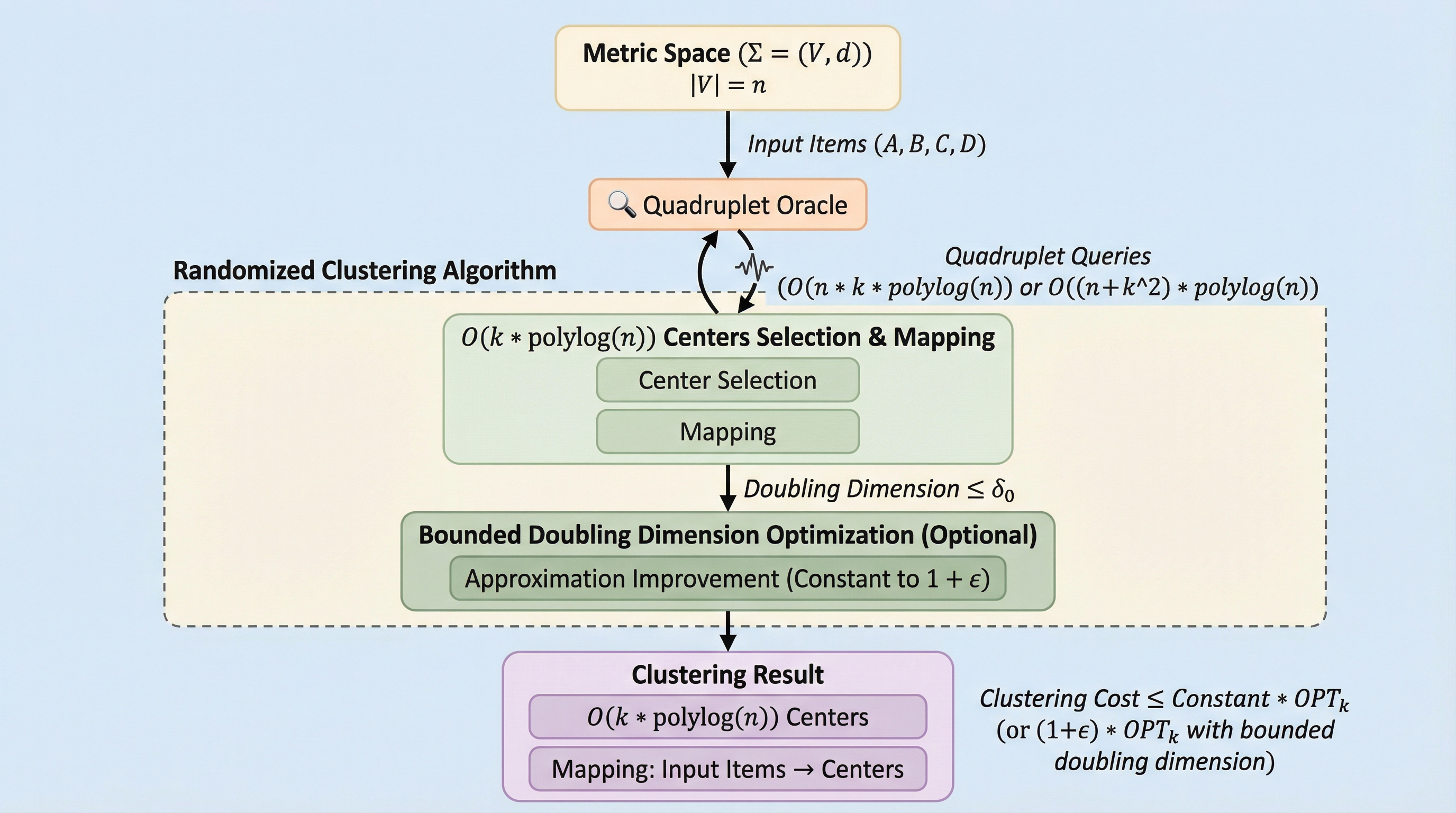
弱い比較オラクルのみを用いた距離$k$-クラスタリング
従来の$k$-クラスタリング手法が正確な距離情報を必要とするのに対し、本研究では2つのペアの距離の大小を比較する「4点オラクル」のみを利用するランクモデル(R-model)において、ノイズを含む条件下でも効率的に動作する新しいランダム化アルゴリズムを提案しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来の$k$-クラスタリング手法が正確な距離情報を必要とするのに対し、本研究では2つのペアの距離の大小を比較する「4点オラクル」のみを利用するランクモデル(R-model)において、ノイズを含む条件下でも効率的に動作する新しいランダム化アルゴリズムを提案しました。
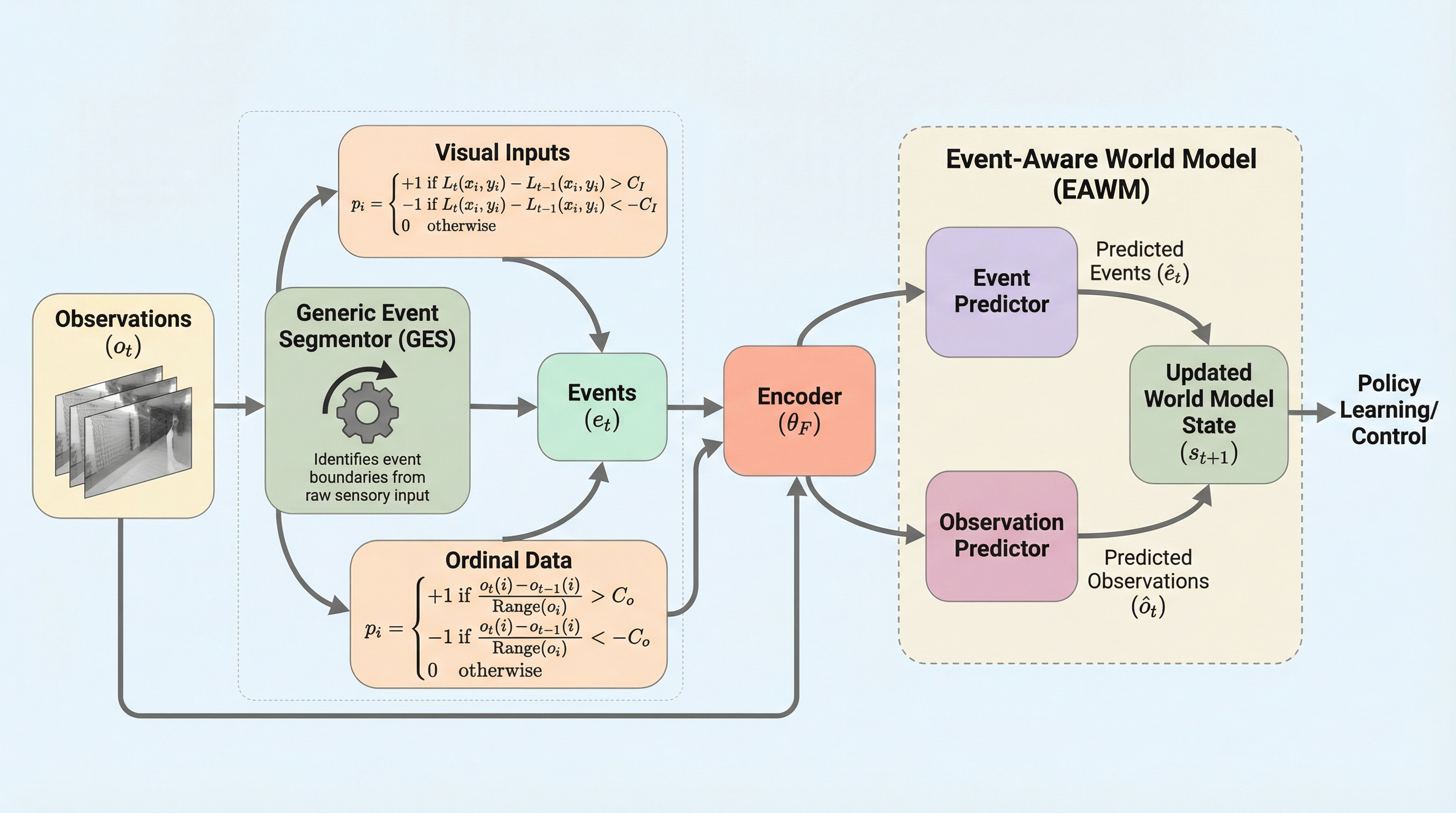
従来のモデルベース強化学習が抱えていた、生のピクセル情報への過度な依存やノイズに対する脆弱性を克服するため、人間の認知機能を模倣して連続的な観測を意味のある「イベント」として切り出す「イベント認識型世界モデル(EAWM)」が提案されました。
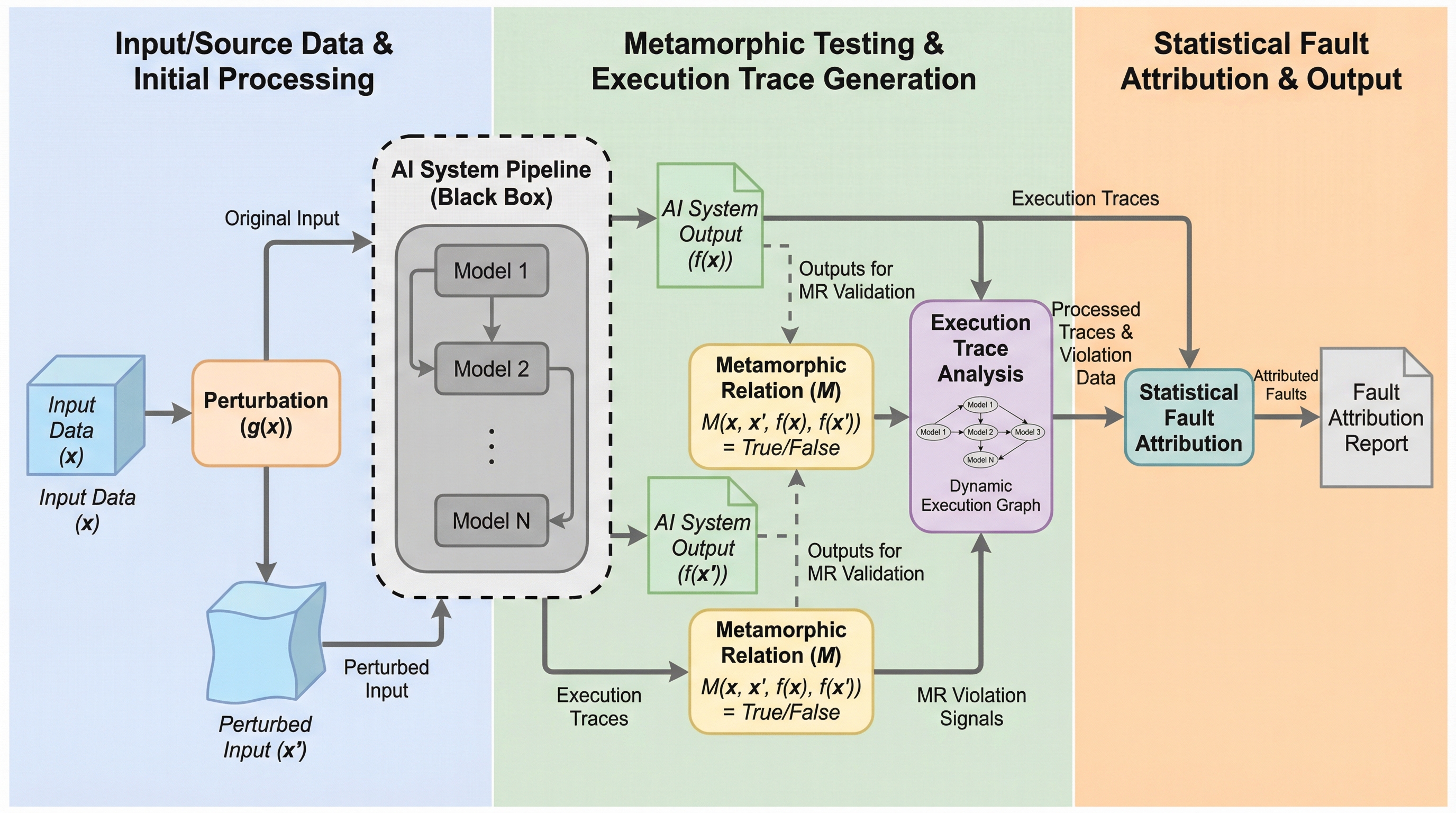
現代のAIシステムは複数のニューラルネットワークを組み合わせた複合的なパイプライン構造を持つが、一部の構成要素で発生した微細な誤差が連鎖的に増幅し、システム全体の致命的な失敗を招く「カスケード故障」が大きな課題となっている。
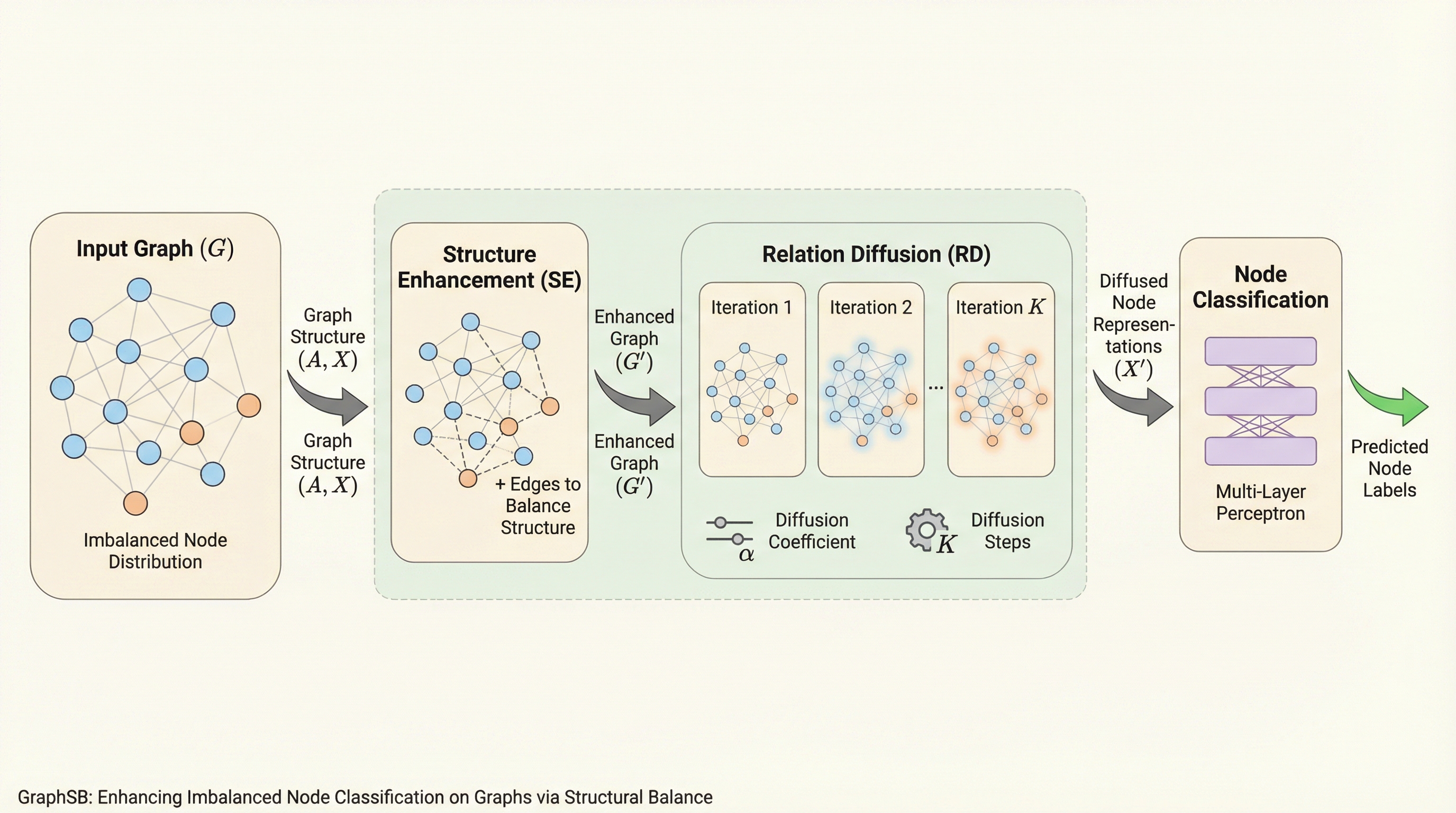
グラフニューラルネットワークにおける不均衡ノード分類の課題に対し、データの量的な調整だけでなく、グラフ構造そのものの不均衡を解消する新しいフレームワーク「GraphSB」が提案されました。 この手法は、決定境界付近の困難なサンプルを特定して少数クラスの接続性を強める「構造強化」と、その情報を広域に伝播させる「関係拡散」の2段階で、構造的な偏りを学習前に最適化する戦略をとります。 8つの主要なデータセットを用いた実験では、既存の最先端手法を大幅に上回る性能を示し、既存モデルに組み込むだけで精度を平均4.57%向上させる汎用性の高いプラグアンドプレイモジュールとしての有効性が証明されました。
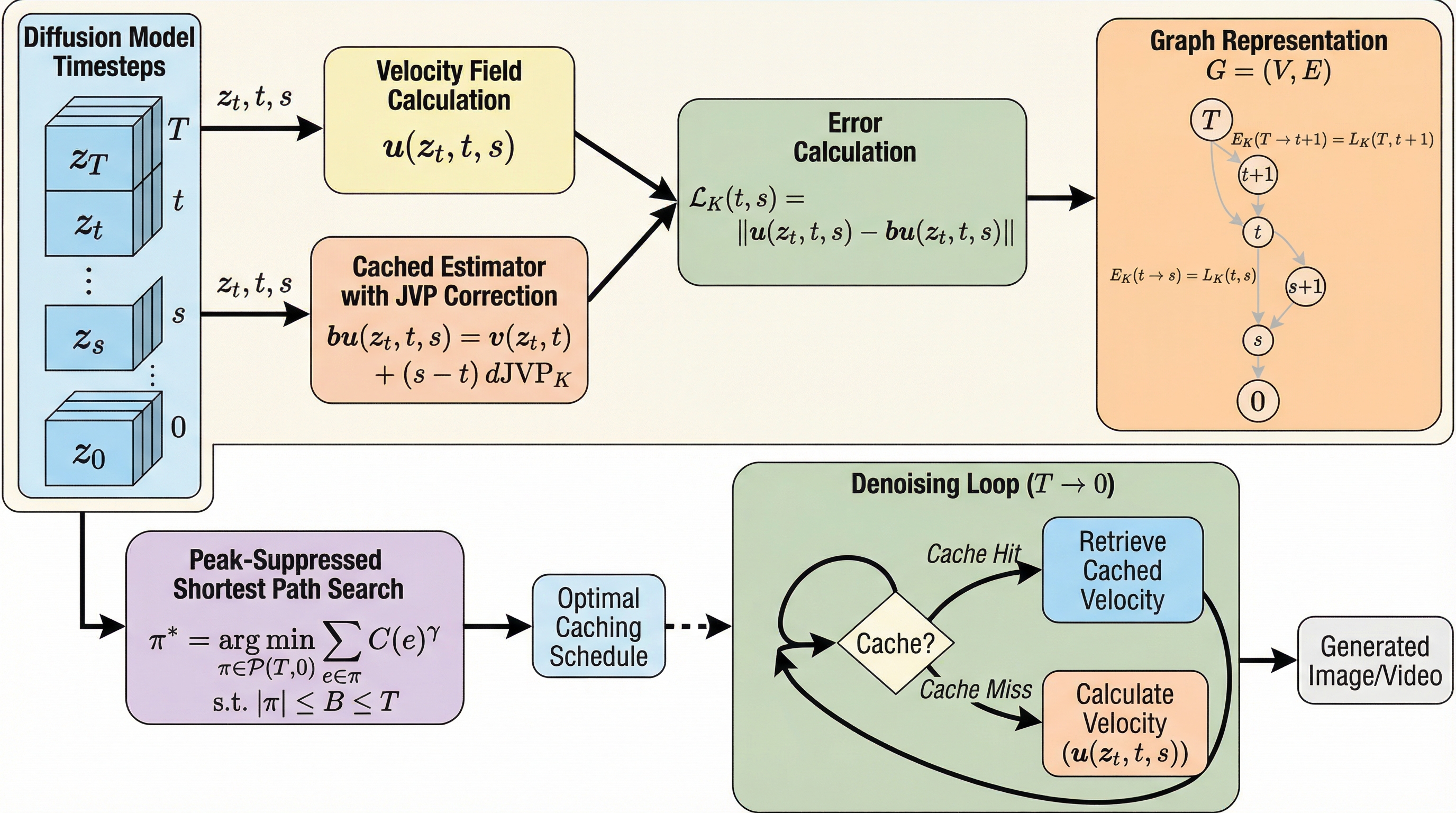
Flow Matchingを用いた生成モデルにおいて、従来のキャッシュ手法が依存していた「瞬間速度」の情報は変動が激しく、高い加速率では軌道の逸脱や誤差の蓄積を招くという課題がありました。本研究が提案する「MeanCache」は、瞬間速度を「区間平均速度」へと変換し、キャッシュされたヤコビアン・ベクトル積(JVP)を用いて軌道を補正することで、学習不要かつ軽量な形で生成品質を維持しながら推論を大幅に高速化します。FLUX.1やHunyuanVideoなどの商用規模モデルを用いた検証では、最大で4.56倍の高速化を達成し、既存の最先端手法と比較しても高い画像・動画品質と構造的一貫性を保持できることが実証されました。
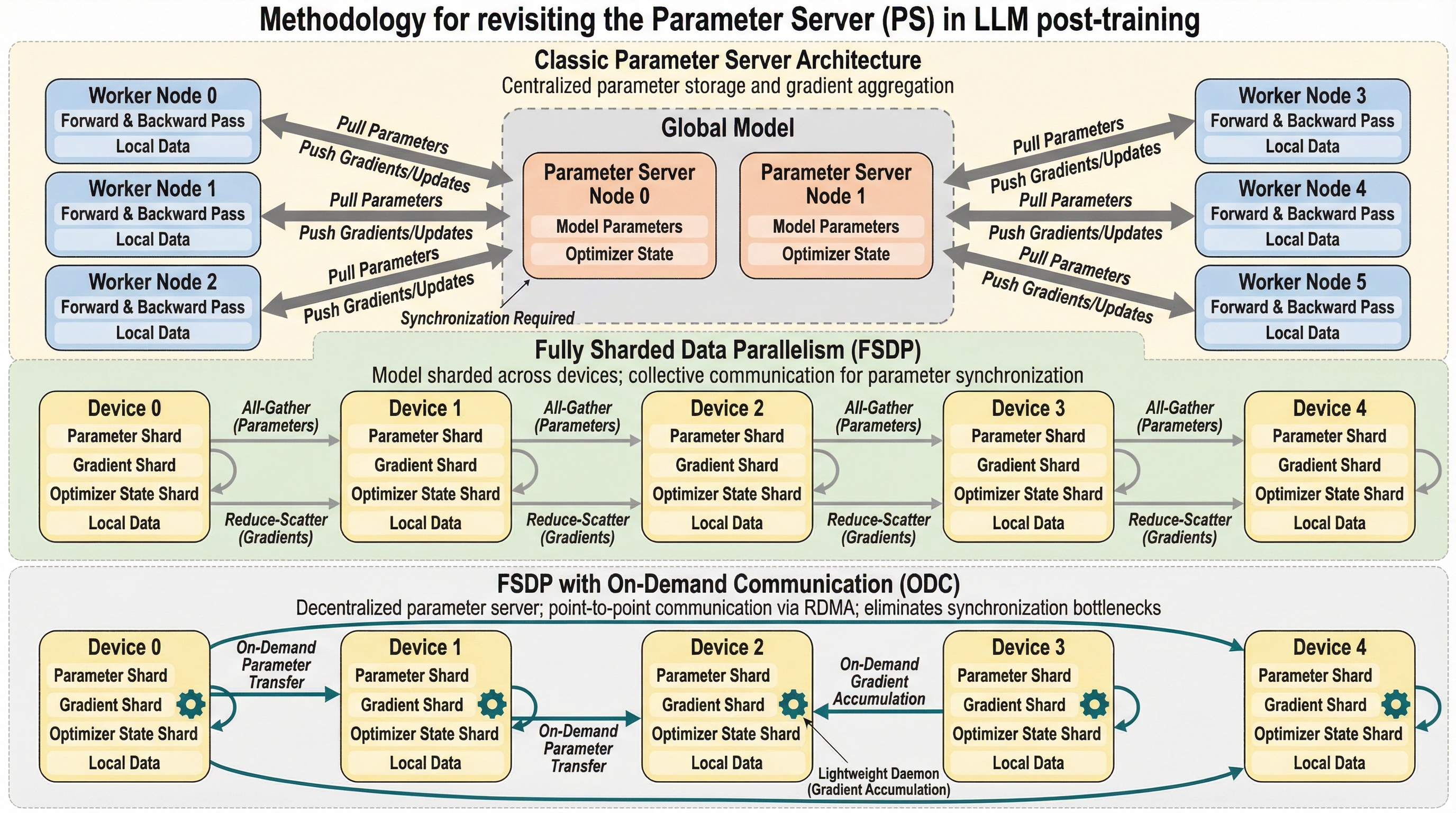
大規模言語モデル(LLM)の事後学習では、入力データのシーケンス長が大きく異なるため、従来の集合通信を用いた分散学習(FSDP)ではデバイス間に深刻な計算負荷の不均衡が生じ、最大50%もの待機時間が発生していました。
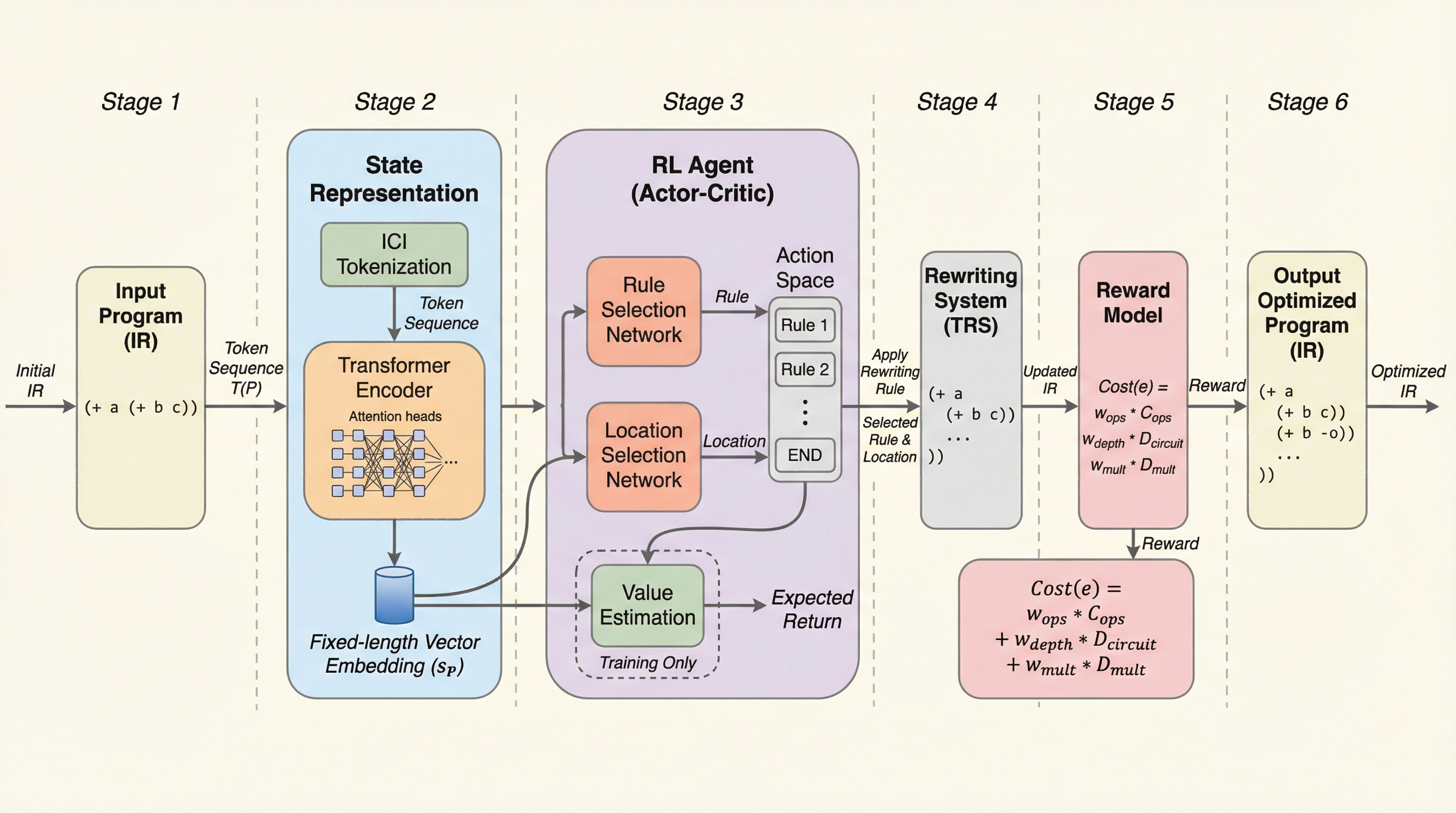
完全準同型暗号(FHE)は暗号化されたまま計算が可能ですが、計算コストが極めて高く、効率的なコード作成には専門知識と複雑な最適化が必要という課題があります。 本研究が提案する「CHEHAB RL」は、深層強化学習(RL)を活用して、スカラーコードの自動ベクトル化や命令レイテンシおよびノイズ増加を抑制する書き換えルールの適用を自動化するフレームワークです。 最新のコンパイラであるCoyoteと比較して、実行速度で5.3倍、ノイズ蓄積量で2.54倍の改善を達成し、コンパイル時間自体も27.9倍高速化することに成功しました。
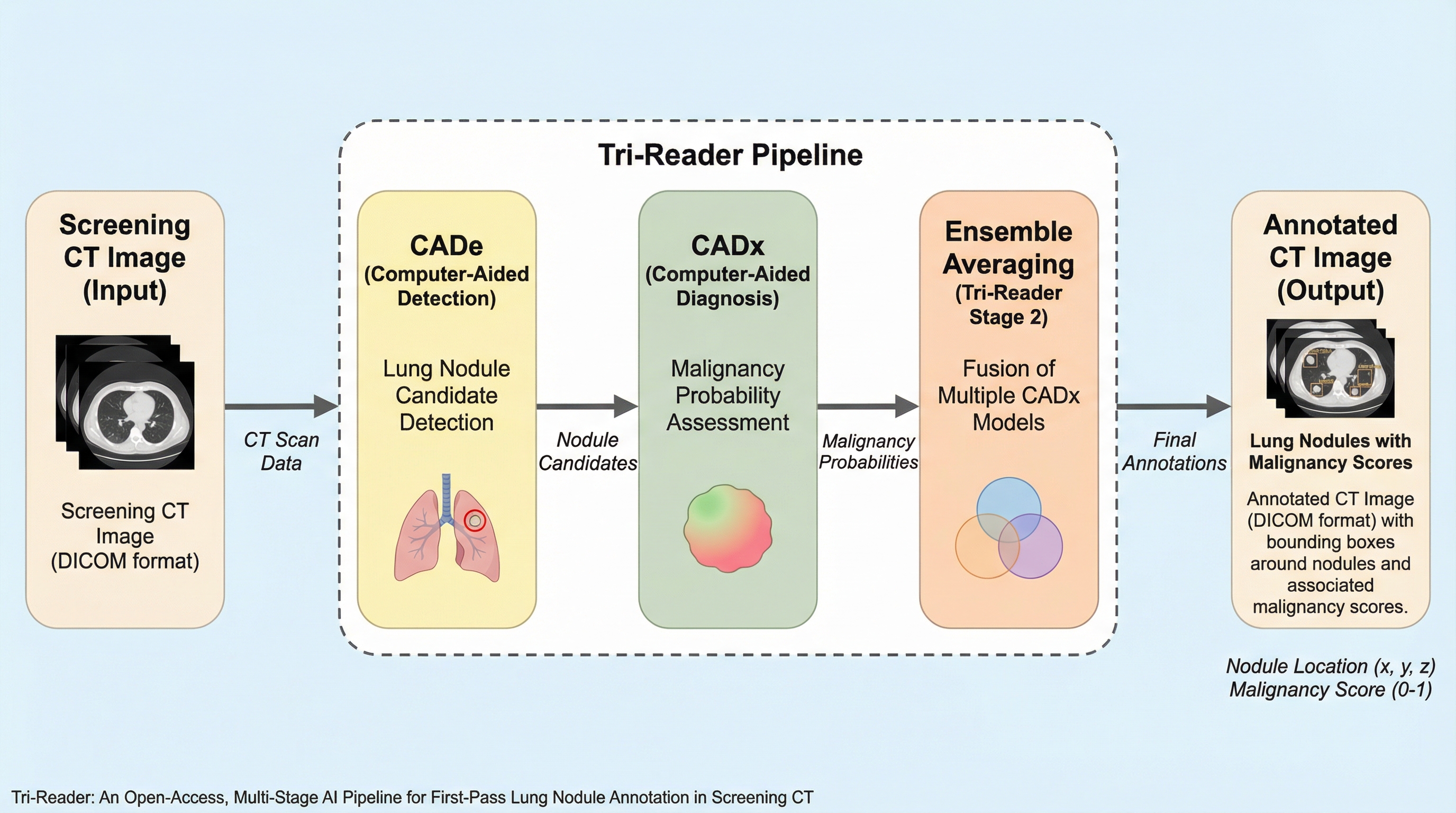
肺がんスクリーニング用AIの開発において、高品質なCT画像のアノテーションには膨大な時間と専門知識、そして高額な費用が必要という課題を解決するため、複数のオープンアクセスモデルを統合した「Tri-Reader」という多段階パイプラインが開発されました。
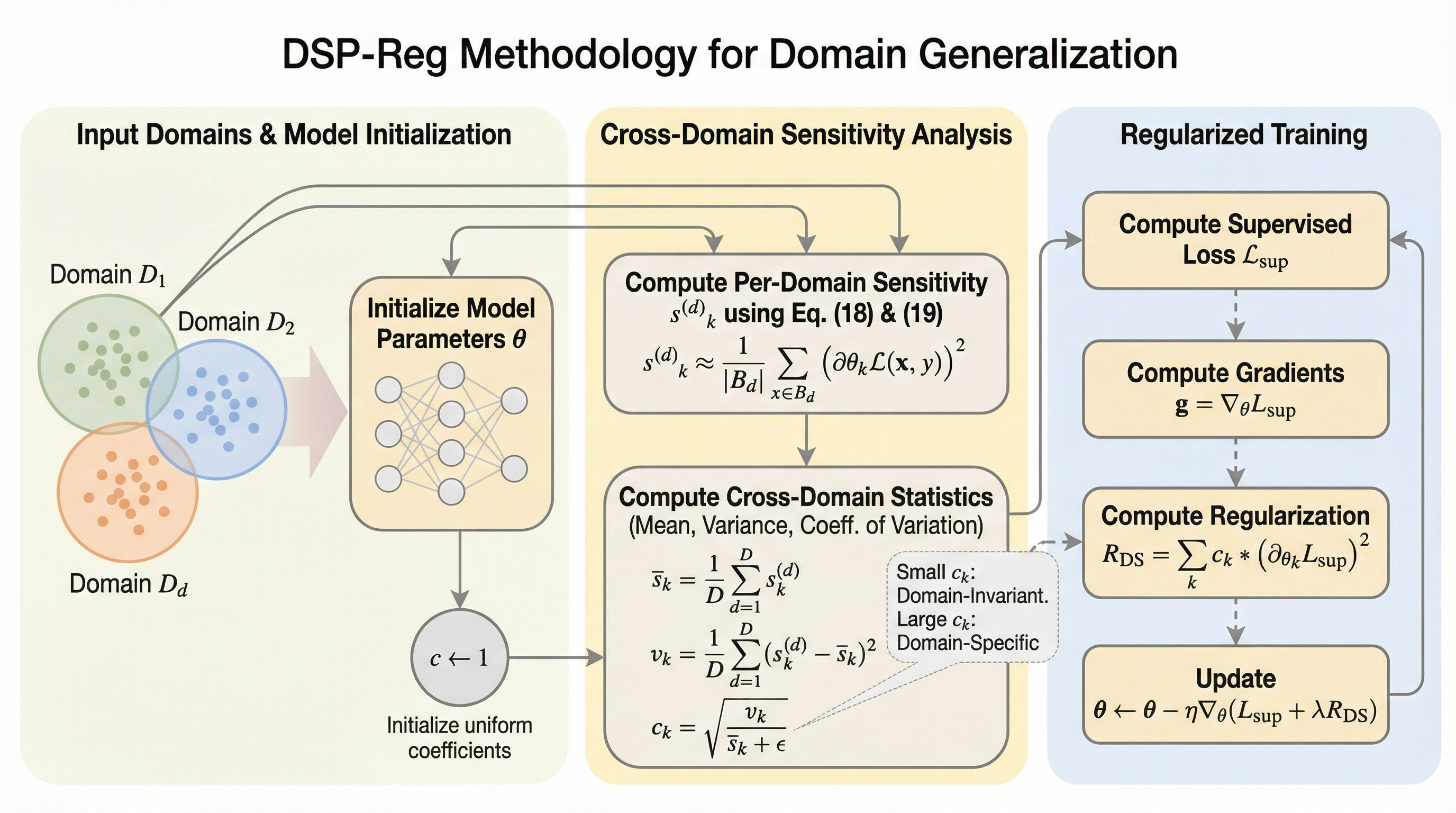
機械学習のドメイン汎化において、従来の特徴量レベルの不変性学習では不十分であったモデル内部のパラメータごとの感度差に着目し、ドメインシフトに対する脆弱性を定量化する新しい理論的枠組みを構築した。
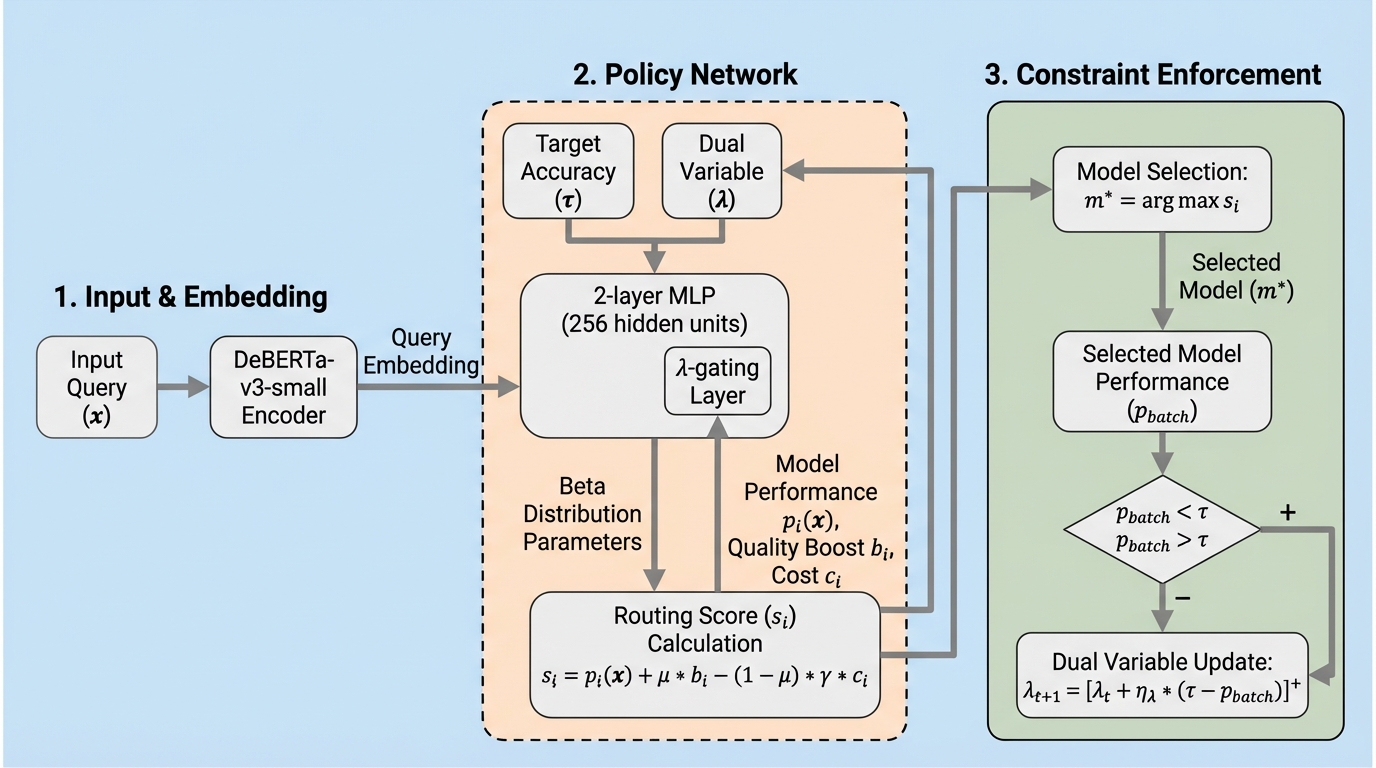
LLM ルーティングの現場では、運用者が本当に指定したいのは「閾値をいくつにするか」ではなく、「最低でもこの精度は守ってほしい」という SLA です。ところが既存ルータは、精度目標を直接受け取れず、事前調整と勘に依存していました。 / PROTEUS は、精度目標 τ を実行時入力として受け取り、ラグランジュ双対制御と強化学習を使って、その τ を満たすようにクエリごとのルーティングを学習する設計です。1つの学習済み方策で τ∈[0.85, 0.95] をまたげる点が核です。 / RouterBench と SPROUT で、精度下限の順守率は 100%、τ と出力品質選好 μ の相関は 0.97〜0.98 を達成し、RouterBench では 90.1% 精度、SPROUT では 94.0% 精度を出しつつ、固定モデル比で最大 89.8% のコスト削減も示しました。