再パラメータ化フロー方策最適化
従来の再パラメータ化方策勾配(RPG)はガウス分布に基づく方策に限定されており、多峰性を持つ複雑な行動分布を表現する能力に欠けていたが、本研究では微分可能な常微分方程式(ODE)の積分を通じて行動を生成するフロー方策がRPGの枠組みと自然に適合することを明らかにした。
TL;DR(結論)
従来の再パラメータ化方策勾配(RPG)はガウス分布に基づく方策に限定されており、多峰性を持つ複雑な行動分布を表現する能力に欠けていたが、本研究では微分可能な常微分方程式(ODE)の積分を通じて行動を生成するフロー方策がRPGの枠組みと自然に適合することを明らかにした。 提案手法であるReparameterization Flow Policy Optimization(RFO)は、フロー生成プロセスとシステムダイナミクスの両方を通じて勾配を共同で逆伝播させることで、計算困難な対数尤度の計算を必要とせずに高いサンプル効率を実現し、さらに安定性と探索のための専用の正則化項を導入している。 多様な移動および操作タスクを用いた実験において、RFOは既存の最先端手法を一貫して上回る性能を示し、特に高次元の行動空間を持つ柔軟体四足歩行タスクでは、既存手法の約2倍の報酬を達成するとともに、視覚入力や複雑な物理シミュレーション環境下での有効性が確認された。
なぜこの問題か
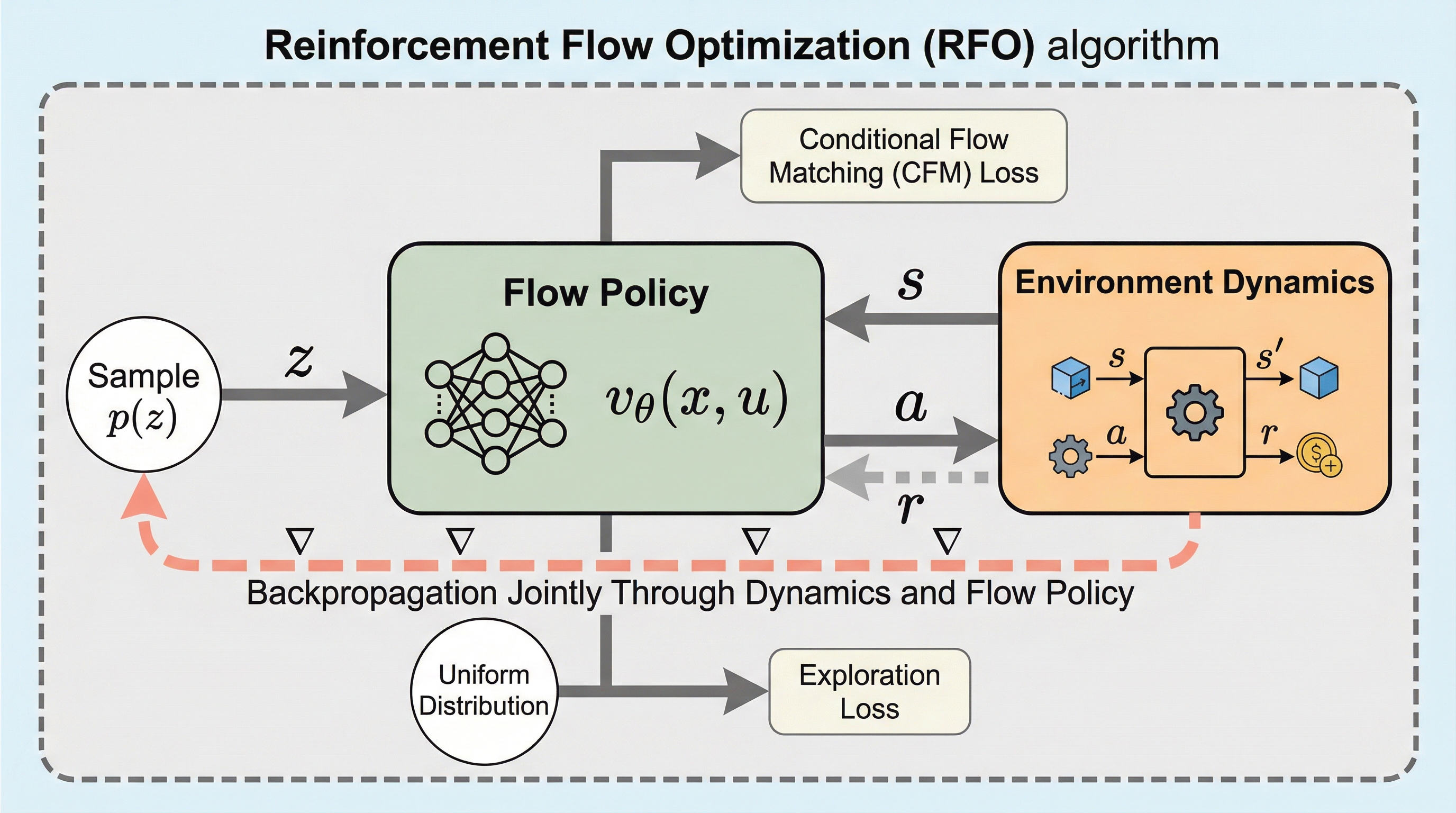
強化学習における再パラメータ化方策勾配(RPG)は、微分可能なダイナミクスを通じて勾配を逆伝播させることで、非常に高いサンプル効率を実現する強力なパラダイムとして知られている。この手法は、REINFORCEのような尤度比推定器と比較して勾配の分散が劇的に低いため、ロボット制御などの実用的かつ複雑なアプリケーションで大きな成果を上げてきた。しかし、これまでのRPGアプローチの多くはガウス分布に従う方策に限定されており、多峰性や非対称性を持つ複雑な行動分布をモデル化する表現力には限界があった。現実世界のロボット操作や複雑な環境では、単一のガウス分布では捉えきれない多様な行動の選択肢が存在するため、この制限は性能の頭打ちを招く要因となっていた。 一方で、生成モデルの一種であるフロー方策は、模倣学習において優れた表現力と推論速度、そして実装の簡潔さを示している。このフロー方策を強化学習に活用しようとする試みは近年増えているが、オンライン強化学習においてフロー方策を最適化する場合、計算が困難な行動の対数尤度を近似しなければならないという大きな課題が存在する。…
核心:何を提案したのか
本研究では、フロー方策を再パラメータ化方策勾配(RPG)の枠組みで最適化する新しいアルゴリズムであるReparameterization Flow Policy Optimization(RFO)を提案している。RFOの核心となる洞察は、フロー方策が本質的にソースノイズから行動への微分可能な写像をパラメータ化しているという点にある。これにより、フロー生成プロセス(ODEの積分)をロールアウト軌道の一部として捉え、システムダイナミクスとフロー方策の両方を一貫して逆伝播させることで、方策勾配を直接計算することが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related