Scalable Power Sampling: 分布の鋭敏化によるLLMの効率的かつ学習不要な推論の実現
大規模言語モデルの推論性能を向上させる強化学習は、本質的には新しい能力の獲得ではなく、既存の分布を鋭敏化するプロセスであるという仮説に基づき、外部報酬や追加学習を一切必要とせずに推論能力を引き出す新しいサンプリング手法が提案されました。
TL;DR(結論)
大規模言語モデルの推論性能を向上させる強化学習は、本質的には新しい能力の獲得ではなく、既存の分布を鋭敏化するプロセスであるという仮説に基づき、外部報酬や追加学習を一切必要とせずに推論能力を引き出す新しいサンプリング手法が提案されました。 提案された手法は、計算コストが極めて高い従来のマルコフ連鎖モンテカルロ法に代わり、トークン単位のスケーリング係数を用いて大域的なべき乗分布を近似することで、自己回帰的な生成プロセスの中で効率的に分布の鋭敏化を実現する理論的な枠組みを構築しています。 数学やコード生成などの主要なベンチマークにおいて、この手法は強化学習を用いた手法と同等以上の性能を発揮しながら、従来のサンプリング手法と比較して推論の遅延を10倍以上短縮することに成功しており、実用的な推論の効率化に大きく貢献するものです。
なぜこの問題か
大規模言語モデル(LLM)の推論性能を向上させるための主要なアプローチとして、強化学習(RL)を用いた事後学習が広く採用されています。具体的には、コーディングタスクにおけるユニットテストや、数学タスクにおける最終回答の照合、あるいはLean証明書のような自動検証器を用いてモデルを最適化する手法が、様々なベンチマークで高い性能を記録してきました。しかし、これらの性能向上がどのようなメカニズムによってもたらされているのかについては、現在も活発な議論が続いています。近年の研究では、強化学習がモデルに根本的に新しい推論能力を導入しているのではなく、既存のモデル内に潜在している推論の軌跡を強調する「分布の鋭敏化」として機能している可能性が示唆されています。 もし強化学習後のモデルが単にベースモデルの分布を鋭敏化したものであるならば、外部の報酬や追加の学習に頼ることなく、ベースモデルの分布を直接操作することで同等の推論能力を引き出すことができるはずです。先行研究では、マルコフ連鎖モンテカルロ法(MCMC)を用いてべき乗分布からサンプリングを行うことで、強化学習後のモデルに匹敵する性能が得られることが示されました。…
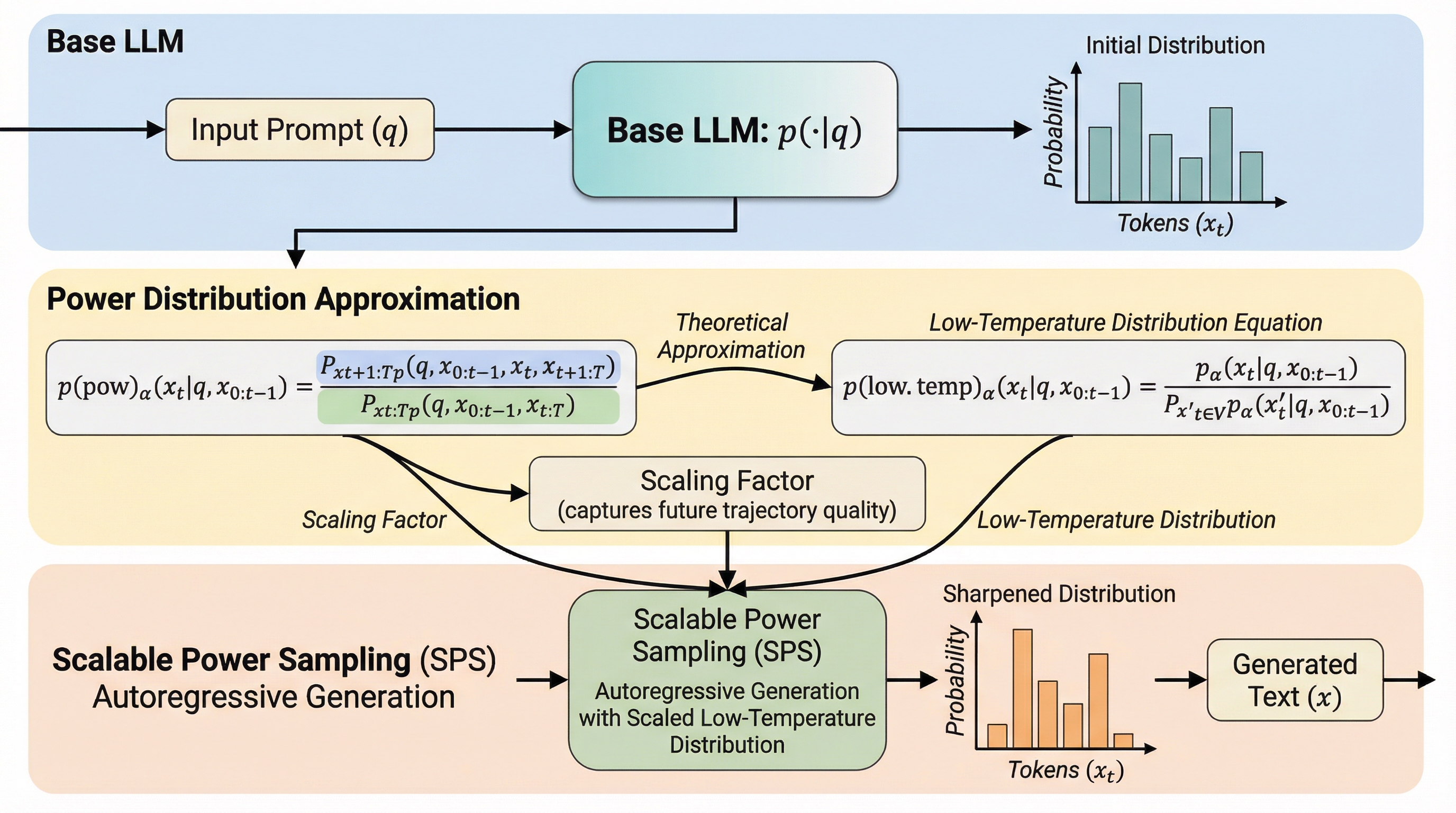
核心:何を提案したのか
本研究では、反復的なMCMCを必要としない、理論的根拠に基づいた新しいサンプリング手法「Scalable Power Sampling」を提案しています。この手法の核心は、大域的なべき乗分布が、トークンレベルでスケーリングされた低温分布によって近似できるという新しい定式化を導き出した点にあります。このスケーリング係数は、そのトークンを選択した後に続く将来の軌跡の質を捉える役割を果たします。これにより、従来のMCMCが抱えていた反復的な計算オーバーヘッドを排除し、標準的な自己回帰的生成のプロセスの中で効率的に分布を鋭敏化することが可能になりました。 具体的には、べき乗分布と低温分布の間の理論的なギャップを埋める定理を証明しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related