内省的翻訳:構造化された自己内省による低リソース機械翻訳の改善
isiZuluやisiXhosaといった低リソース言語の機械翻訳において、限定的な学習データに起因する誤訳や情報の欠落、意味の歪みを解決するため、モデルが自らの出力を批判的に評価し修正する「内省的翻訳(Reflective Translation)」フレームワークが提案されました。 この手法は、GPT-3.
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
isiZuluやisiXhosaといった低リソース言語の機械翻訳において、限定的な学習データに起因する誤訳や情報の欠落、意味の歪みを解決するため、モデルが自らの出力を批判的に評価し修正する「内省的翻訳(Reflective Translation)」フレームワークが提案されました。 この手法は、GPT-3.
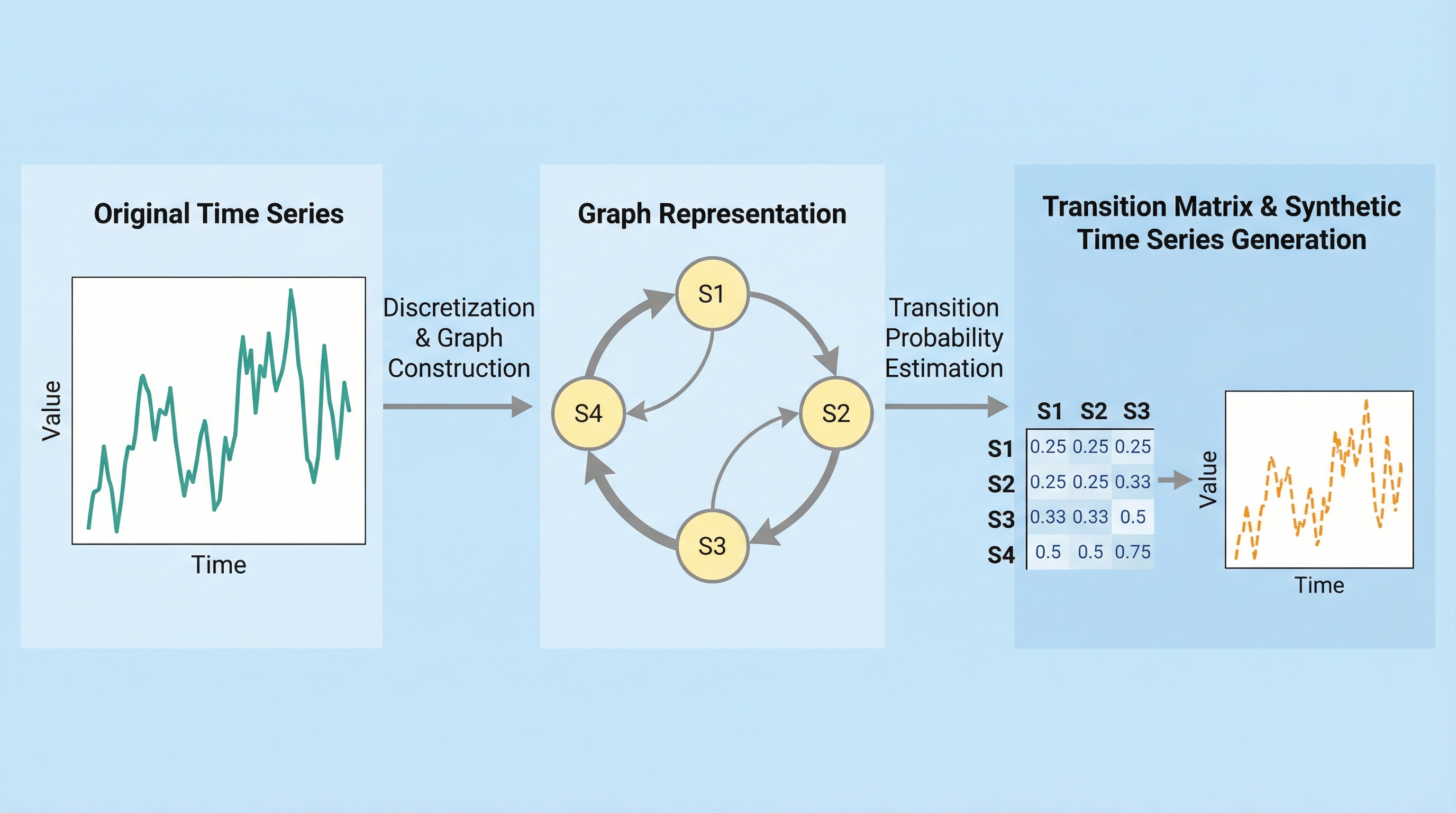
Grasyndaは、単変量の時系列データをグラフ構造へと変換し、状態間の遷移確率を基に現実的な合成データを生成する新しいデータ拡張手法である。時系列を離散的な状態(ノード)とそれらの遷移(エッジ)としてモデル化することで、データの局所的なパターンと全体的な構造の両方を効果的に符号化し、統計的性質を維持したデータ生成を可能にする。 6つのベンチマークデータセットを用いた検証の結果、NHITSやKANなどの最新モデルにおいて、AmazonのChronosで採用されている手法を含む既存のデータ拡張技術を上回る予測精度の向上が確認された。 この手法はSTL分解を併用することで、トレンドや季節性といった非定常な特性を保持しながら、効率的かつ高精度なデータ拡張を実現し、深層学習モデルの汎化性能を大幅に向上させる実用的な枠組みを提供している。

本研究は、科学分野の複雑なマルチホップ質問応答において、反復的な検索と推論のループが、理想的な静的根拠(ゴールドコンテキスト)を上回る性能を発揮することを解明しました。11種類の最新大規模言語モデルを用いた実験の結果、反復的RAGは非推論特化型モデルにおいて最大25.

公開されている人間によるテキストデータが今後10年以内に枯渇するという予測に基づき、正解ラベル(Ground Truth)に依存せずにモデルの性能を向上させる手法が求められています。本研究は、強力だが予測の確信度と実際の正解率が乖離している(校正されていない)モデルを、性能は低いが校正が適切になされている参照モデルを用いて後処理し、性能を厳密に向上させるフレームワークを提案しています。この手法は経済学の「裁定取引」や「ノー・トレード定理」の概念を機械学習に導入したものであり、ラベルなしのデータのみを用いて、大規模言語モデルの予測誤差や校正エラーを監督ありのベースラインに匹敵するレベルまで削減することに成功しました。