ALRM: ロボット操作のためのエージェント的LLM
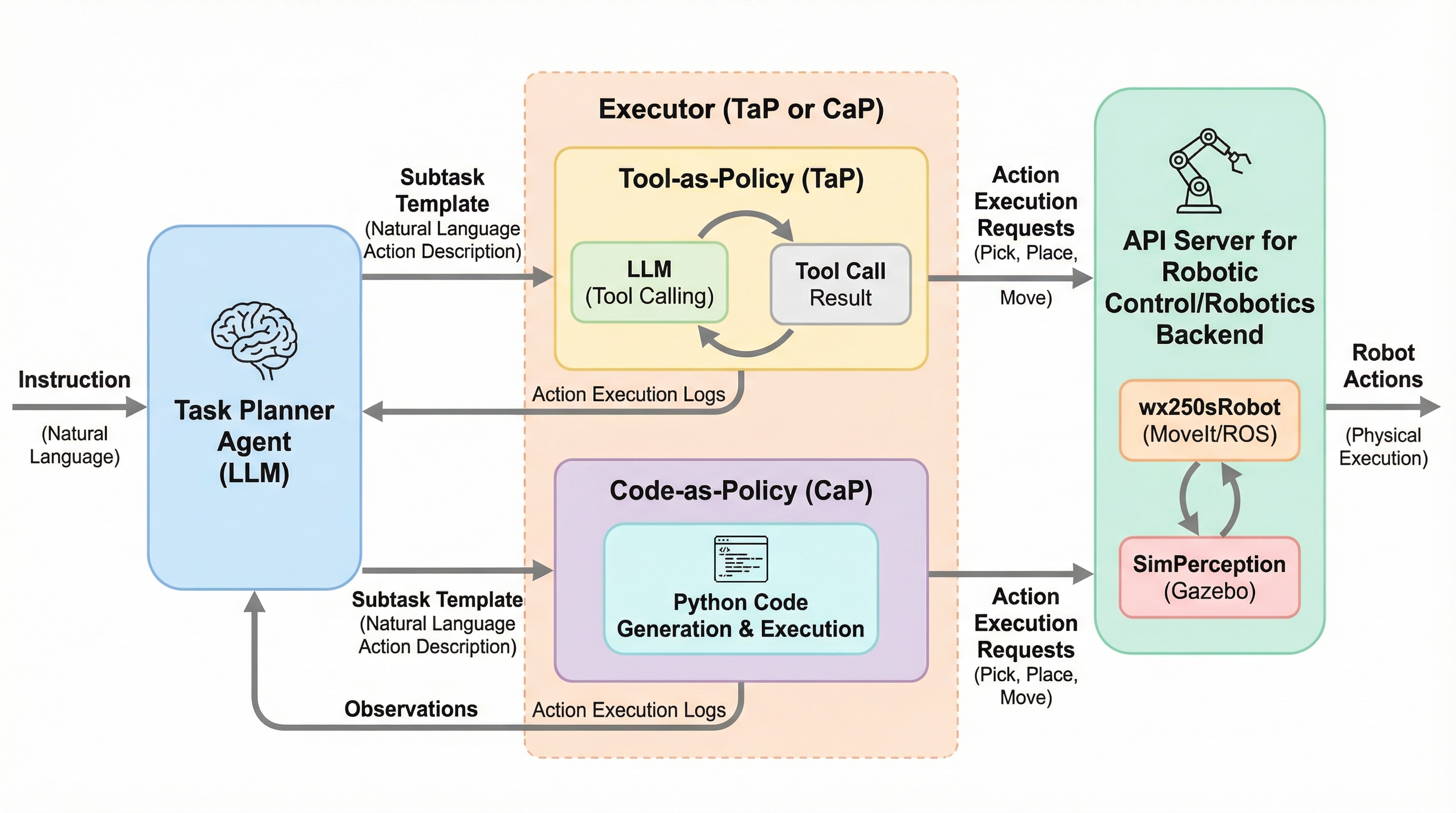
ALRMは、大規模言語モデル(LLM)をロボット操作の計画と実行に統合する新しいエージェント型フレームワークであり、ReAct形式の推論ループを通じて、タスクの分解、実行結果の反映、および計画の修正を動的に行う仕組みを提供します。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
ALRMは、大規模言語モデル(LLM)をロボット操作の計画と実行に統合する新しいエージェント型フレームワークであり、ReAct形式の推論ループを通じて、タスクの分解、実行結果の反映、および計画の修正を動的に行う仕組みを提供します。
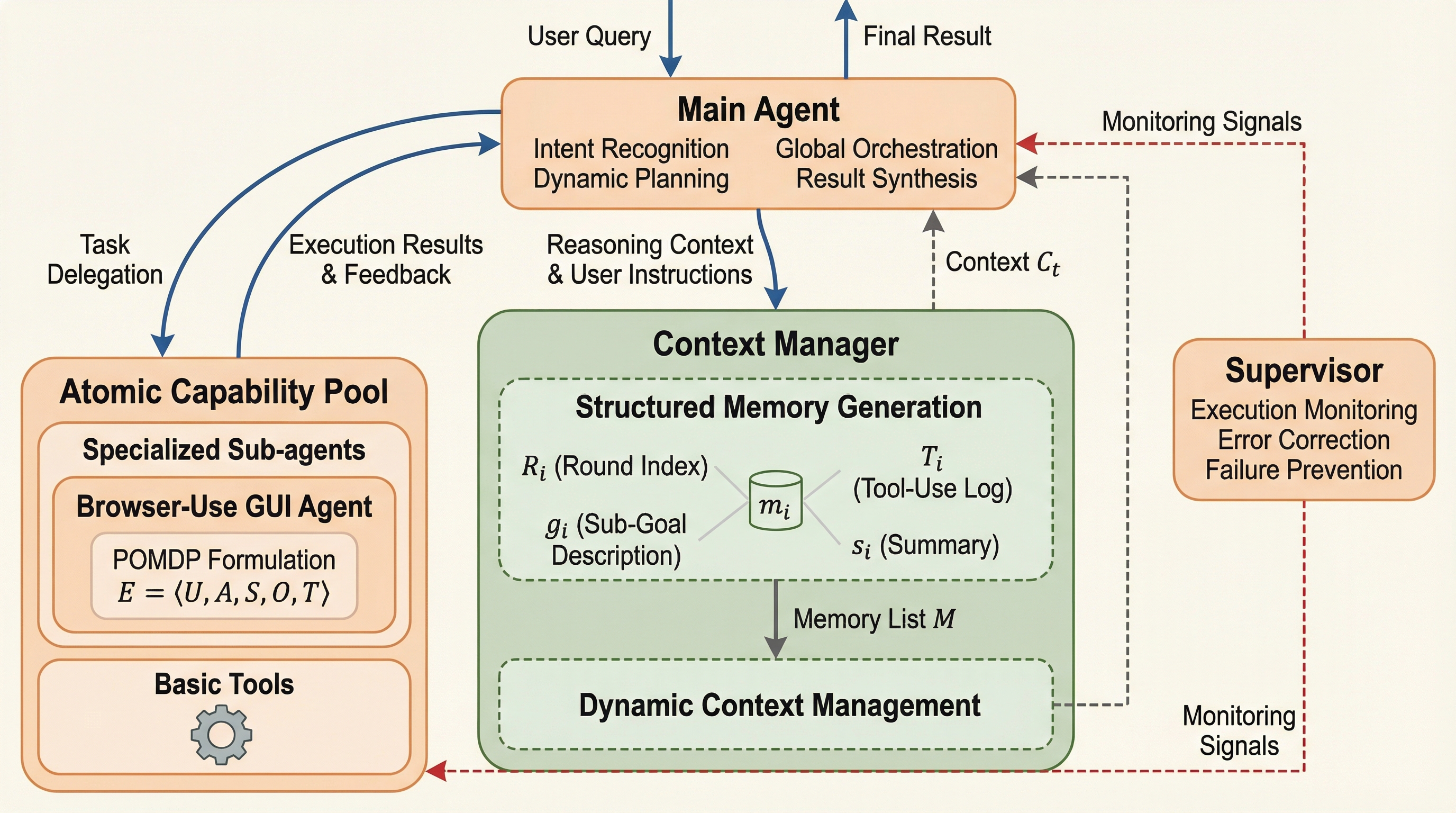
従来の自律型エージェントは、長期間のタスクにおいて文脈のノイズが増大し、些細なエラーが連鎖してシステム全体が停止する脆弱性や、機能拡張の難しさという課題を抱えていた。本報告で提案するYunque DeepResearchは、中央集権的なオーケストレーション、動的な文脈管理、能動的な監視モジュールを組み合わせた階層的かつモジュール化された堅牢なフレームワークである。 このシステムは、メインエージェントがタスクを分解して専門的なサブエージェントやツール群に割り当てる仕組みを持ち、完了した中間目標を意味的な要約に圧縮することで情報の過負荷を防ぎつつ、異常検知による自己修正を実現している。ブラウザ操作やデータ分析に特化したサブエージェントを統合することで、複雑で自由度の高いリサーチタスクにおいて高い適応能力を発揮する。 検証ではGAIAやHumanity’s Last Examなどの複数のベンチマークにおいて世界最高水準の性能を達成しており、再現可能な実装コードや応用事例を含めてオープンソースとして公開されることで、コミュニティ全体の研究開発を促進することを目指している。
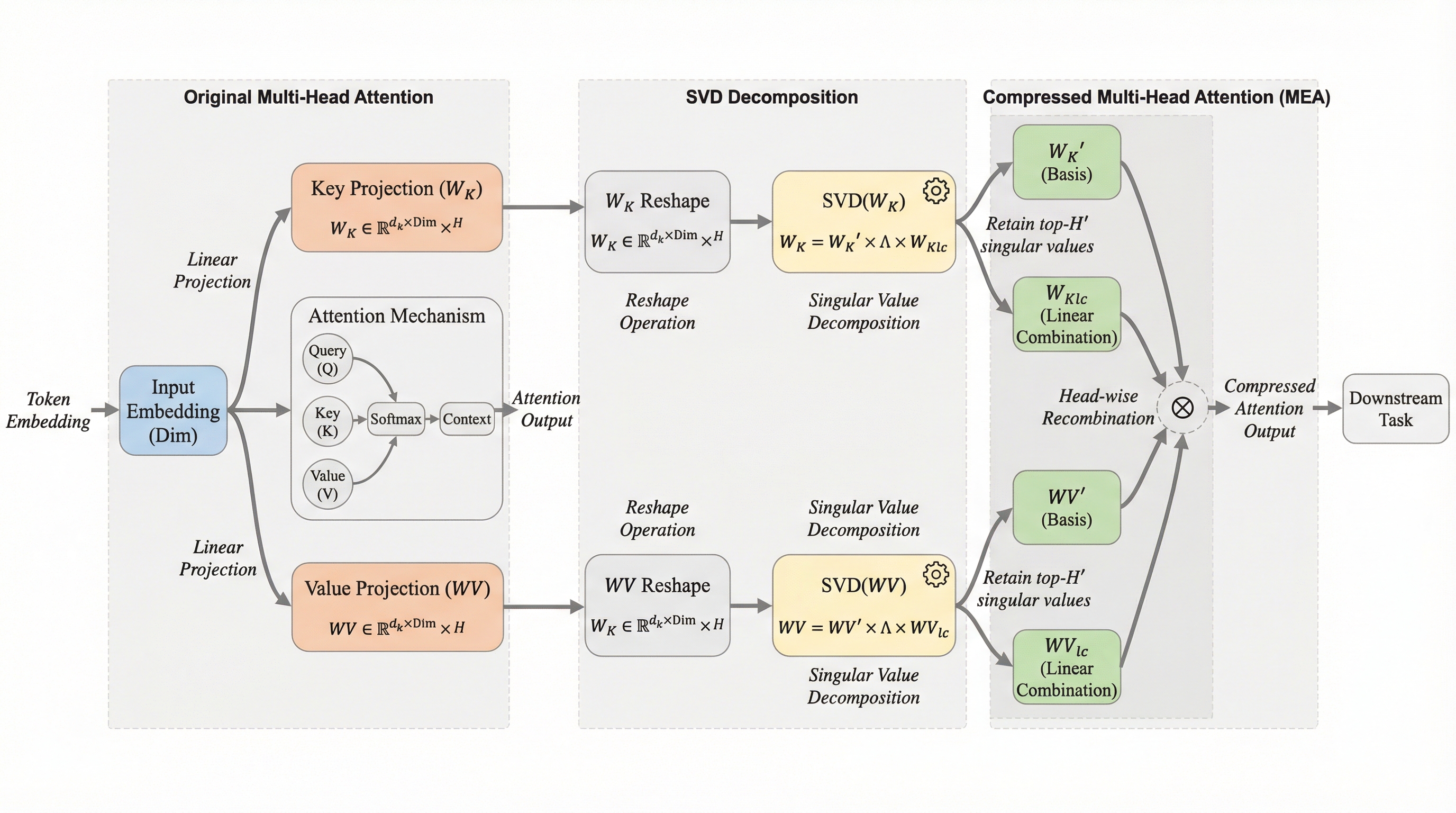
従来のTransformerが抱えていたアテンションヘッド間の独立性という制約を打破するため、ヘッド間の明示的な相互作用を可能にする「Multi-head Explicit Attention(MEA)」を提案し、学習の安定性と表現力を大幅に向上させた。
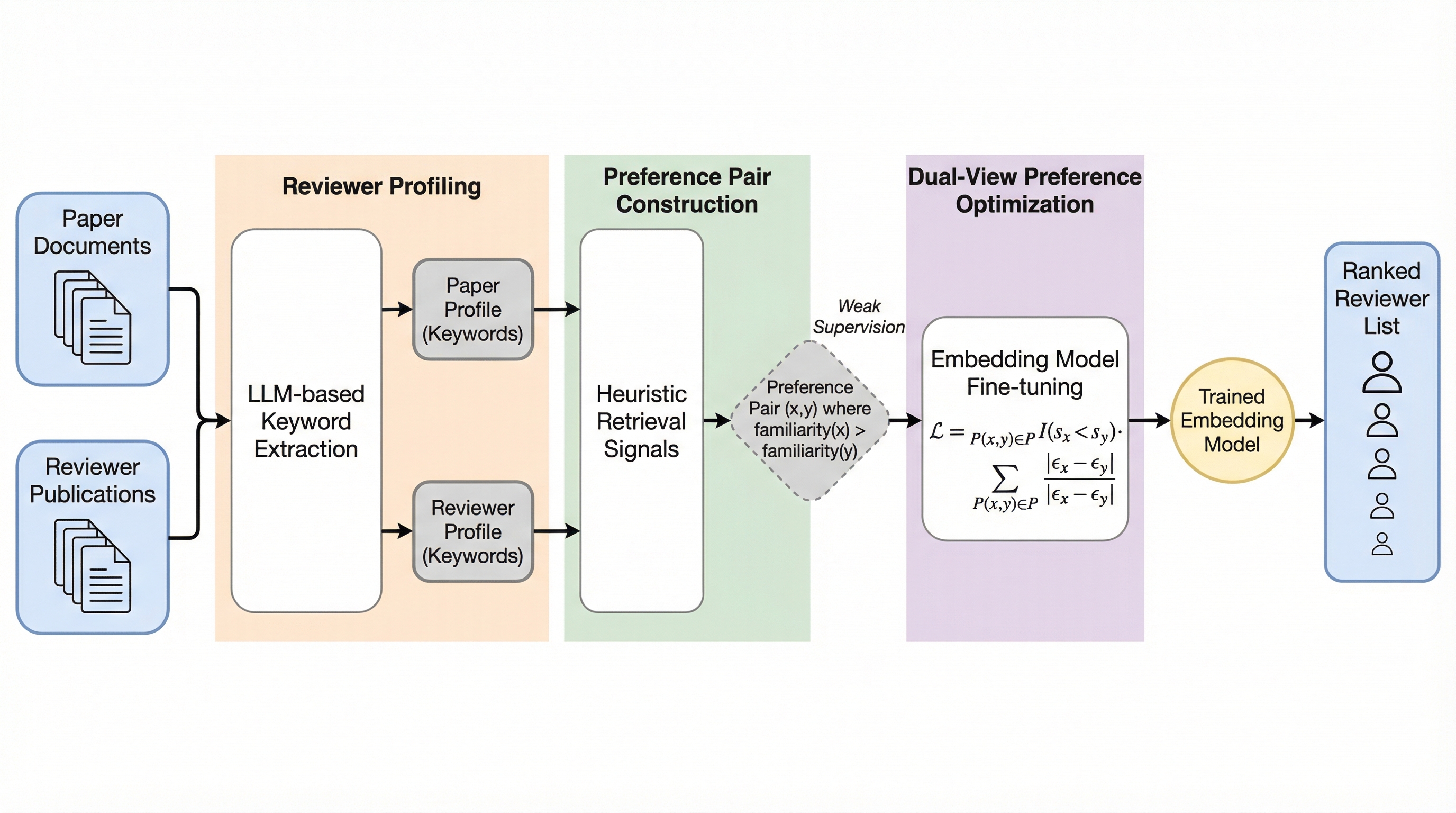
大規模言語モデル(LLM)の急速な発展に伴う研究トピックの変遷に対応するため、2024年から2025年の最新論文と査読者の自己申告による専門性評価(1,055件)を含む高精度なベンチマーク「LR-bench」を構築しました。
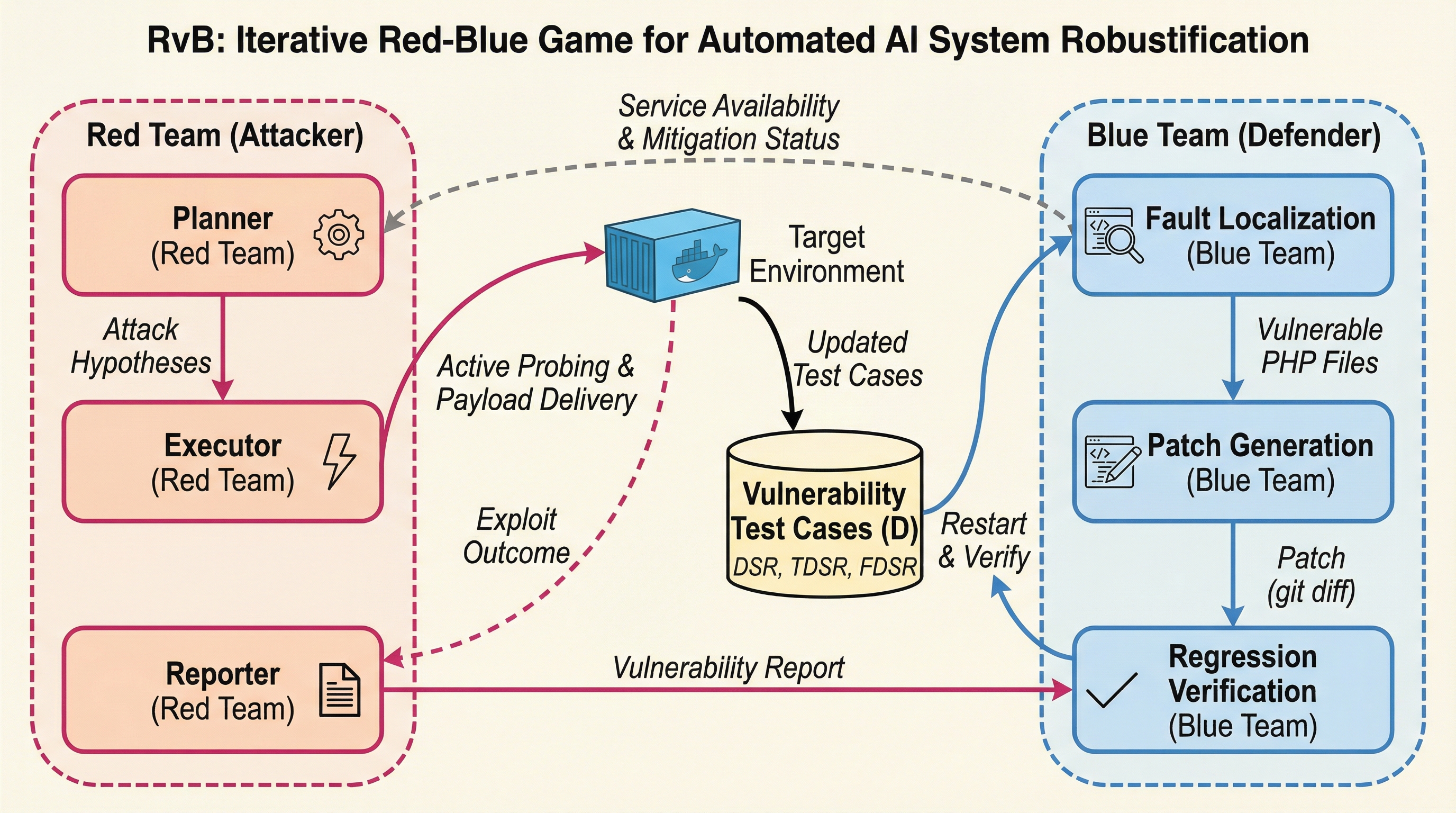
RvBは、大規模言語モデルの安全性を飛躍的に高めるために開発された、学習や微調整を一切必要としない革新的な自動堅牢化フレームワークであり、攻撃を担うレッドチームと防御を担うブルーチームが対話的に試行錯誤を繰り返す「不完全情報ゲーム」として設計されている。
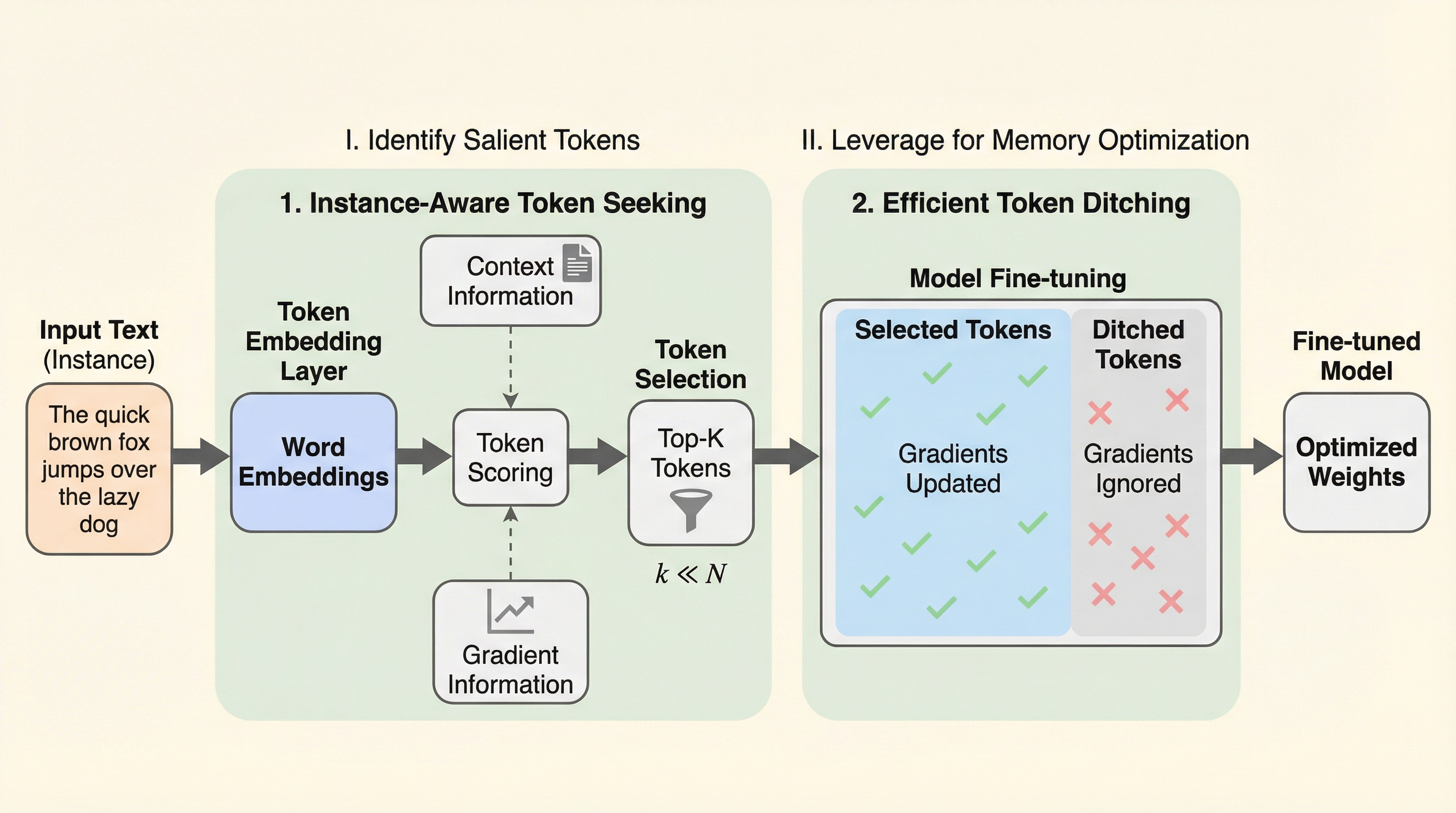
大規模言語モデルのファインチューニングにおいて、メモリ消費の最大87%を占めるアクティベーションの課題を解決するため、各データの文脈と勾配情報から重要なトークンのみを選択して学習する「TOKENSEEK」が提案されました。 この手法は、Llama3.2 1Bにおいて元のメモリのわずか14.8%(2.

従来の立場検出は事前に定義された静的なターゲットを前提としていたが、本研究では現実のソーシャルメディアの複雑さに対応するため、ターゲットの事前知識なしにテキストから複数のターゲットと立場のペアを自動識別する「DGTA」という新しいタスクを定義し提案した。

本研究は、科学分野の複雑なマルチホップ質問応答において、反復的な検索と推論のループが、理想的な静的根拠(ゴールドコンテキスト)を上回る性能を発揮することを解明しました。11種類の最新大規模言語モデルを用いた実験の結果、反復的RAGは非推論特化型モデルにおいて最大25.