マルチターンエージェントにおける対話の慣性の軽減
大規模言語モデル(LLM)をマルチターンエージェントとして利用する際、過去の自身の回答を過度に模倣して探索を阻害する「会話の慣性(Conversational Inertia)」という現象が特定されました。
TL;DR(結論)
大規模言語モデル(LLM)をマルチターンエージェントとして利用する際、過去の自身の回答を過度に模倣して探索を阻害する「会話の慣性(Conversational Inertia)」という現象が特定されました。 この問題を解決するため、環境からの報酬を必要とせずに短文と長文のコンテキストの差を利用してモデルの好みを調整する「Context Preference Learning(CPL)」と、推論時に履歴を定期的に整理する「Clip Context」が提案されました。 実験の結果、8つのエージェント環境と深層調査シナリオにおいて、提案手法は対角線上のアテンション(慣性)を大幅に減少させ、既存のウィンドウ方式や要約方式を上回る性能向上を達成し、計算効率の改善も実現しました。
なぜこの問題か
大規模言語モデル(LLM)は、適切なデモンストレーションが与えられた際に少数ショット学習者(few-shot learners)として優れた能力を発揮しますが、この強みはマルチターンのエージェントシナリオにおいては深刻な問題を引き起こすことが明らかになりました。エージェントが環境と対話を重ねる中で、LLMは過去の自分自身の回答を少数ショットの例として誤って模倣してしまい、その結果として新しい探索が制限される「模倣バイアス」が生じます。研究チームがアテンション分析を行ったところ、モデルが過去の回答に対して強い対角線状のアテンションを示す「会話の慣性」という現象が特定されました。これは、現在の回答の特定のトークンが、過去の回答の同じ位置にあるトークンに対して不釣り合いに注目している状態を指します。 この慣性は、エージェントが環境からの新しいフィードバックに適応するのではなく、過去の応答パターンを単に繰り返す原因となります。さらに、コンテキストが長くなるほど、システムプロンプトへのアテンションが減少し、タスク固有の指示に従うよりも対話履歴からの少数ショット学習に過度に依存する傾向が見られました。…
核心:何を提案したのか
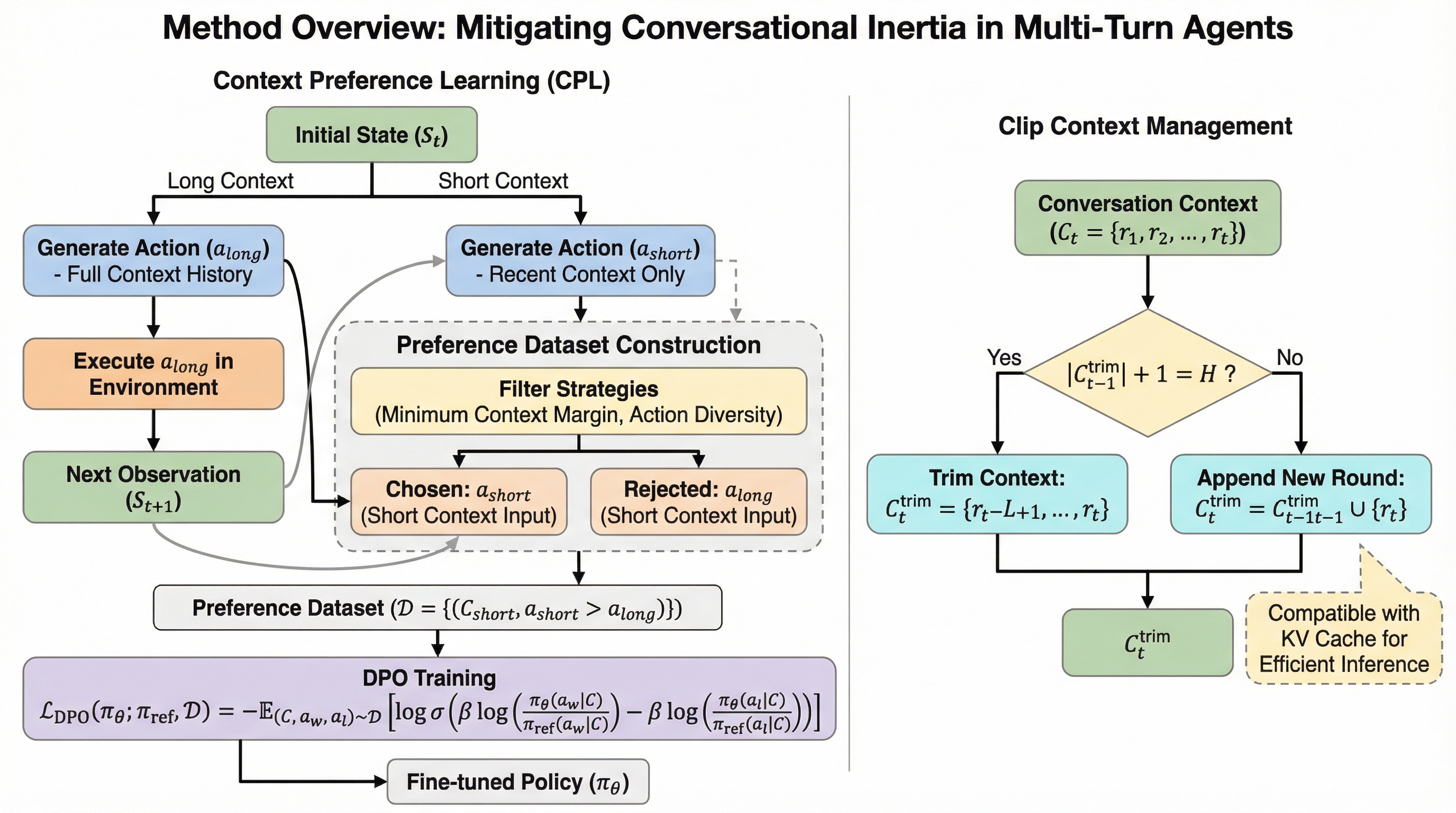
本研究では、会話の慣性を軽減するために「Context Preference Learning(CPL)」と「Clip Context」という2つの主要なアプローチを提案しています。CPLの核心的な洞察は、同一の状態において、長いコンテキストで生成された行動は短いコンテキストで生成された行動よりも強い慣性を示すという点にあります。この性質を利用することで、環境からの報酬信号や専門家によるデモンストレーションを一切必要とせずに、モデルの好みを調整するための「強・弱慣性ペア」を構築することが可能になりました。これは、モデル自身の出力を比較対象とする自己教師あり学習の一種と言えます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related