手書き数式認識のための離散拡散モデルを用いたシンボル認識推論
手書き数式認識(HMER)において、従来の逐次的な生成手法ではなく、離散拡散モデルを用いた反復的なシンボル洗練プロセスを提案した。この手法は、先行する予測の誤りが後続に影響する露呈バイアスを排除し、複雑な二次元構造を持つ数式の認識精度を大幅に向上させる。
TL;DR(結論)
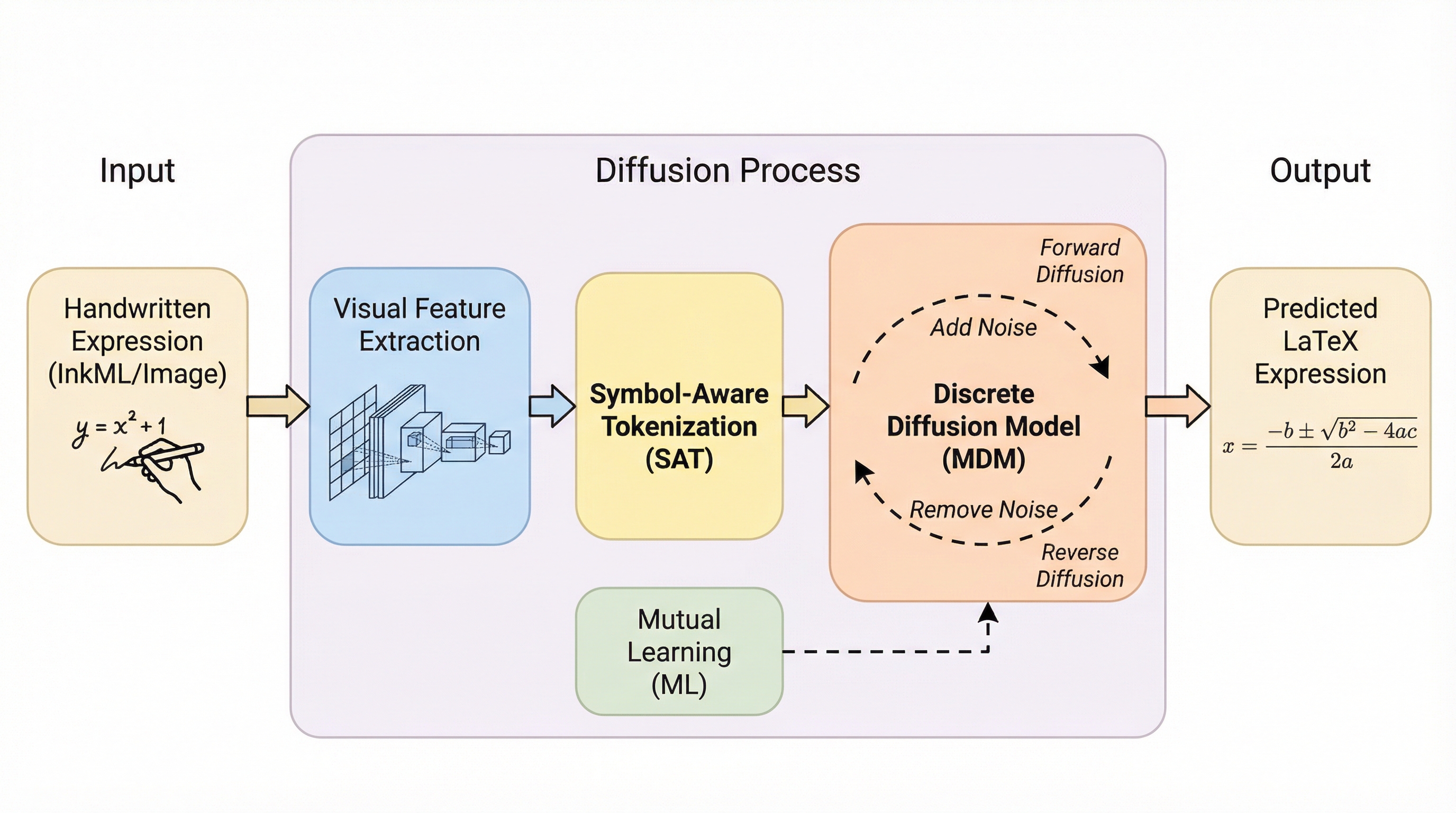
手書き数式認識(HMER)において、従来の逐次的な生成手法ではなく、離散拡散モデルを用いた反復的なシンボル洗練プロセスを提案した。この手法は、先行する予測の誤りが後続に影響する露呈バイアスを排除し、複雑な二次元構造を持つ数式の認識精度を大幅に向上させる。 シンボルと構造修飾子を一対一で対応させる「シンボル認識トークン化(SAT)」を導入し、数式の構文的一貫性を維持しながら表現の複雑さを軽減した。これにより、局所的な修正が全体の構造を壊すことなく行えるようになり、効率的かつ安定した推論が可能となった。 相互学習(RMML)の統合により、筆跡の多様性や構造的な曖昧さに対する頑健性を高め、MathWritingやCROHMEといった主要なベンチマークで従来手法を凌駕する性能を達成した。特にMathWritingでは、文字誤り率5.56%という優れた結果を記録している。
なぜこの問題か
手書き数式認識(HMER)は、視覚的な数学記号を解釈し、LaTeXのような構造化されたマークアップ形式に変換することを目的としている。このタスクは、標準的な光学文字認識(OCR)と比較して、二つの大きな困難に直面している。第一に、書き手によって異なる多様な筆跡スタイルや記号の形状に起因する視覚的な曖昧さである。第二に、上付き文字、下付き文字、分数、根号といった複雑な二次元レイアウトから生じる構文的な曖昧さである。例えば、草書体の「z」は数字の「2」に酷似する場合があり、階層的な構文が正しく推論されないと、数式全体の意味が大きく変わってしまう。HMERには、微細な視覚的知覚と、グローバルに一貫した構造的推論の両方が不可欠である。 従来の多くの手法は、アテンション機構を備えたエンコーダ・デコーダ型の自己回帰(AR)モデルを採用しており、LaTeXトークンを左から右へと逐次的に生成している。しかし、この方式は「露呈バイアス」という深刻な問題に悩まされている。これは、系列の初期段階での予測ミスが後続の生成に伝播し、数式全体の構造を崩してしまう現象である。…
核心:何を提案したのか
本研究では、HMERを逐次的な生成プロセスではなく、離散拡散モデルを用いた反復的なシンボルの洗練プロセスとして再定義するフレームワークを提案している。この提案手法は、完全にマスクされたトークン系列から開始し、多ステップの再マスクとアンマスクを繰り返すことで、数式を段階的に再構築する。この定式化により、自己回帰デコーディングに固有の因果的依存関係が排除され、シンボルと構造的関係の両方を同時に、かつ徐々に洗練させることが可能になった。これは、一度のパスで予測を完了する標準的な非自己回帰モデルを超える能力であり、生成モデルの枠を超えた構造認識のための新しいパラダイムを提示している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related