Reasoning Cache: 短いホライゾンの強化学習による長期間の継続的な改善
Reasoning Cache(RC)は、推論プロセスを要約して「キャッシュ」として保持し、次の推論をその要約に基づいて行う反復的なデコードアルゴリズムであり、従来の自己回帰型デコードが抱えていた「訓練時の長さを超えると性能が劣化する」という限界を打破することに成功しました。
TL;DR(結論)
Reasoning Cache(RC)は、推論プロセスを要約して「キャッシュ」として保持し、次の推論をその要約に基づいて行う反復的なデコードアルゴリズムであり、従来の自己回帰型デコードが抱えていた「訓練時の長さを超えると性能が劣化する」という限界を打破することに成功しました。短いホライゾン(16kトークン)での強化学習(RL)を通じて、モデルは要約に基づいた推論能力を向上させ、テスト時には訓練時の30倍以上となる512kトークンの予算まで性能を向上させ続ける「外挿」能力を獲得し、HMMT 2025などの難関数学ベンチマークで劇的な精度向上を達成しています。この手法は、モデルが自らの推論を要約し再利用するという「要約と生成の非対称性」を活用しており、4Bパラメータの小型モデルでありながら、科学的推論を含む多様なタスクにおいて、標準的なデコードを用いるより大規模なモデルや特化型モデルを凌駕する性能を発揮することが確認されました。
なぜこの問題か
大規模言語モデル(LLM)において、テスト時の計算量を増やすことで複雑な問題を解決しようとする試みは一般的ですが、現在の学習パラダイムには大きな制約が存在します。標準的な強化学習(RL)は、固定された問題分布と訓練予算(ロールアウトの長さ)の下で最適化されるため、モデルは訓練時の長さを超えて推論を継続した際に性能を向上させる「外挿」が困難であるという課題を抱えています。訓練予算を超えて推論を続けようとすると、モデルは訓練データには存在しない条件付き分布に直面することになり、その結果として推論が冗長になったり、同じ内容を繰り返したりする「分布のシフト」が発生します。これは、モデルが訓練時に「特定の長さで正解を出すこと」に最適化されてしまい、それを超える未知の領域での振る舞いを学習できていないためです。 また、教師あり微調整(SFT)は推論トレースの内容を模倣することを教えるのみであり、推論を生成するためのアルゴリズムそのものを学習させることには適していません。…
核心:何を提案したのか
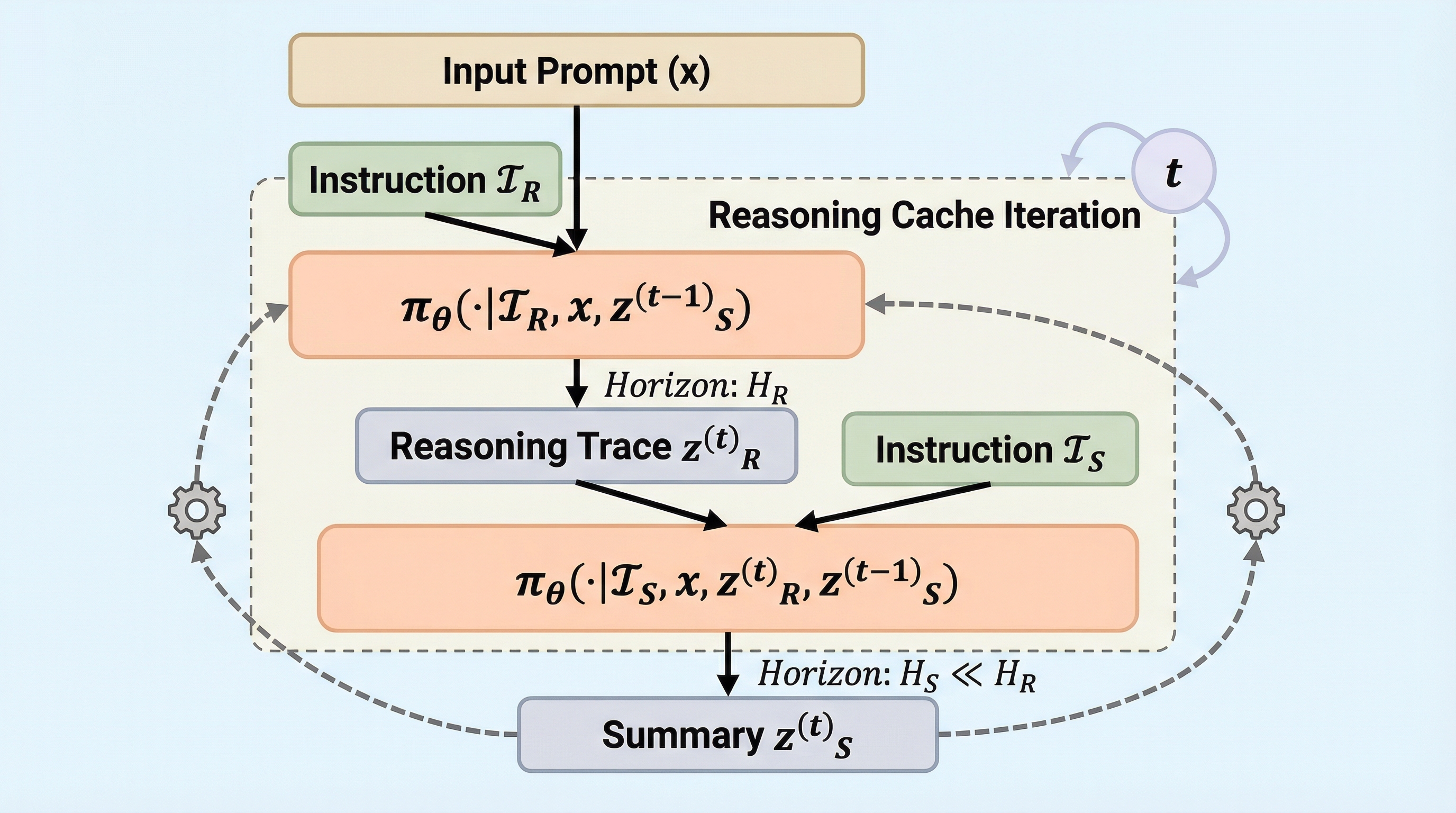
本研究では、従来の自己回帰型デコードを置き換える新しい反復的デコードアルゴリズム「Reasoning Cache(RC)」を提案しています。RCの核心的なアイデアは、長い推論プロセスを複数の短いターンに分割し、各ターンの終了時にそれまでの推論内容を要約(キャッシュ)して、元の詳細なトレースを破棄するというプロセスを繰り返すことにあります。これにより、モデルが一度に処理するトークン数を訓練時の予算内に抑えつつ、実質的な推論のホライゾンを無限に延長することが可能になります。この設計により、モデルは常に自分が慣れ親しんだコンテキストの長さの中で動作することができ、長大な推論に伴う性能劣化や分布のシフトを回避できます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related