MCPベースのサーバーエコシステムにおけるインテリジェントエージェントのための宣言型エージェント層に向けて
大規模言語モデル(LLM)ベースのエージェントは、行動の根拠となる明示的な構造を欠いているため、実行不可能な計画の作成やハルシネーションといった深刻な信頼性の問題に直面しており、既存のマルチエージェントシステムでは41%から86%という高い失敗率が報告されている。
TL;DR(結論)
大規模言語モデル(LLM)ベースのエージェントは、行動の根拠となる明示的な構造を欠いているため、実行不可能な計画の作成やハルシネーションといった深刻な信頼性の問題に直面しており、既存のマルチエージェントシステムでは41%から86%という高い失敗率が報告されている。 本論文は、目標、能力、実行を構造的に結びつけるモデル非依存の宣言型レイヤー「DALIA」を提案し、Model Context Protocol(MCP)を拡張して、ツールの意味論的定義、タスク発見プロトコル、およびエージェントのディレクトリを導入することで、エージェントの行動を検証可能な運用空間に制限する。 これにより、エージェントは言語的な推論のみに頼ることなく、宣言された実際の能力に基づいた決定論的なタスクグラフを構築できるようになり、異種混合環境においても再現性と検証可能性の高いエージェントワークフローが実現される。
なぜこの問題か
近年、大規模言語モデル(LLM)の進歩により、複雑な推論やツールの利用、タスクの分解が可能なエージェントシステムの開発が進んでいる。しかし、これらのシステムは実証的な証拠において、根本的な信頼性の欠如という課題を抱えている。具体的には、存在しないアクションを捏造するハルシネーション、実行不可能な計画の立案、そして脆弱な調整能力といった問題が頻発している。先行研究であるCemriらによる調査では、7つのマルチエージェントシステム(MAS)フレームワークにわたる1,642回の実行を分析した結果、失敗率が41%から86%に達することが報告されている。この調査では、失敗の要因を「システム設計の欠陥(FC1)」、「エージェントの不整合(FC2)」、「不十分な検証(FC3)」の3つのカテゴリ、計14の失敗モードに分類している。 これらの失敗は、基盤となるLLM自体の能力不足ではなく、目標、能力、および実行をリンクさせる明示的なアーキテクチャ構造の欠如に起因している。現在のアプローチは、エージェントが実行可能なアクションに関する明示的な根拠(グラウンディング)を持たず、言語的な推論のみに大きく依存している。…
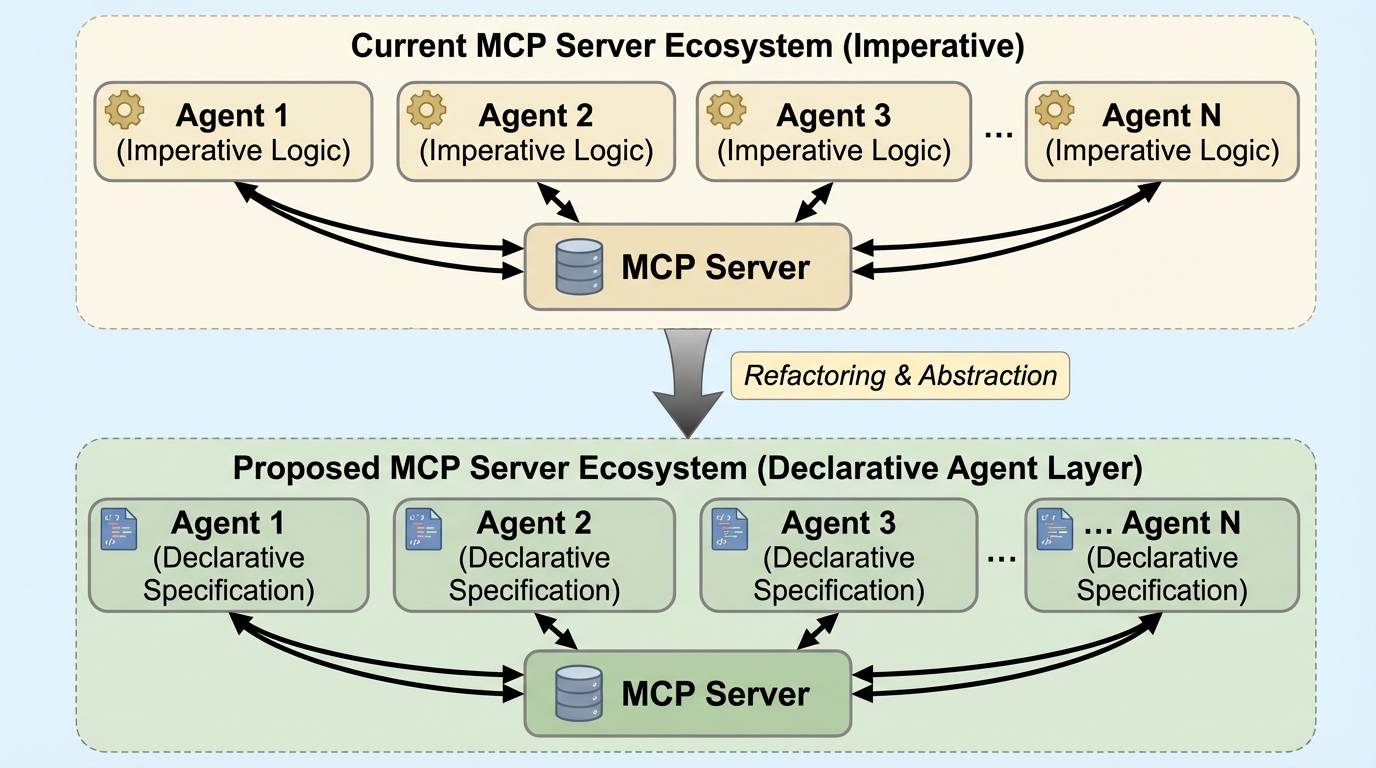
核心:何を提案したのか
本論文では、インテリジェントエージェントのための宣言型エージェント層「DALIA(Declarative Agentic Layer for Intelligent Agents)」を提案している。DALIAは、LLM駆動型のエージェントと、ツールやサービス、実行環境からなる異種混合のエコシステムとの間に位置する中間レイヤーとして機能する。このアーキテクチャの核心は、エージェントの推論プロセスから、能力の記述、タスクの発見、および計画の立案を「宣言的」な形式で切り離すことにある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related