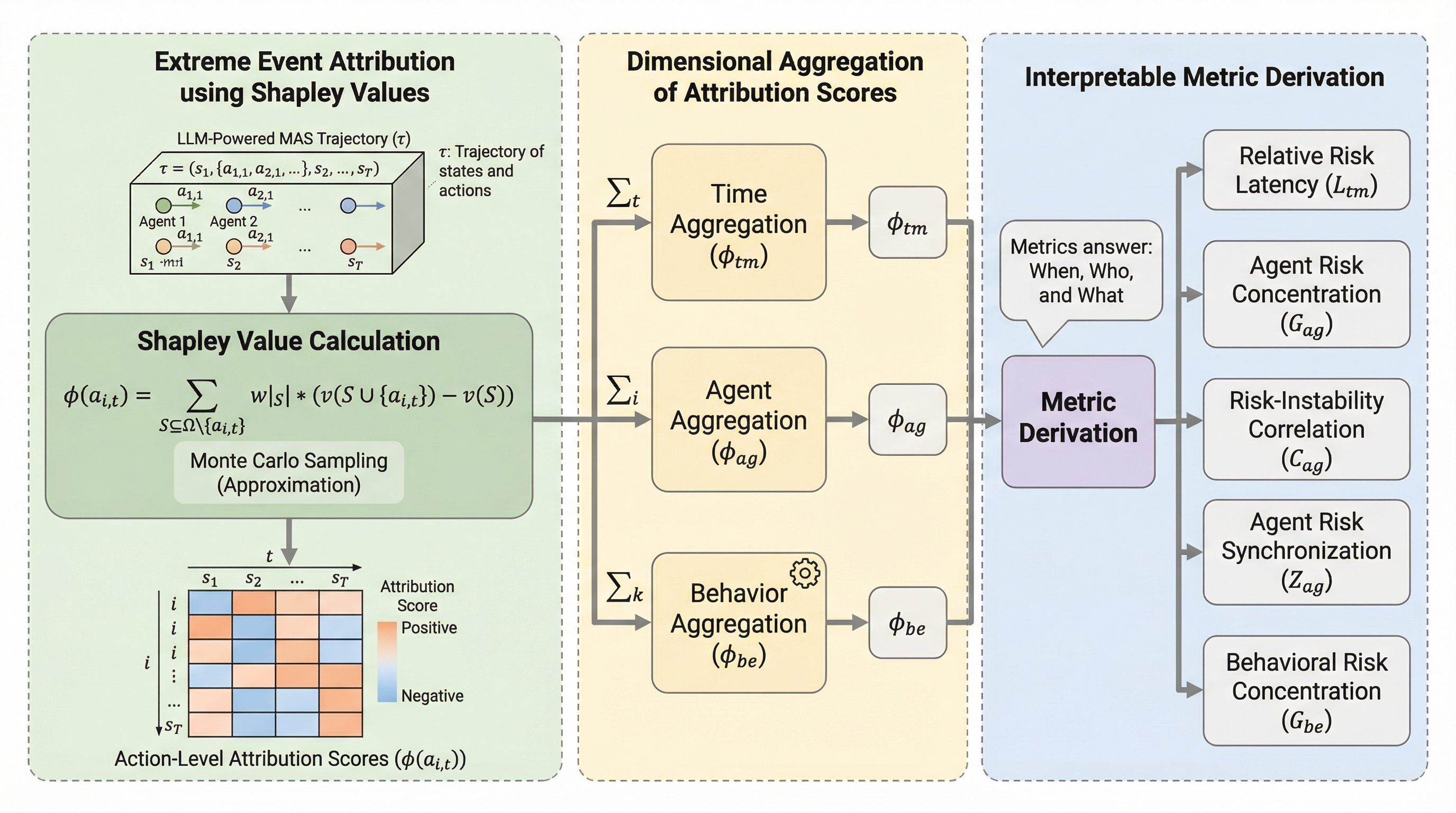
マルチエージェントシステムにおける創発的極端現象の解釈
大規模言語モデル(LLM)を用いたマルチエージェントシステムで発生する、予測困難な「ブラックスワン」現象を解明するため、世界で初めて「時間・個人・行動」の3次元からリスクを定量化する解釈フレームワークを提案しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)を用いたマルチエージェントシステムで発生する、予測困難な「ブラックスワン」現象を解明するため、世界で初めて「時間・個人・行動」の3次元からリスクを定量化する解釈フレームワークを提案しました。
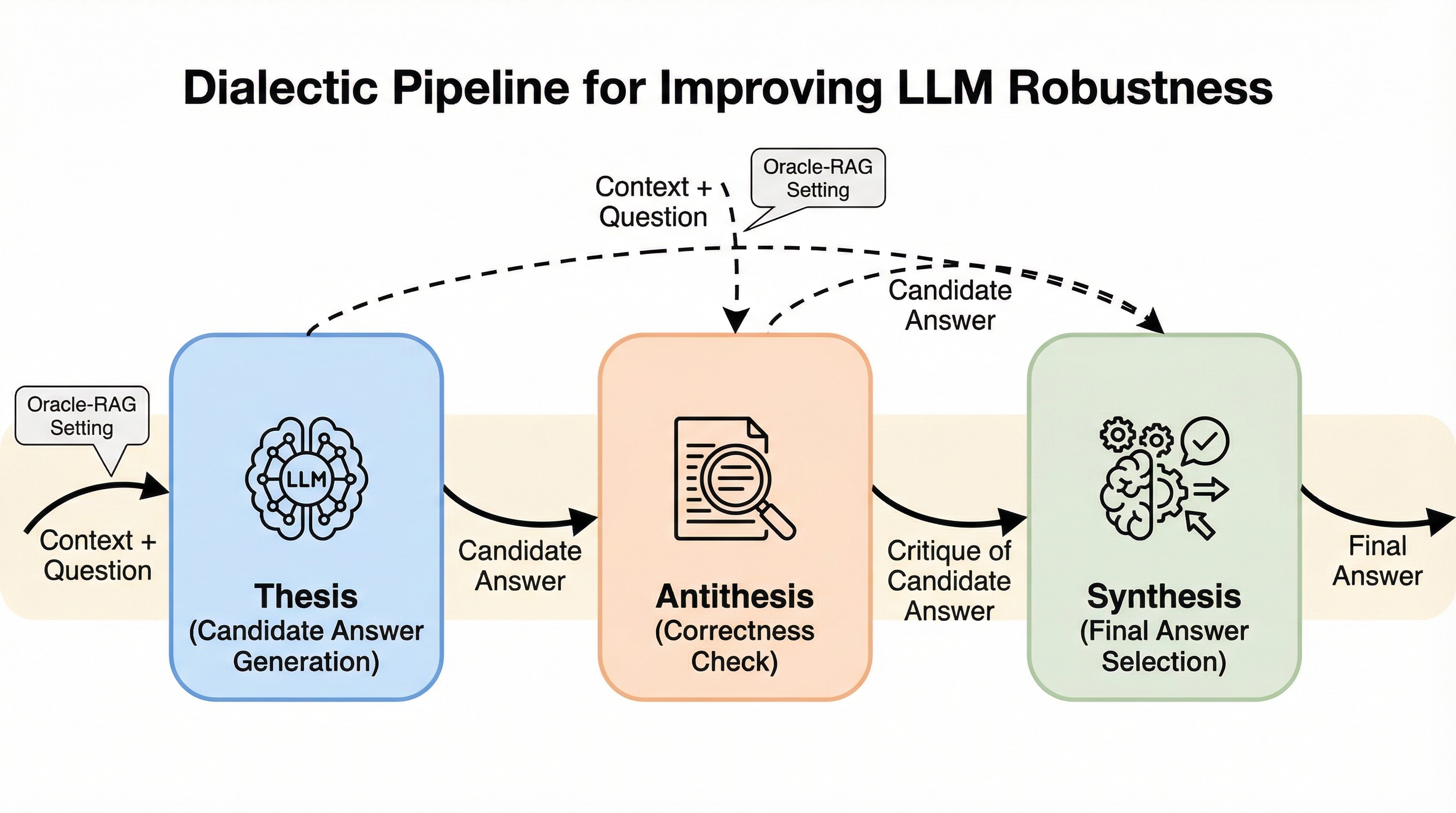
大規模言語モデル(LLM)の課題であるハルシネーションを抑制するため、ヘーゲル哲学の弁証法に着想を得た「対話的パイプライン(Dialectic Pipeline)」が提案されました。この手法は、モデルが「正(Thesis)」「反(Antithesis)」「合(Synthesis)」という3つの段階を経て自己対話を行うことで、初期の回答を批判的に検討し、最終的な結論を洗練させる仕組みです。 検証の結果、複数の知識源を統合する複雑なマルチホップ質問応答タスクにおいて、標準的な回答手法や既存の「思考の連鎖(Chain-of-Thought)」を大幅に上回る精度と信頼性を達成しました。また、外部知識を活用するRAG環境において、情報の要約や勾配ベースのフィルタリングを組み合わせることで、モデルの規模や種類を問わず回答の質がさらに向上することが確認されました。 本研究は、追加学習や特定のドメインへの特化を必要とせず、プロンプトの構造を工夫するだけでモデルの汎用性を維持したまま堅牢性を高められることを示しています。特に、推論能力と内容抽出能力の両方が求められる多段階の質問応答において、自己修正プロセスが極めて有効であることを実証し、実用的なフレームワークを提供しています。
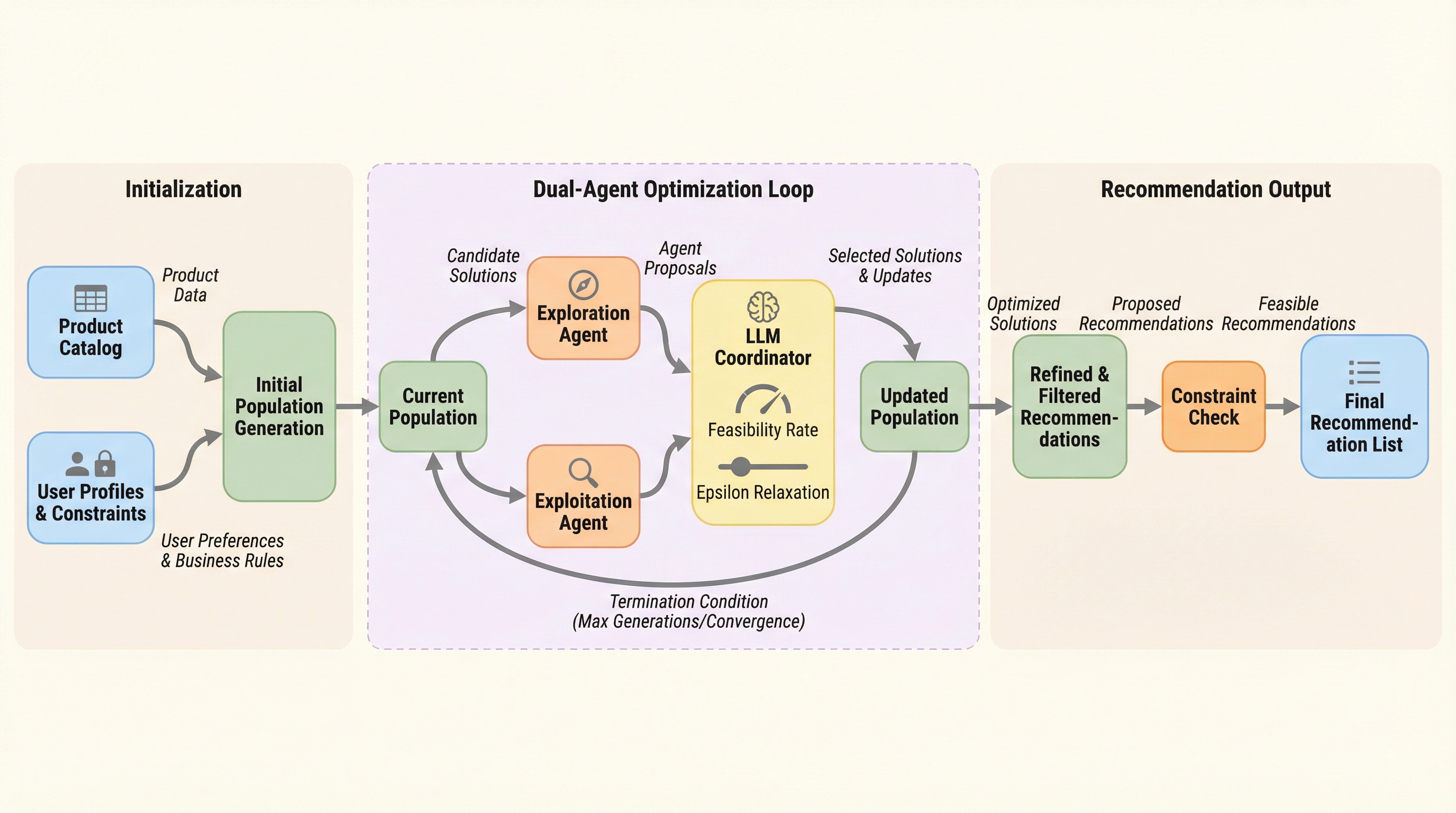
従来の推薦システムは、精度向上とビジネス上の制約(公平性や在庫露出など)の両立を「ソフトな罰則」として扱ってきたため、実運用で制約違反が頻発するという課題を抱えていました。 本研究が提案する「DualAgent-Rec」は、LLMを最適化のオーケストレーター(調整役)として配置し、精度を追求するエージェントと多様性を探索するエージェントを動的に制御する二重構造のフレームワークです。 Amazonのデータセットを用いた実験では、ビジネス制約を100%遵守しながら、既存の手法と比較してパレート・ハイパーボリュームを4〜6%向上させ、実用的な精度と多様性のトレードオフを実現しました。
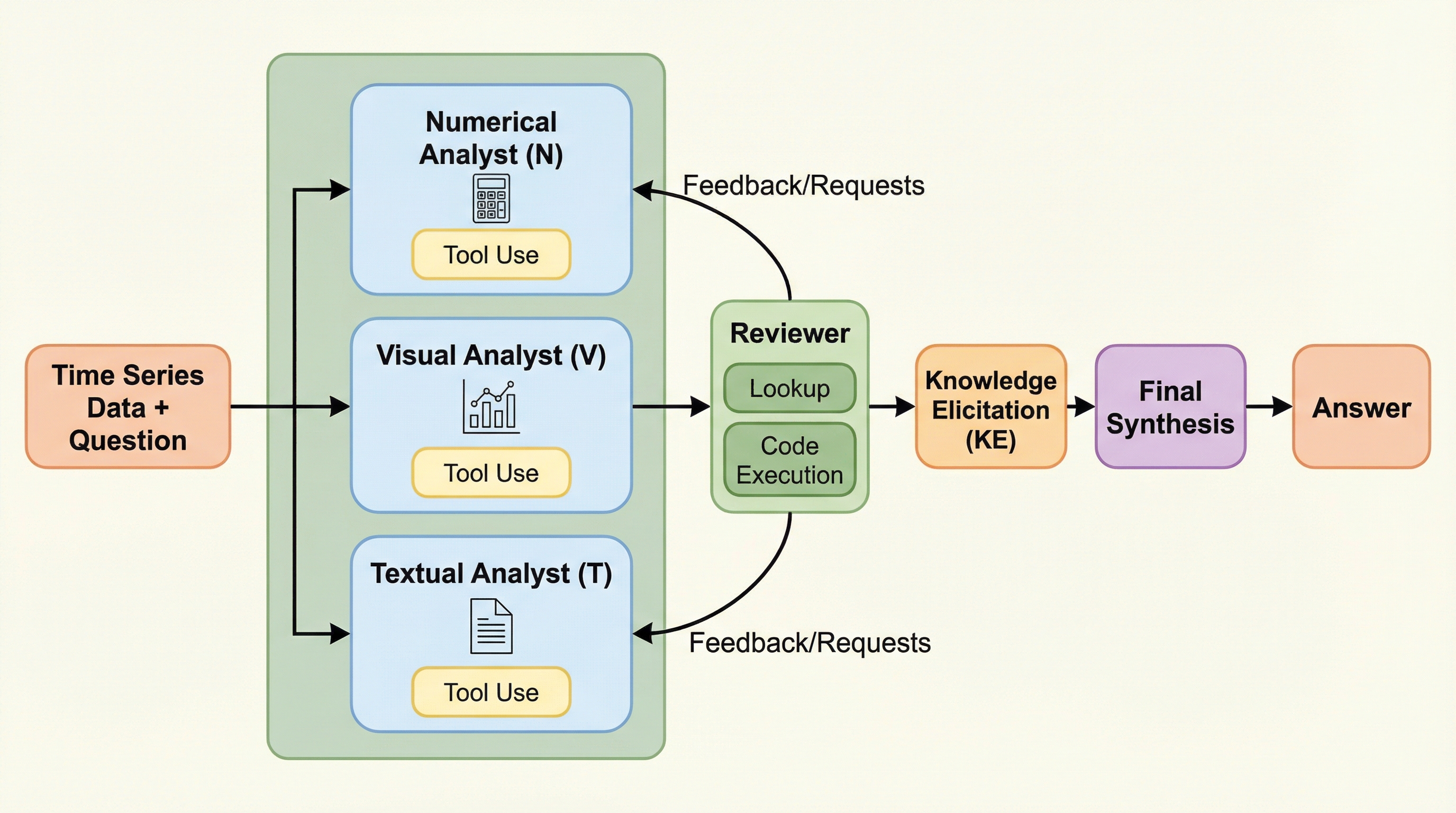
大規模言語モデル(LLM)を用いた時系列データ推論において、数値の正確性の欠如やモダリティ間の干渉、そして体系的な統合の難しさが大きな課題となっている。本研究では、テキスト、視覚、数値の各モダリティに特化した専門エージェントが協調して議論を行う、ゼロショット時系列推論のための新しいフレームワーク「TS-Debate」を提案する。 この手法は、事前にドメイン知識を抽出した上で、各エージェントが独自の視点から観察と推論を行い、その主張をコード実行や数値検索ツールを備えたレビュー担当者が検証する仕組みを持つ。検証・対立・較正(VCC)プロトコルにより、モダリティ間の矛盾を明示的に解消し、数値的なハルシネーションを抑制しながら、信頼性の高い回答を導き出す。 3つの公開ベンチマークに含まれる20のタスクで評価を行った結果、既存の強力なベースラインと比較して大幅な性能向上を達成し、特に時系列データの構造理解と数値的忠実度の両立において優れた成果を示した。タスク固有の微調整を必要とせず、推論時の構造化された対話のみで、複雑な時系列推論を堅牢に実行できることが実証された。