生成デコンプレッション:分布の不一致に対する最適な非可逆復号化
本論文は、圧縮機の設計時に想定したデータ分布と実際のソース分布が異なる「分布の不一致」が発生する状況において、送信側のエンコーダを一切変更することなく、受信機側のみの調整で歪みを最小化する「生成デコンプレッション」を提案している。
TL;DR(結論)
本論文は、圧縮機の設計時に想定したデータ分布と実際のソース分布が異なる「分布の不一致」が発生する状況において、送信側のエンコーダを一切変更することなく、受信機側のみの調整で歪みを最小化する「生成デコンプレッション」を提案している。 この手法は、固定された標準規格やレガシーなエンコーダを維持したまま、受信機が持つ実際の分布に関する事前情報を活用してベイズ推定に基づく条件付き期待値を計算することで、従来の重心ルールを大幅に上回る復号精度を実現するものである。 検証の結果、5Gの通信路状態情報の圧縮やセマンティック分類において、理想的な共同最適化に近い性能を達成し、特にデータの裾が重い分布の不一致において、ビットレートを上げても解消されない歪みの床を劇的に低減できることが示された。
なぜこの問題か
非可逆データ圧縮は、通信やストレージの効率化において不可欠な技術であり、通常は特定のデータ分布を想定して平均二乗誤差(MSE)などの歪みを最小化するように設計される。しかし、実際の運用環境では、推定誤差やデータの非定常性、あるいはモデルの不正確さにより、設計時の想定分布と実際のソース分布の間に「分布の不一致」が生じることが避けられない。特に、第5世代移動通信システム(5G)などの標準化された通信システムでは、エンコーダ(送信機)の仕様がプロトコルとして固定されており、受信機側で新しい統計情報を得たとしても送信側を変更できないという強い制約がある。従来の復号手法では、設計時の分布に基づいた重心ルールが用いられるが、これは分布の不一致がある場合には最適ではなく、大きな量子化誤差や歪みを引き起こす原因となる。 この問題は古典的な情報理論に根ざしており、ワイナー・ジブ(Wyner-Ziv)の定理などで受信機側のサイド情報の活用が議論されてきたが、現代の生成AIやセマンティック通信の文脈で新たな重要性を帯びている。…
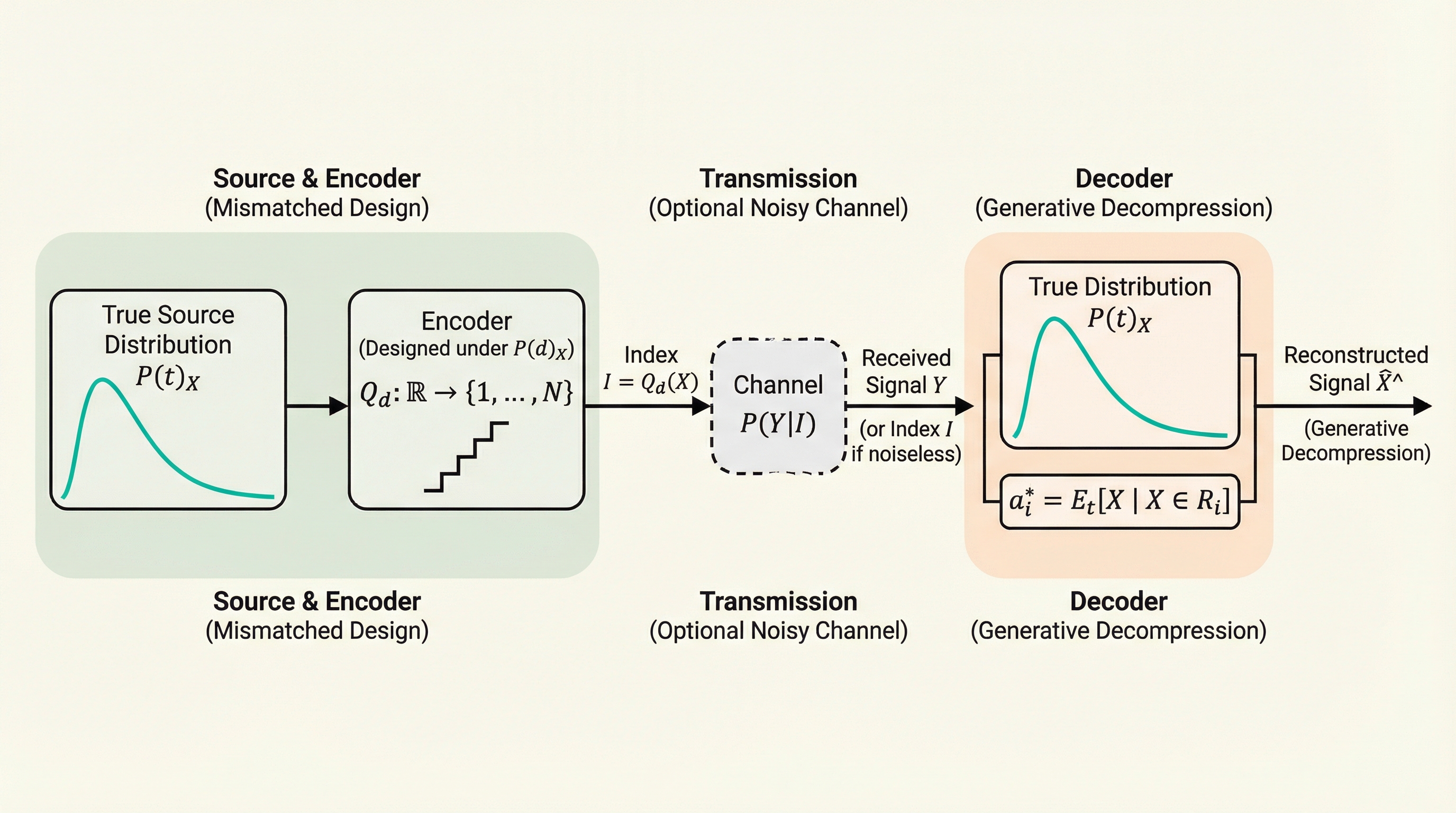
核心:何を提案したのか
本論文の核心は、エンコーダを完全に固定したまま、デコーダ側で実際の分布の事前情報を活用して復号ルールを最適化する「生成デコンプレッション(Generative Decompression)」という概念の提案である。これは、量子化されたインデックスを受け取った際に、設計時の重心をそのまま使うのではなく、実際の分布における条件付き期待値を計算して再構成値を決定するベイズ的なアプローチである。具体的には、設計分布に基づいて分割された量子化領域に対し、実際の分布の下での最小平均二乗誤差(MMSE)推定値を算出することで、デコーダ側での「パッチ」として機能させる。この手法は、数学的には古典的なロイド・マックス(Lloyd-Max)の条件を実際の分布に適用したものと言えるが、これを固定エンコーダ制約下での「生成的な補正」として定式化した点に新規性がある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related