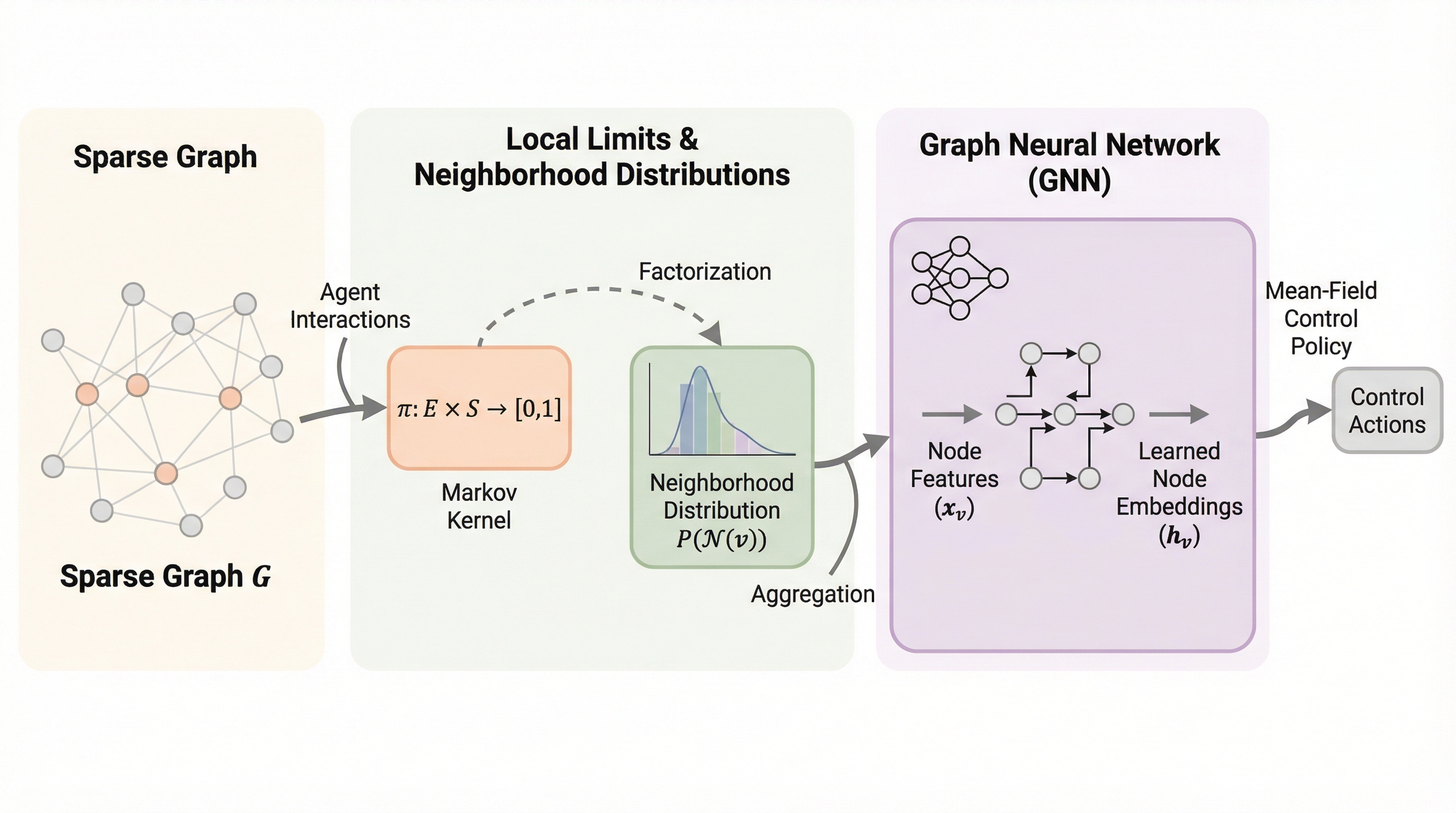
希薄なグラフ上での平均場制御:局所極限から近傍分布を介したGNNへの展開
大規模マルチエージェントシステムにおいて、従来の平均場制御が前提としていた「全エージェント間の一様な相互作用」という制約を打破し、現実的な希薄グラフ上での制御を可能にする理論的枠組み「Sparse-MFC」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模マルチエージェントシステムにおいて、従来の平均場制御が前提としていた「全エージェント間の一様な相互作用」という制約を打破し、現実的な希薄グラフ上での制御を可能にする理論的枠組み「Sparse-MFC」が提案されました。
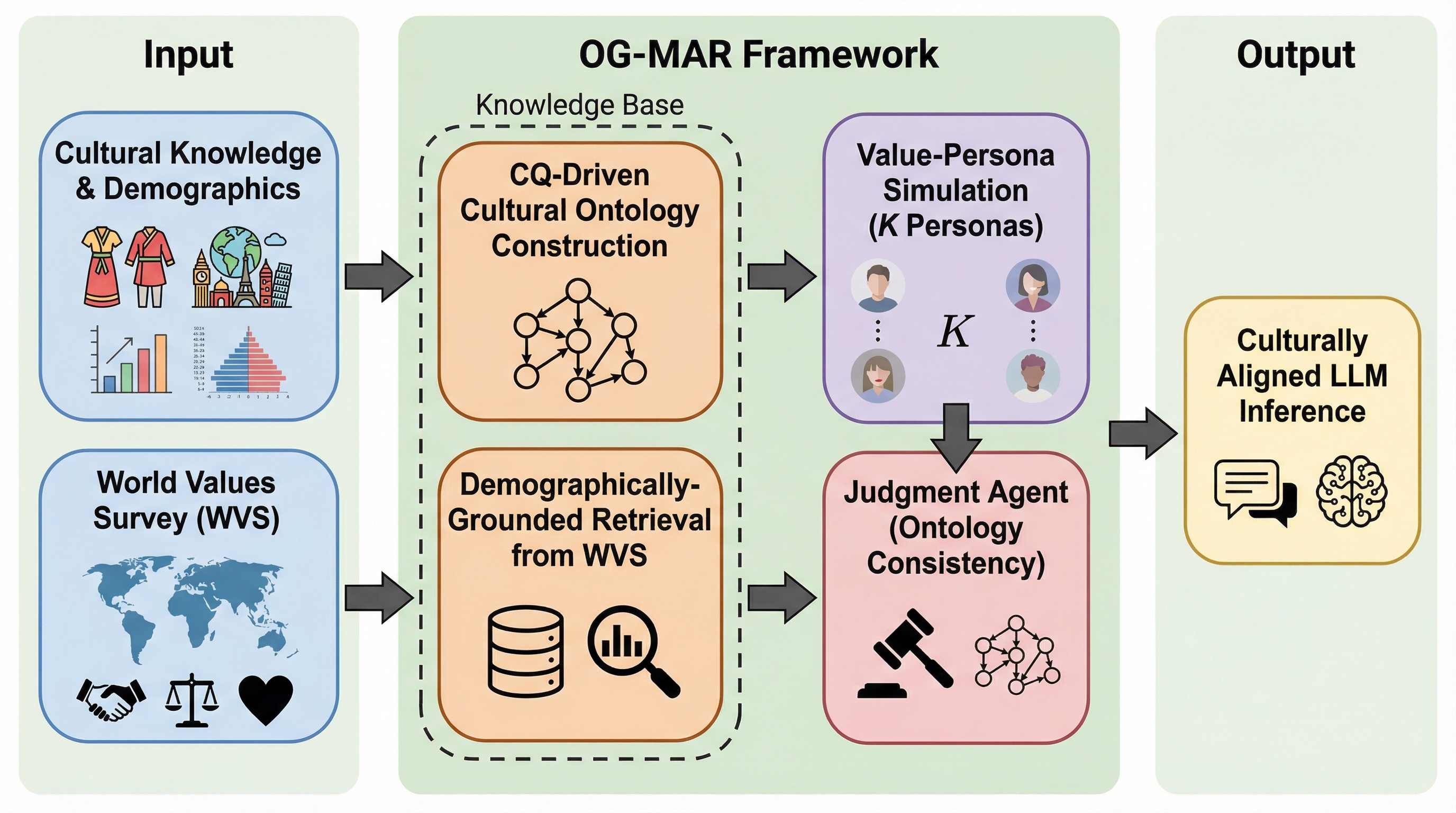
大規模言語モデル(LLM)が欧米中心のデータに偏り、多様な文化圏の価値観を正確に反映できない問題を解決するため、世界価値観調査(WVS)のデータと構造化された知識表現であるオントロジーを組み合わせた新しい推論フレームワーク「OG-MAR」が提案されました。
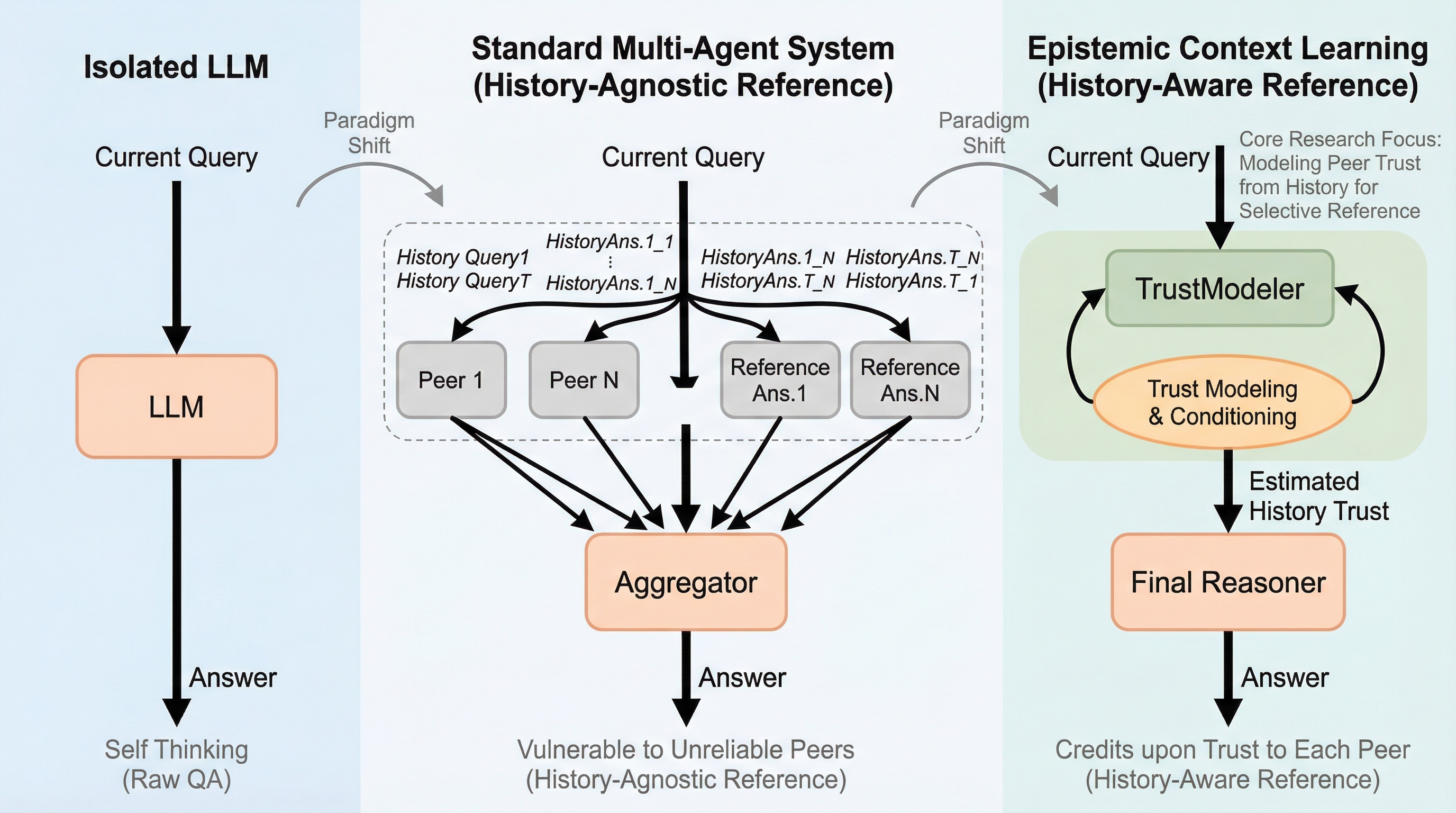
LLMベースのマルチエージェントシステムにおいて、エージェントが誤った情報を持つ他者に盲目的に同調してしまう脆弱性を解決するため、過去の対話履歴から他者の信頼性を評価して情報を選択的に参照する「履歴を考慮した参照」という新しいパラダイムを提案した。
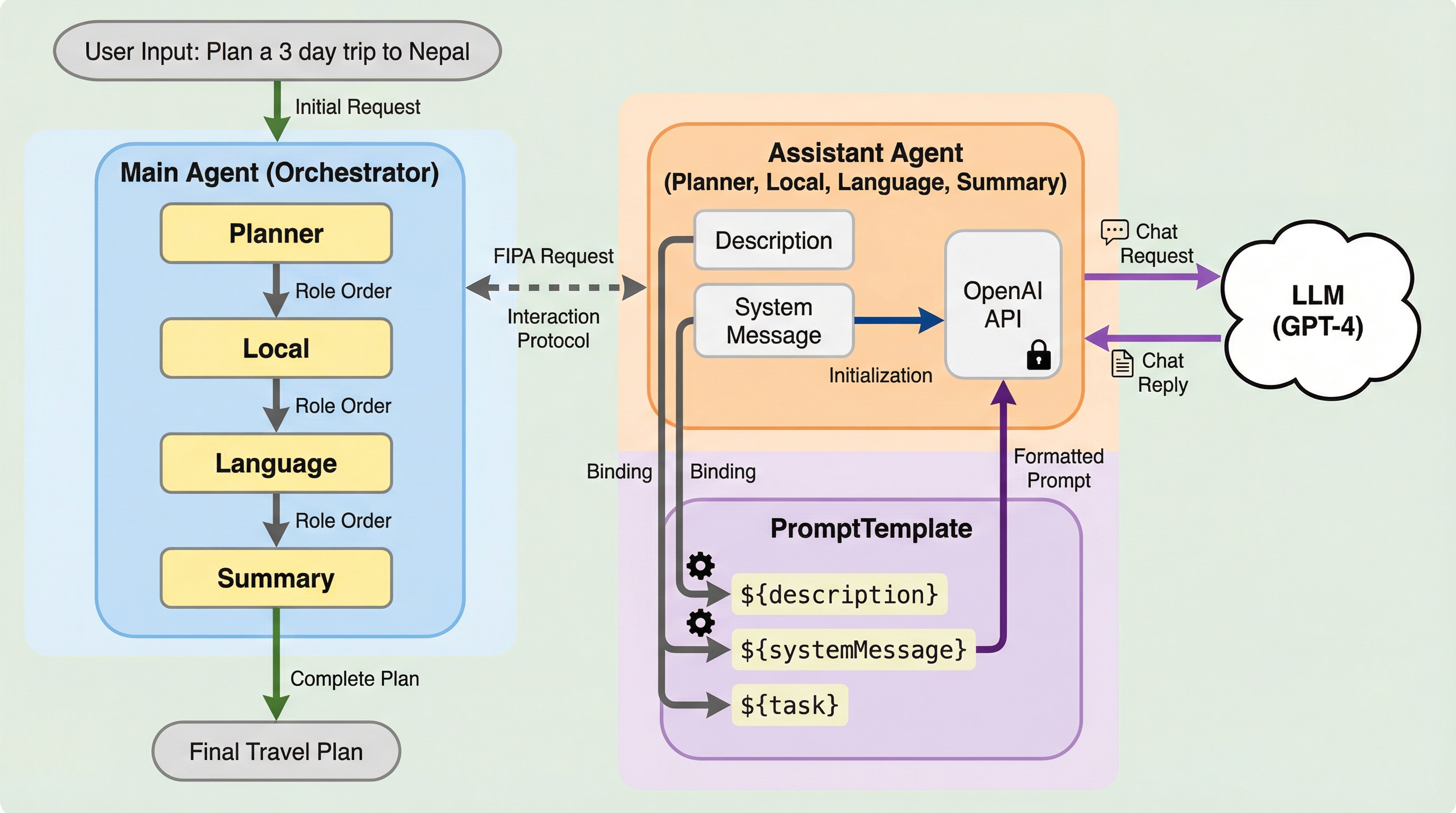
ASTRAプログラミング言語に大規模言語モデル(LLM)の機能を統合するための専用ライブラリ「astra-langchain4j」が開発され、Java向けのLangChain4jを基盤として、生成AIの推論や計画能力を自律型エージェントに組み込む新しい手法が提案された。
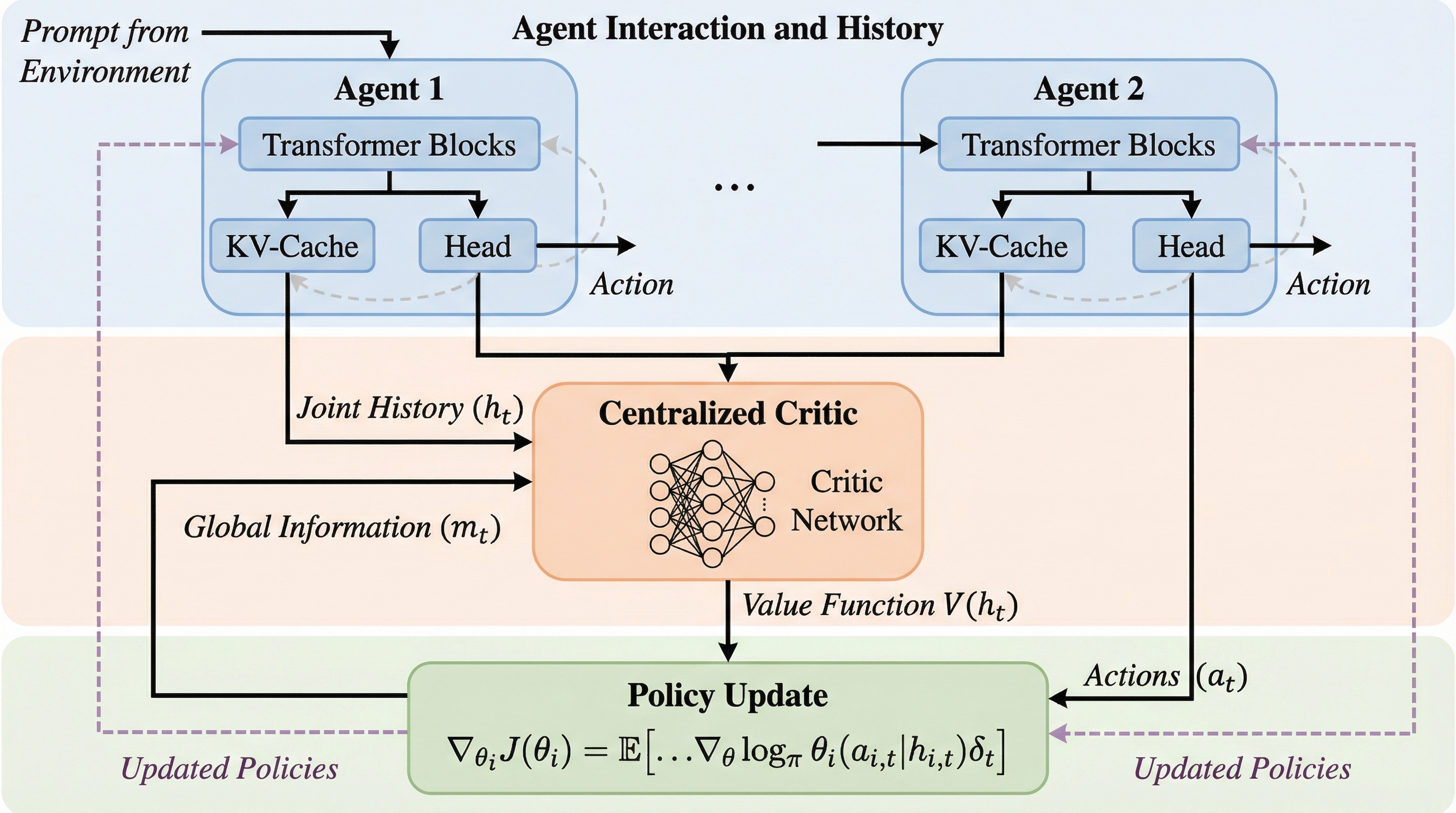
分散型の大規模言語モデル(LLM)エージェント間の協調を最適化するため、マルチエージェントActor-Critic(MAAC)手法であるCoLLM-CCとCoLLM-DCが提案されました。 従来のモンテカルロ法は、長期的なタスクや報酬が疎な設定において勾配の分散が極めて大きく、学習効率が著しく低下するという課題がありましたが、本手法は批判者(Critic)を導入することでこの問題を解決します。 執筆、コーディング、Minecraftでの建築という多様なドメインでの検証の結果、集中型批判者を用いるCoLLM-CCは、特に複雑で長期的な対話が必要なタスクにおいて、既存手法を大幅に上回る性能と収束の安定性を示しました。
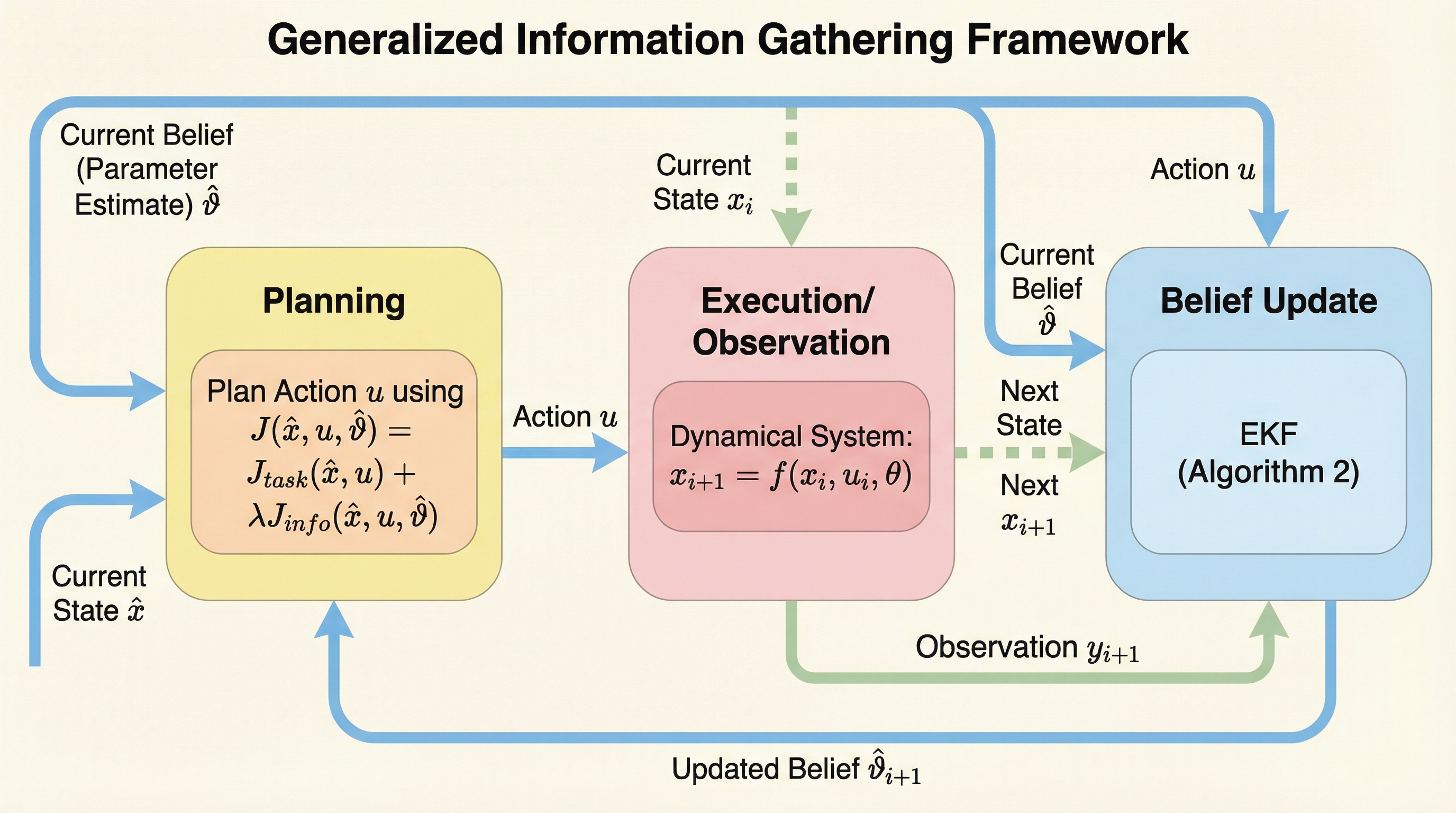
未知の力学系で作動するエージェントが、特定のモデルや更新手法に依存せずに効率的な学習を行うための、因果関係を明示した一般化された情報収集フレームワークを提案しています。この枠組みは、パラメータ、信念、制御、状態、観測の間の複雑な依存関係を因果グラフによって整理し、学習と計画のプロセスを完全に分離して設計することを可能にします。 マッセイの有向情報量に基づいた新しいコスト関数を導入し、従来の相互情報量を用いる手法が特定の条件下における特殊なケースであることを数学的に証明することで、既存手法に理論的な正当性を与えました。これにより、ガウス過程やニューラルネットワークなど、異なるモデル構造を採用した場合でも、統一的な数理基盤の上で最適な情報収集行動を導出できます。 この枠組みは、線形・非線形システムやマルチエージェント環境において、学習アルゴリズムと計画アルゴリズムを柔軟に組み合わせることを可能にし、未知の他者に関する情報の能動的な取得を容易にします。実験では、自律走行車が他者の意図を推定するシナリオなどを通じて、提案手法が多様なタスクにおいて一貫した性能を発揮し、システムの安全性を高めることを実証しました。
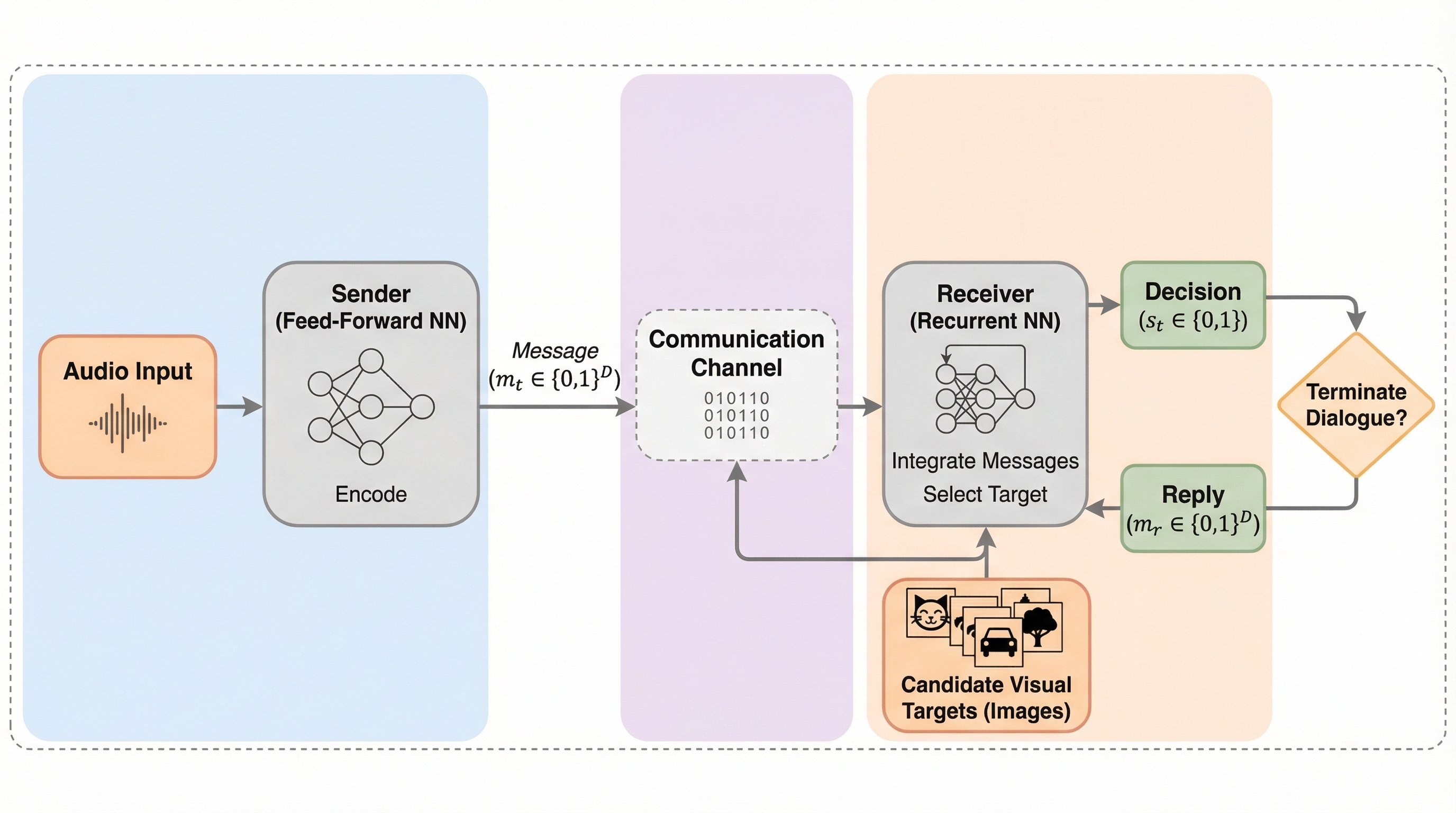
本研究は、送信者が「音声」を聞き、受信者が「画像」を見るという、互いに異なる知覚モダリティ(感覚器)を持つ異種マルチエージェント間において、共通の知覚基盤がない状態からどのようにコミュニケーションが創発するかを調査したものです。
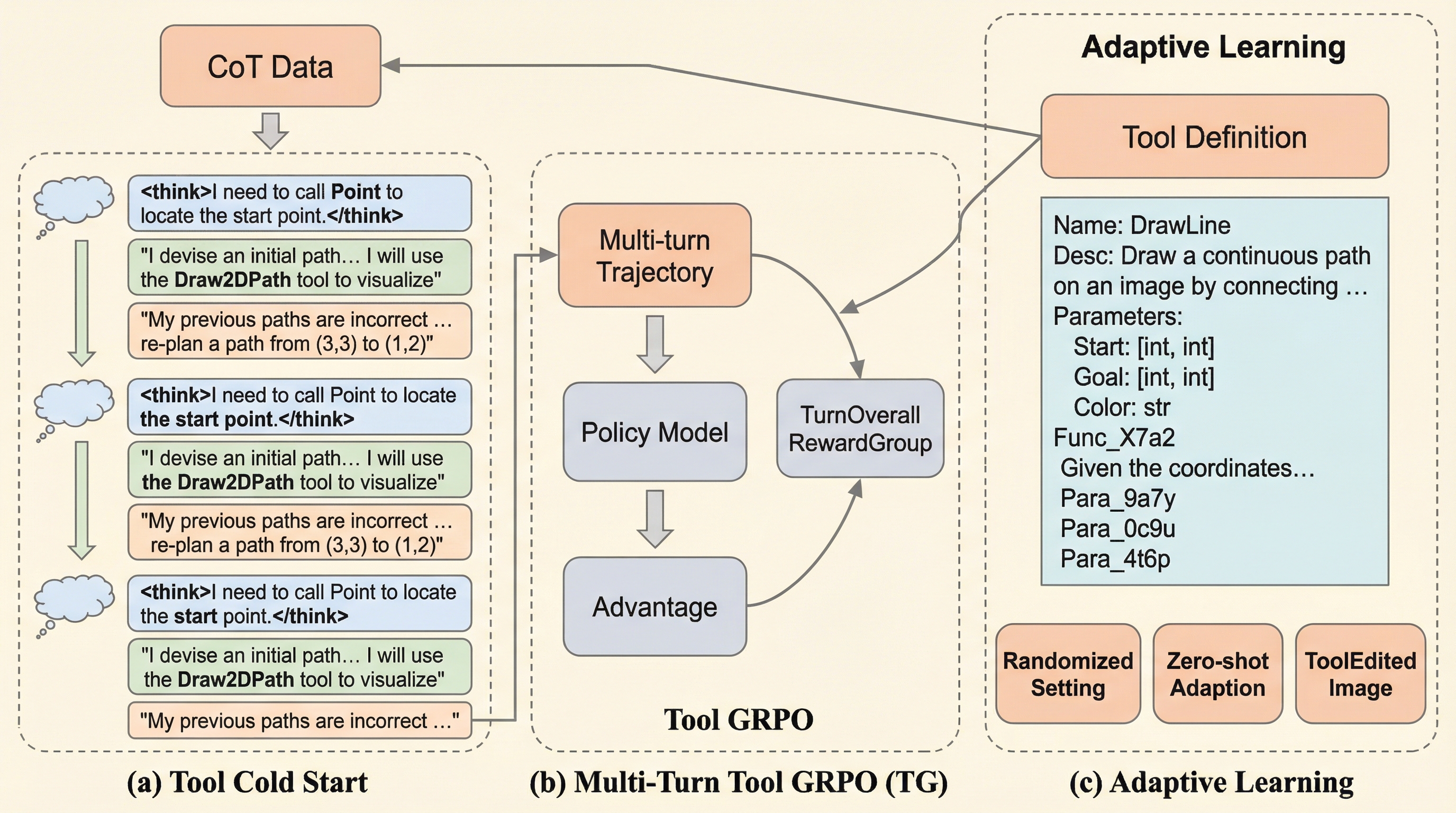
AdaReasonerは、マルチモーダル大規模言語モデル(MLLM)において、ツール利用を特定のタスクの手順としてではなく、文脈に応じて「いつ、何を、どう使うか」を判断する汎用的な推論スキルとして習得させる新しいモデルファミリーである。
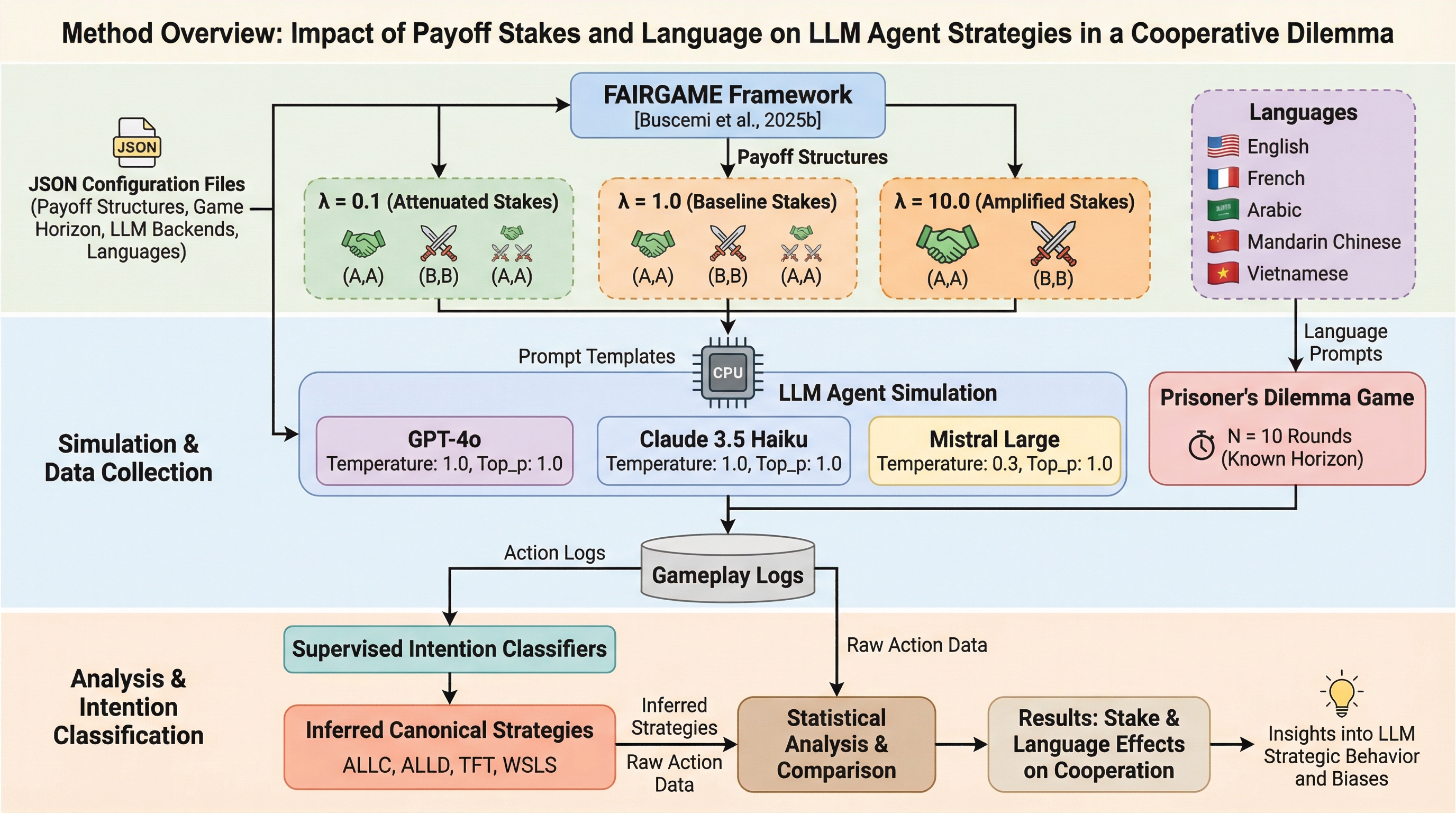
本研究は、大規模言語モデル(LLM)エージェントが繰り返される囚人のジレンマにおいて、利得の絶対的な大きさと提示される言語が戦略的行動にどのような影響を与えるかを、FAIRGAMEフレームワークを用いて詳細に分析した。
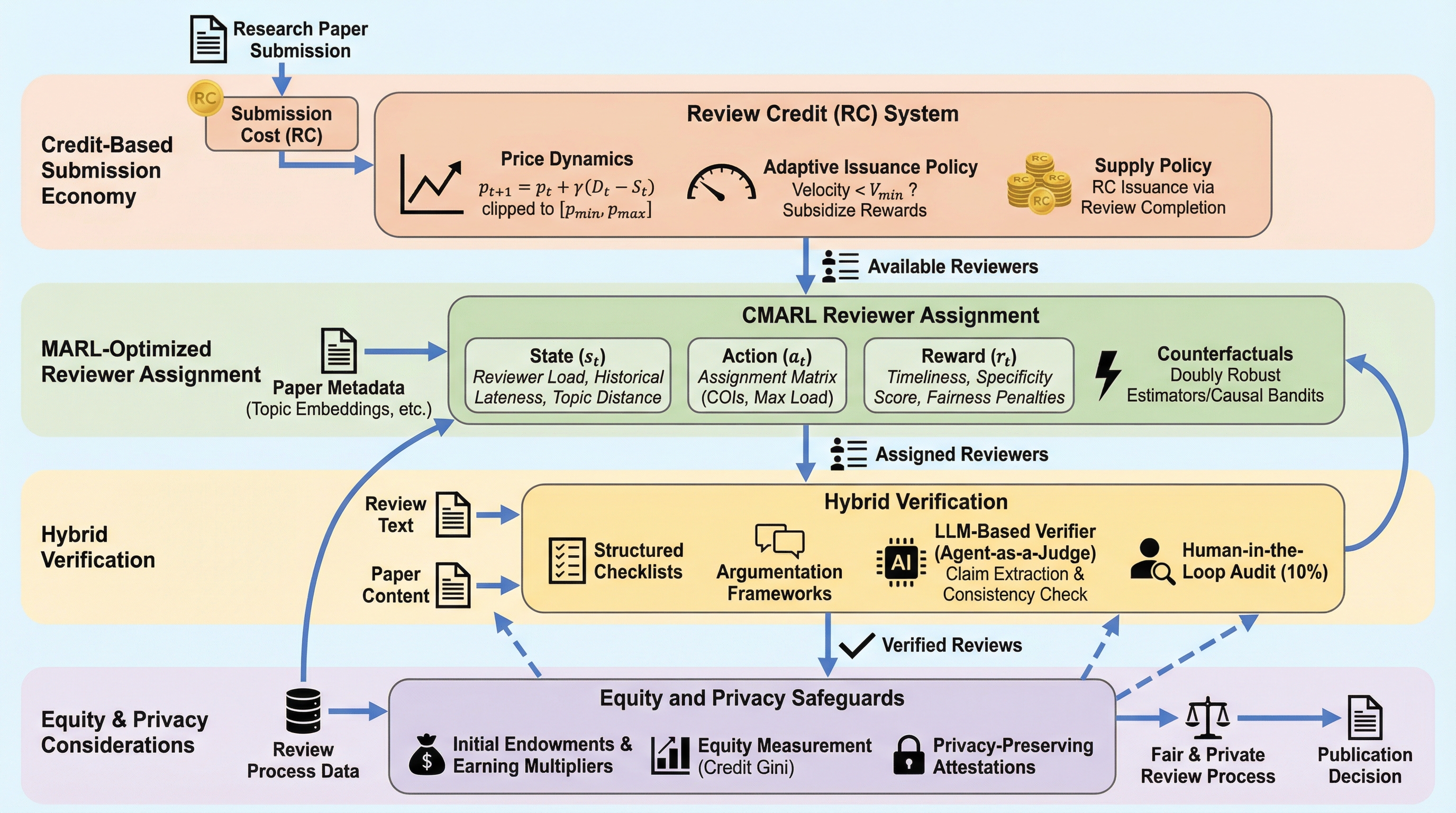
現在の学術論文査読システムは、投稿数の急増と査読者のインセンティブ不一致により「共有地の悲劇」に直面しており、査読結果の不一致や大規模言語モデル(LLM)による質の低下が深刻な問題となっています。