RATE:査読システムにおける専門性ランキングのための査読者プロファイリングとアノテーション不要の訓練
大規模言語モデル(LLM)の急速な発展に伴う研究トピックの変遷に対応するため、2024年から2025年の最新論文と査読者の自己申告による専門性評価(1,055件)を含む高精度なベンチマーク「LR-bench」を構築しました。
TL;DR(結論)
大規模言語モデル(LLM)の急速な発展に伴う研究トピックの変遷に対応するため、2024年から2025年の最新論文と査読者の自己申告による専門性評価(1,055件)を含む高精度なベンチマーク「LR-bench」を構築しました。 従来の論文単位の類似度計算ではなく、LLMを用いて査読者の過去業績からキーワードを抽出・統合して自然言語の「査読者プロフィール」を作成し、BM25を用いた擬似ラベルによる自己教師あり学習を行う手法「RATE」を提案しました。 提案手法は、人手によるラベル付けに頼ることなく、論文と査読者の専門性を直接マッチングさせることで、従来の埋め込みモデルやヒューリスティックな手法を上回る最新の最高性能(SOTA)を達成し、特定の論文に引きずられるプロフィールの偏り問題を解決しました。
なぜこの問題か
現代の科学研究において、査読システムは投稿論文の評価、建設的なフィードバックの提供、そして学術的な誠実さを守るための礎石となっています。専門知識を持つ査読者は論文を大幅に改善させることができますが、ドメインの専門知識が不足している査読者が割り当てられた場合、著者と査読者の双方にとって時間の浪費となる可能性があります。特にコンピュータサイエンス、とりわけ人工知能(AI)の分野では、近年の投稿数が急増しており、手動での査読者割り当てはますます困難になっています。そのため、効果的な査読者割り当てアルゴリズムの開発が不可欠となっています。 しかし、現在の査読者割り当ての分野には、大きく分けて二つの重要な課題が存在します。第一の課題は「評価の危機」です。これは、高精度でオープンソースかつ最新のベンチマークが不足していることを指します。AIや自然言語処理(NLP)の研究、特に大規模言語モデル(LLM)時代における爆発的な増加は、深刻な時間的変化をもたらしました。2023年以前に作成された既存のベンチマークの多くは、現在の研究トピックを反映できておらず、分布外(OOD)の問題に直面しています。…
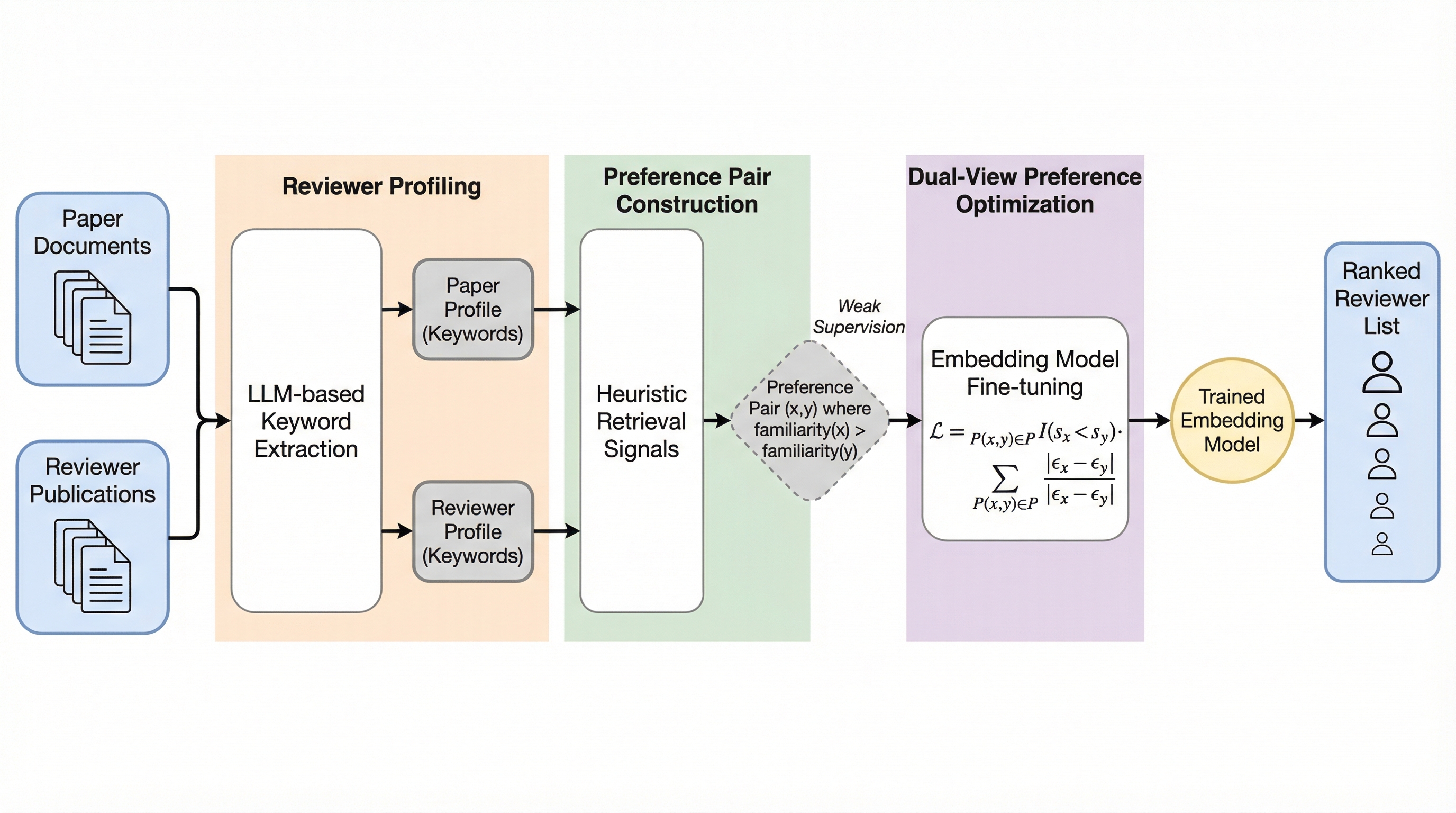
核心:何を提案したのか
本研究では、上述した二つの課題を解決するために、新しいベンチマークである「LR-bench」と、査読者中心のランキングフレームワークである「RATE」を提案しました。まず、評価の危機に対処するため、最新の研究動向を反映した高精度なベンチマークであるLR-benchを構築しました。このベンチマークは、2024年から2025年の主要なAIおよびNLPの会議から収集された論文を中心に構成されており、近年のLLM研究の急増によって生じた内容のギャップを直接埋めるものです。データの品質を保証するために、多段階のキュレーションプロセスを採用しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related