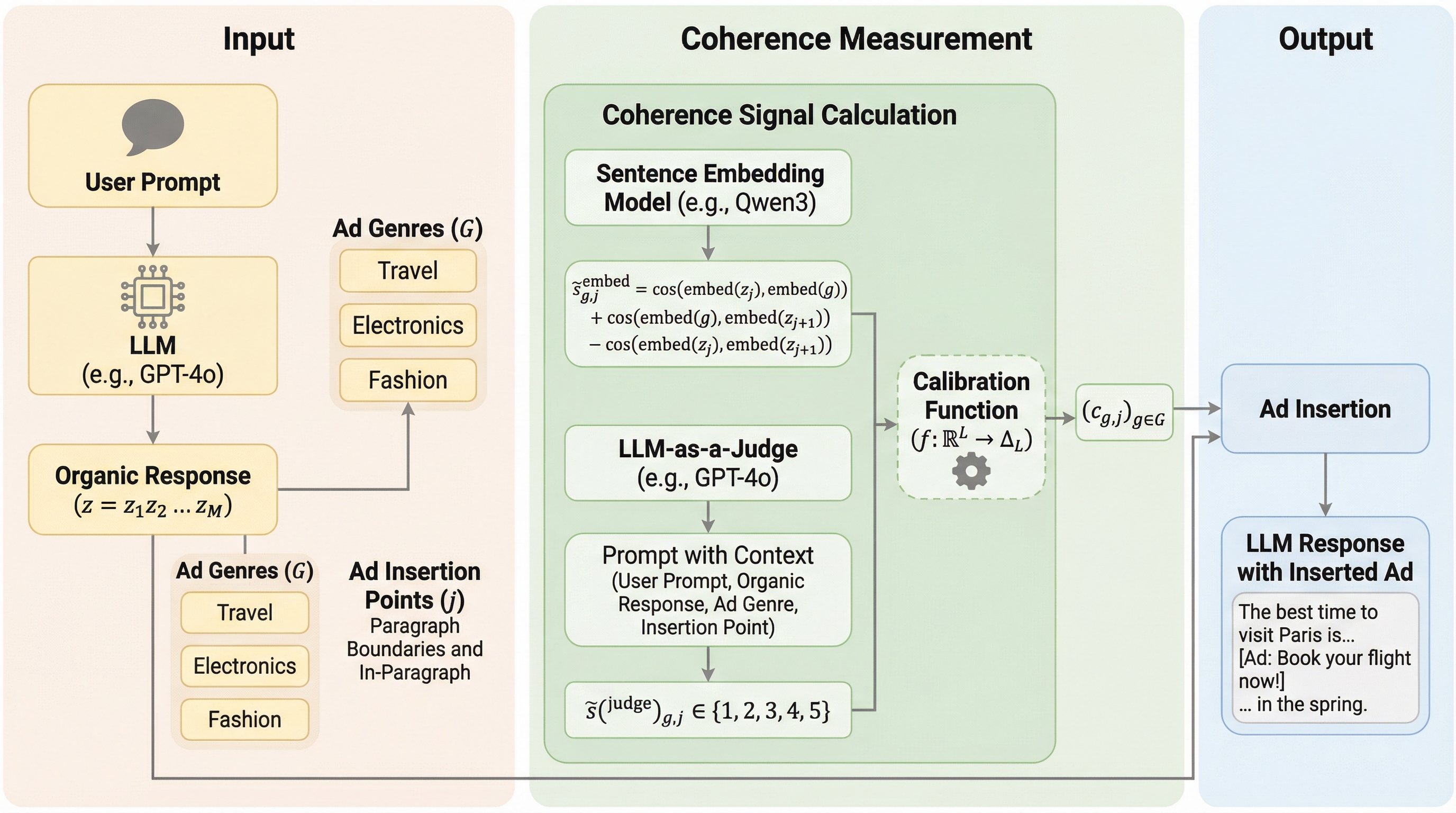
LLM生成応答への広告挿入
大規模言語モデル(LLM)の持続可能な収益化に向け、広告挿入を応答生成から分離し、広告主が特定のクエリではなく「ジャンル」という抽象的なカテゴリに対して事前に入札を行う新しい広告枠組みを提案する。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)の持続可能な収益化に向け、広告挿入を応答生成から分離し、広告主が特定のクエリではなく「ジャンル」という抽象的なカテゴリに対して事前に入札を行う新しい広告枠組みを提案する。

公開されている人間によるテキストデータが今後10年以内に枯渇するという予測に基づき、正解ラベル(Ground Truth)に依存せずにモデルの性能を向上させる手法が求められています。本研究は、強力だが予測の確信度と実際の正解率が乖離している(校正されていない)モデルを、性能は低いが校正が適切になされている参照モデルを用いて後処理し、性能を厳密に向上させるフレームワークを提案しています。この手法は経済学の「裁定取引」や「ノー・トレード定理」の概念を機械学習に導入したものであり、ラベルなしのデータのみを用いて、大規模言語モデルの予測誤差や校正エラーを監督ありのベースラインに匹敵するレベルまで削減することに成功しました。