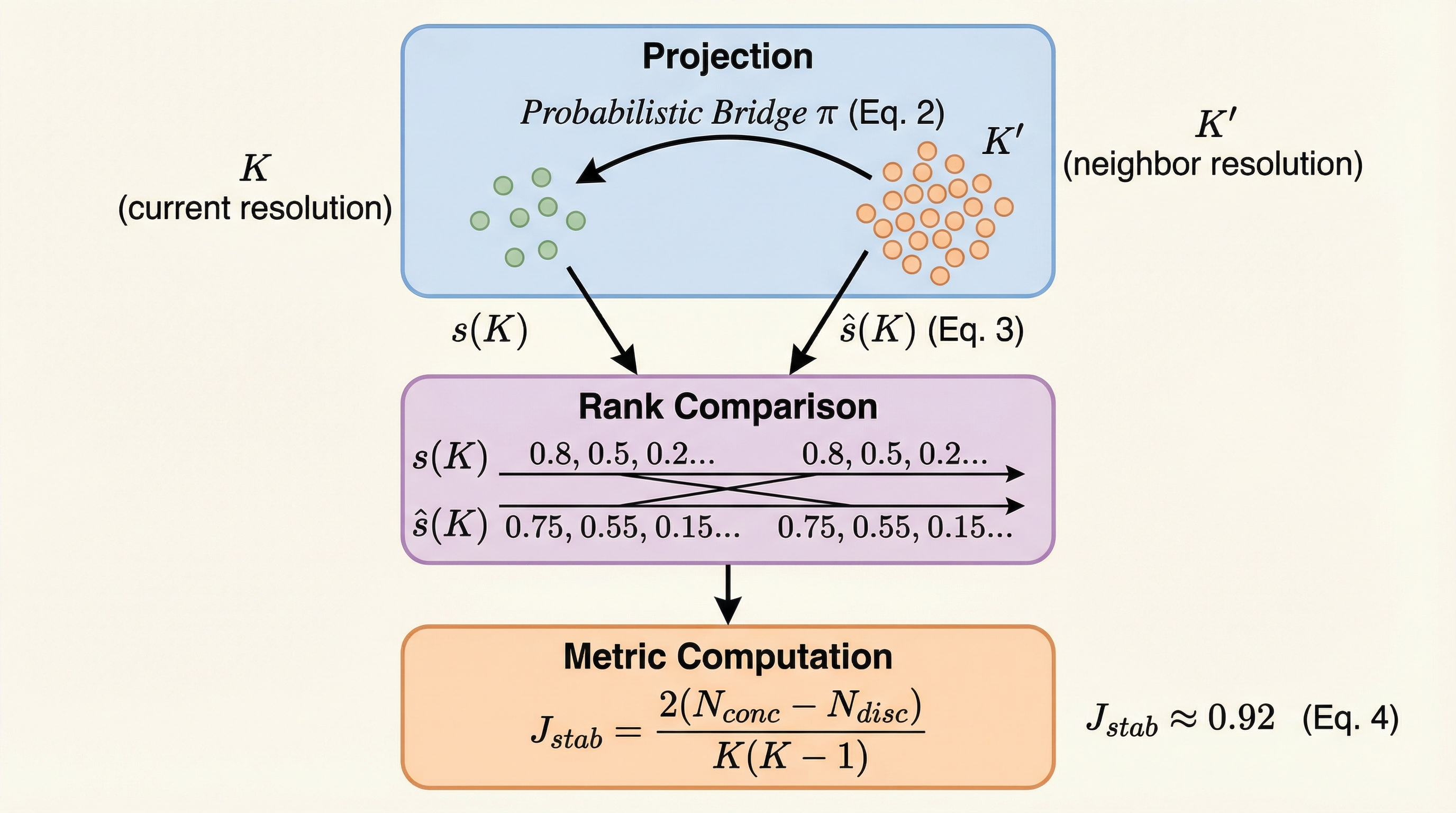
Reasoning Cache(RC)は、推論プロセスを要約して「キャッシュ」として保持し、次の推論をその要約に基づいて行う反復的なデコードアルゴリズムであり、従来の自己回帰型デコードが抱えていた「訓練時の長さを超えると性能が劣化する」という限界を打破することに成功しました。
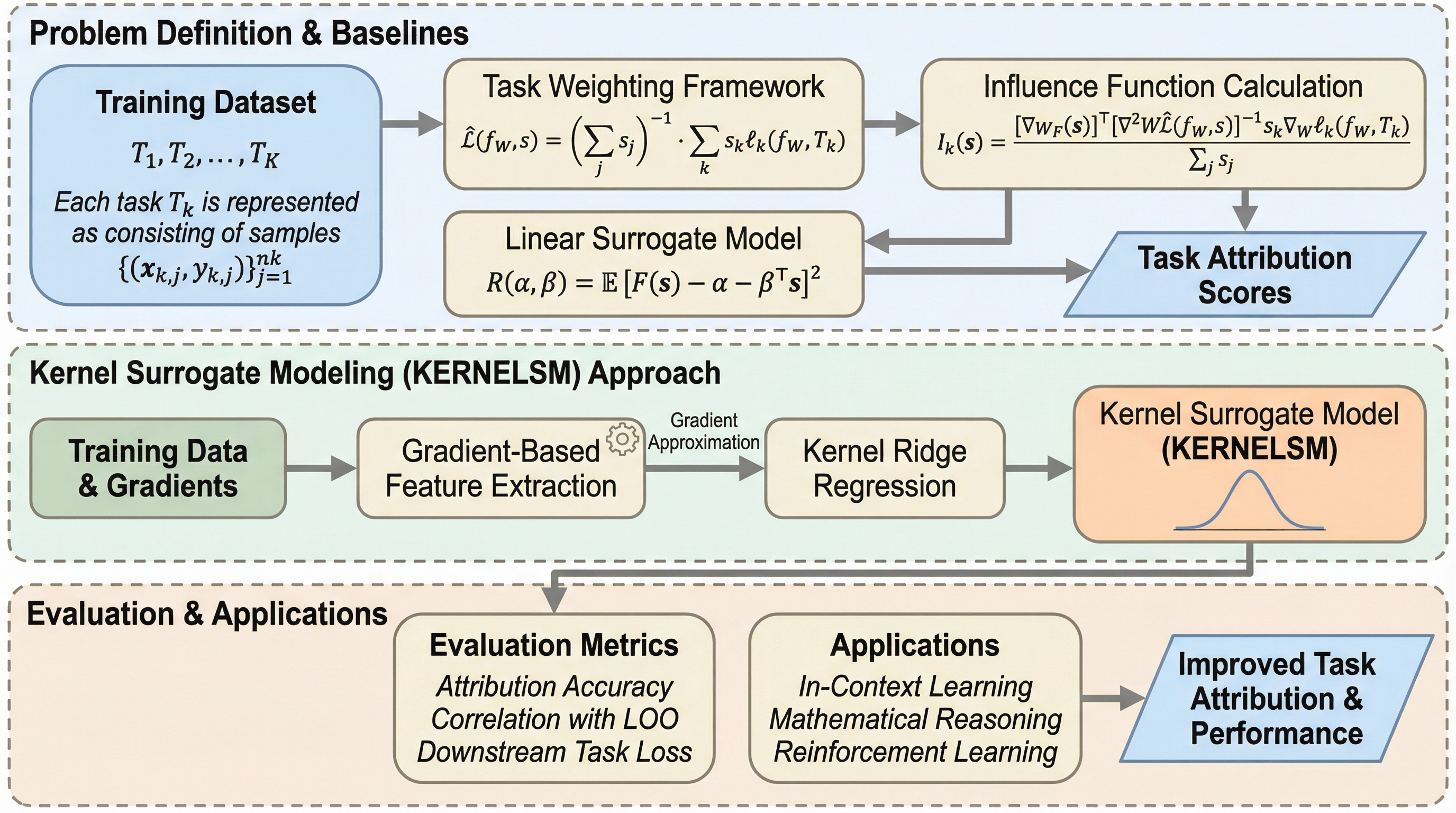
現代のAI学習において、多数の学習タスクが特定の目標タスクに与える影響を解明する「タスク属性評価」は、計算コストとタスク間の複雑な非線形相互作用(相乗効果や反作用)が障壁となっていました。本研究は、従来の線形モデルでは捉えられなかったこれらの非線形関係を、放射基底関数(RBF)カーネルを用いた「カーネル代理モデル(KERNELSM)」によってモデル化し、さらに事前学習済みモデルの勾配情報を活用した「再学習不要」の高速な推定アルゴリズムを開発しました。検証の結果、提案手法は既存の線形モデルや影響関数と比較して、真値である再学習結果との相関を25%向上させ、コンテキスト内学習や多目的強化学習におけるデモンストレーション選択の精度を40%改善することに成功しました。
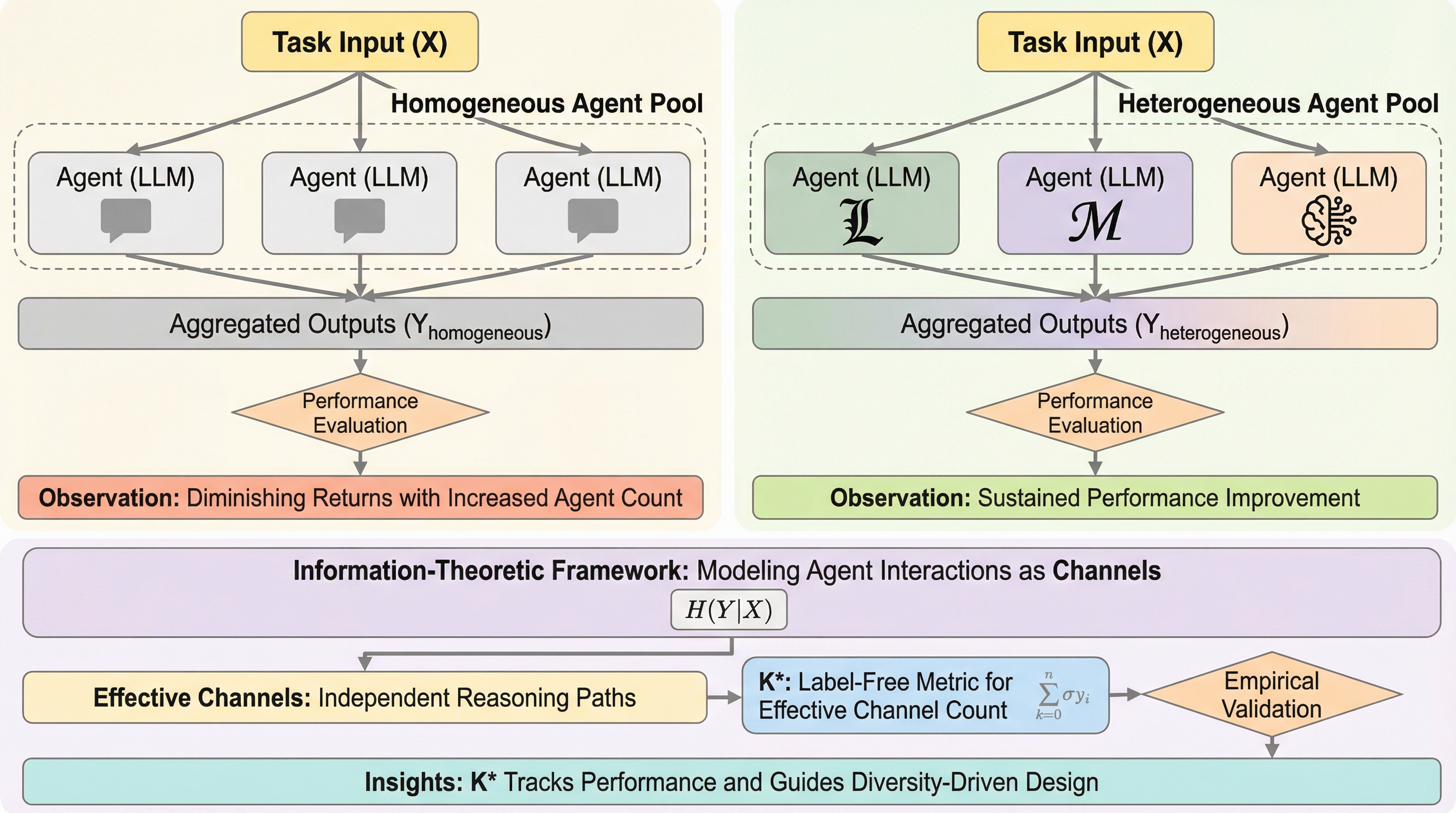
エージェントを16人に増やせば、LLMはもっと賢くなるはず……本当に? 直感的には“人手”が増えるほど強くなりそうですが、意外にも、同じようなエージェントを増やすほど伸びが止まり、「多様性」だけが伸びしろを残します。
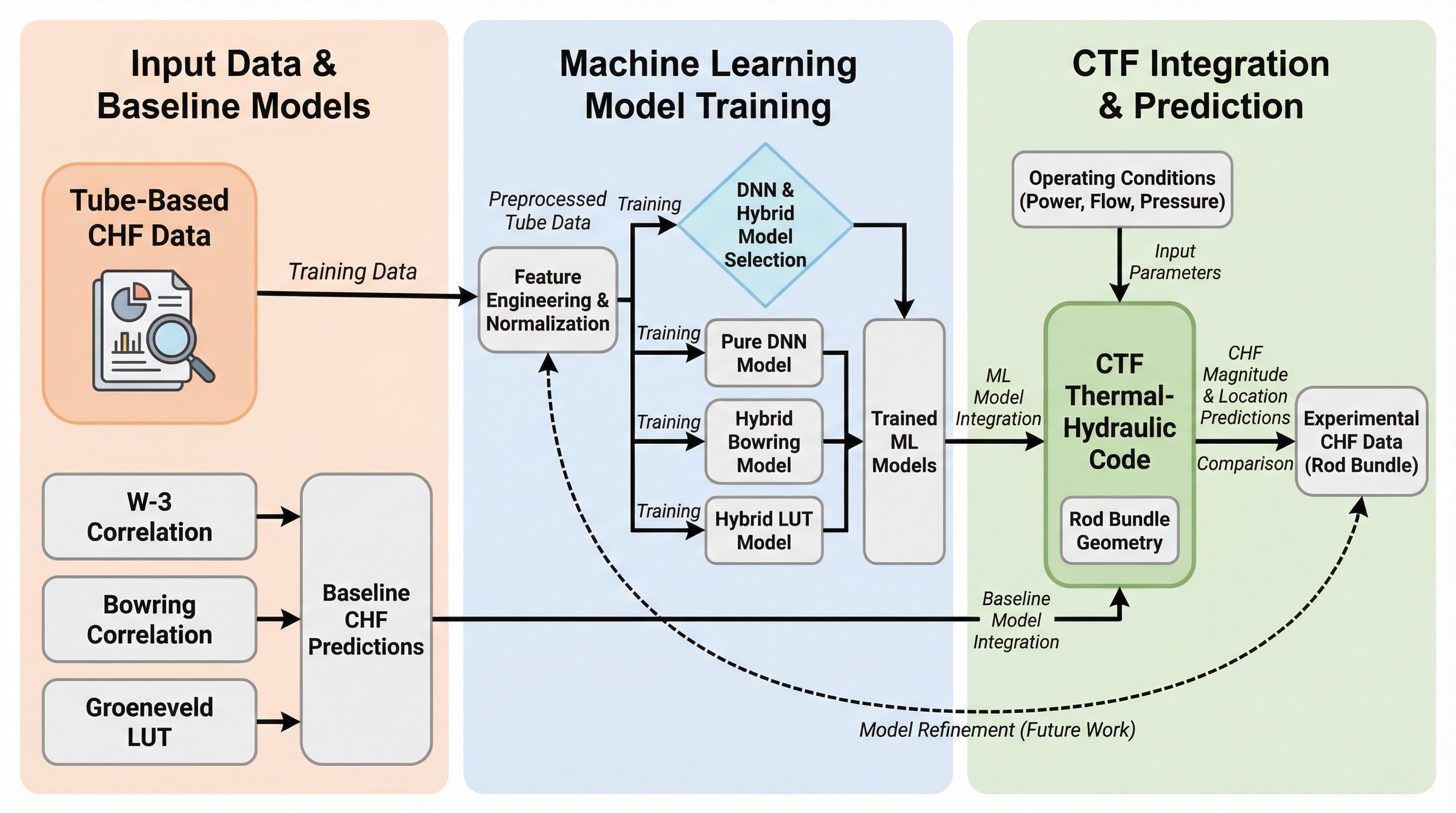
管(チューブ)で学習したモデルは、燃料棒が束になった「ロッドバンドル」でも通用するのか? 意外なのは、複雑さが一気に増えるのに「追加データが足りない」という現実が、手法の選び方だけでなく、“勝ち筋の描き方”そのものを変えさせる点です。