再帰型スパイキングニューラルネットワークの勾配不要な最適化のための信号適応型信頼領域法
再帰型スパイキングニューラルネットワーク(RSNN)は、エネルギー効率に優れた制御ポリシーとして期待されていますが、高次元かつ長期的な強化学習タスクにおける訓練の不安定さが大きな課題となっていました。
TL;DR(結論)
再帰型スパイキングニューラルネットワーク(RSNN)は、エネルギー効率に優れた制御ポリシーとして期待されていますが、高次元かつ長期的な強化学習タスクにおける訓練の不安定さが大きな課題となっていました。本研究が提案する信号適応型信頼領域法(SATR)は、勾配推定値の信号エネルギーに基づいて信頼領域の大きさを動的に調整することで、限られた個体数での訓練安定性を大幅に向上させます。さらに、バイナリ形式のスパイクと重みを活用したビットセット実装を導入することで、従来の計算手法と比較して最大で8.9倍の高速化を実現し、実用的な時間内での効率的なポリシー探索を可能にしました。
なぜこの問題か
強化学習は高次元の連続制御問題において大きな成果を収めてきましたが、その多くは計算負荷の高い人工ニューラルネットワーク(ANN)に依存しており、電力や遅延の制約があるエッジプラットフォームへの展開には限界があります。これに対し、スパイキングニューラルネットワーク(SNN)はイベント駆動型の動態を持ち、スパースな計算を可能にするため、特にニューロモーフィックハードウェア上での大幅なエネルギー効率の向上が期待されています。しかし、再帰的な構造を持つスパイキングポリシーは、高次元で長期的な制御タスクにおいて、従来のANNの性能に到達することが歴史的に困難でした。この大きな障害の一つは、微分不可能なスパイク動態を通じた信頼割当の難しさにあります。 一般的に用いられるサロゲート勾配を用いた時間貫通誤差逆伝播法(BPTT)は、長い時間の展開に伴うメモリコストが膨大になり、計算を途中で切り捨てることが必要になります。この切り捨ては、複雑な制御タスクで要求される長期的な時間依存性の学習を弱めてしまいます。こうした背景から、進化戦略(ES)のような個体群ベースの勾配不要な最適化手法が注目されています。…
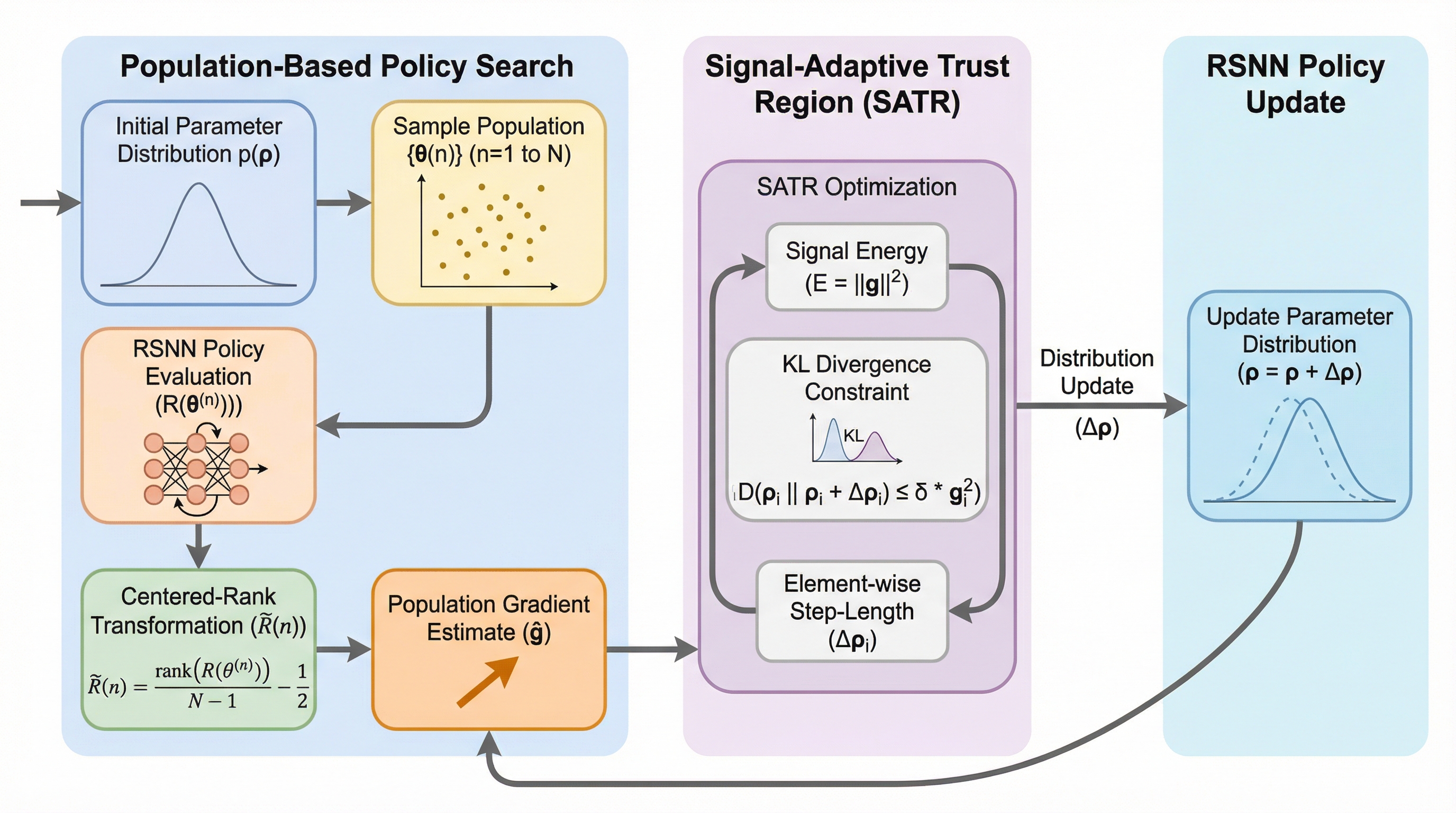
核心:何を提案したのか
本研究では、個体群ベースの強化学習における更新の安定性を確保するために、信号適応型信頼領域法(SATR)という新しい分布更新ルールを提案しています。この手法の核心は、連続するサンプリング分布間の相対的な変化を、推定された信号エネルギーによって正規化されたKLダイバージェンスで制限することにあります。従来の信頼領域法では固定された予算を用いて分布の変化を抑えますが、SATRは最適化信号の強さに応じてその許容範囲を動的に調整する点が特徴的です。これにより、信号が明確なときには大胆な更新を行い、不確実なときには慎重なステップを踏むという、適応的な学習プロセスが実現されます。 具体的には、個体群から得られた勾配推定値の二乗ノルムを信号エネルギーとして定義し、このエネルギーが大きい場合には信頼領域を自動的に拡大させ、更新がノイズに支配されている場合には領域を収縮させます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related