Scalable Power Sampling: 分布の先鋭化によるLLMの効率的かつ学習不要な推論の実現
大規模言語モデルの推論性能を向上させる強化学習(RL)の効果は、新しい能力の獲得ではなく、既存のモデル内に潜在する分布を先鋭化させることに起因するという見方が強まっており、外部報酬や追加学習なしでこの効果を再現する手法が求められています。
TL;DR(結論)
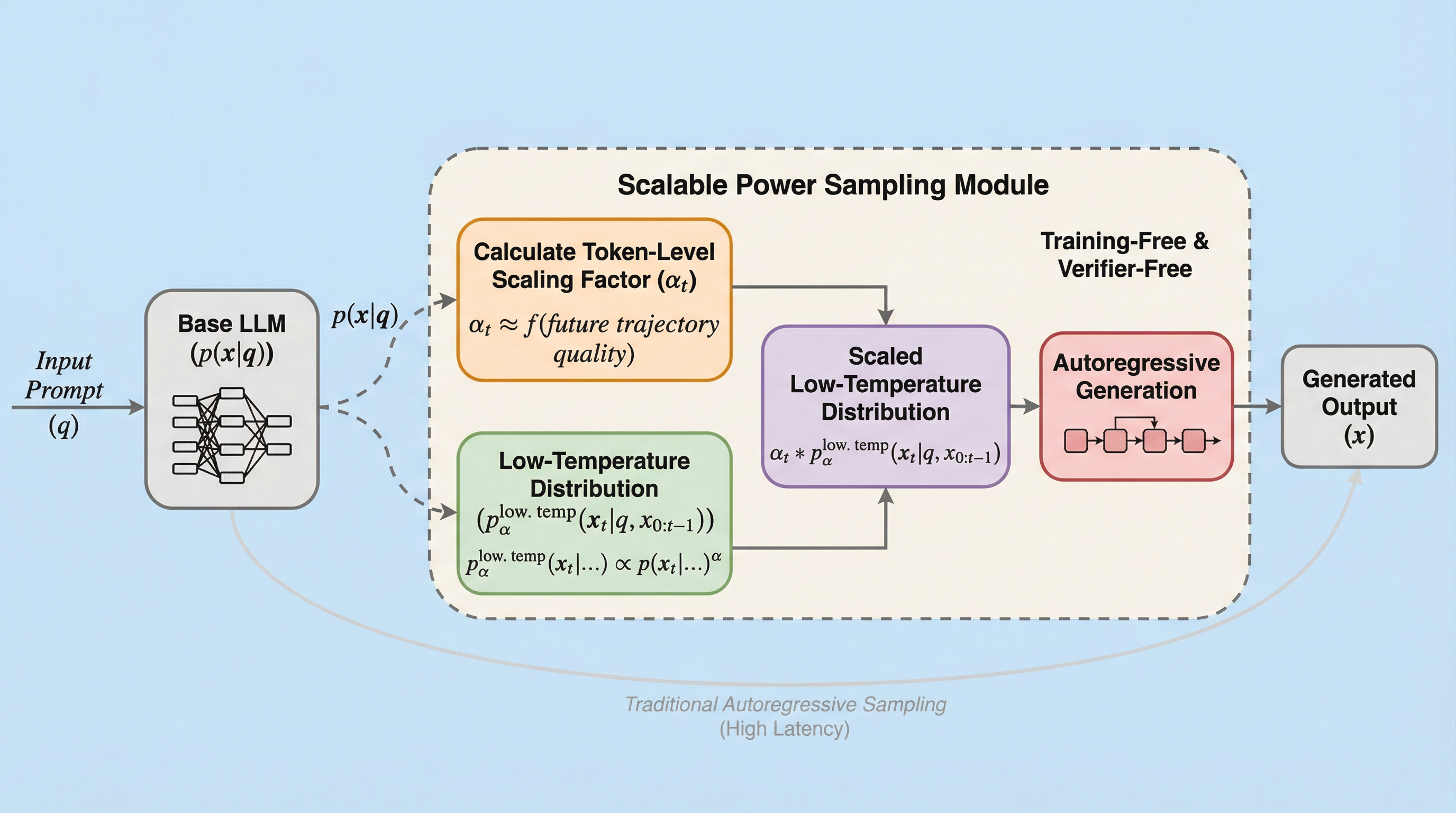
大規模言語モデルの推論性能を向上させる強化学習(RL)の効果は、新しい能力の獲得ではなく、既存のモデル内に潜在する分布を先鋭化させることに起因するという見方が強まっており、外部報酬や追加学習なしでこの効果を再現する手法が求められています。 本研究では、計算コストが極めて高いマルコフ連鎖モンテカルロ法(MCMC)に代わり、トークン単位のスケーリング因子を用いてグローバルなべき分布を近似する、理論的根拠に基づいた新しいアルゴリズム「Scalable Power Sampling」を提案しています。 この手法は学習や検証器を一切必要とせず、数学やコード生成のタスクにおいて強化学習を用いた手法と同等以上の性能を達成しながら、従来のサンプリング手法と比較して推論の遅延を10倍以上削減することに成功した画期的なアプローチです。
なぜこの問題か
現在の大規模言語モデル(LLM)における推論能力の向上は、主に強化学習(RL)を用いた事後学習によって達成されています。具体的には、数学の問題に対する最終回答のチェックや、プログラミングタスクにおけるユニットテストなどの自動検証器を用いてモデルを最適化する手法が主流です。しかし、これらの手法によって得られる性能向上の本質的なメカニズムについては、研究者の間で活発な議論が続いています。近年の研究では、強化学習がモデルに全く新しい推論能力を覚えさせているのではなく、ベースモデルが元々持っていた確率分布を「先鋭化(Sharpening)」させているだけではないかという証拠が増えつつあります。つまり、複雑な問題を解くために必要な推論の軌跡は、学習前のベースモデルの中に既に潜在的に存在しており、強化学習は単に正しい答えに繋がる確率の塊を再形成しているに過ぎないという考え方です。 もし、事後学習済みのモデルが単にベースモデルの分布を先鋭化したものであるならば、外部の報酬や追加の学習に頼ることなく、ベースモデルの分布を直接操作するだけで同等の推論能力を引き出せるはずです。…
核心:何を提案したのか
本研究の核心的な提案は、グローバルなべき分布を、トークンレベルでスケーリングされた「低温サンプリング(Low-temperature sampling)」の形式で近似できるという理論的な発見です。著者らは、べき分布と低温分布の間の理論的な隔たりを埋めるために、新しい分解式を導き出しました。この定式化によれば、ある時点でのトークンの選択確率は、そのトークンが将来的にどれほど質の高い推論軌跡を生成できるかを示す「スケーリング因子」によって調整された低温分布として表現されます。これにより、従来のように全シーケンスに対して反復的なMCMCを実行する必要がなくなり、標準的な自己回帰的な生成プロセスの中で効率的にべき分布を近似することが可能になりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related