ジャストインタイム強化学習:勾配更新なしのLLMエージェントにおける継続学習
大規模言語モデル(LLM)エージェントがデプロイ後に新しい環境へ適応できないという「重みの固定」問題を解決するため、勾配更新を一切行わずに推論時に方策を最適化する「Just-In-Time Reinforcement Learning(JitRL)」が提案されました。
TL;DR(結論)
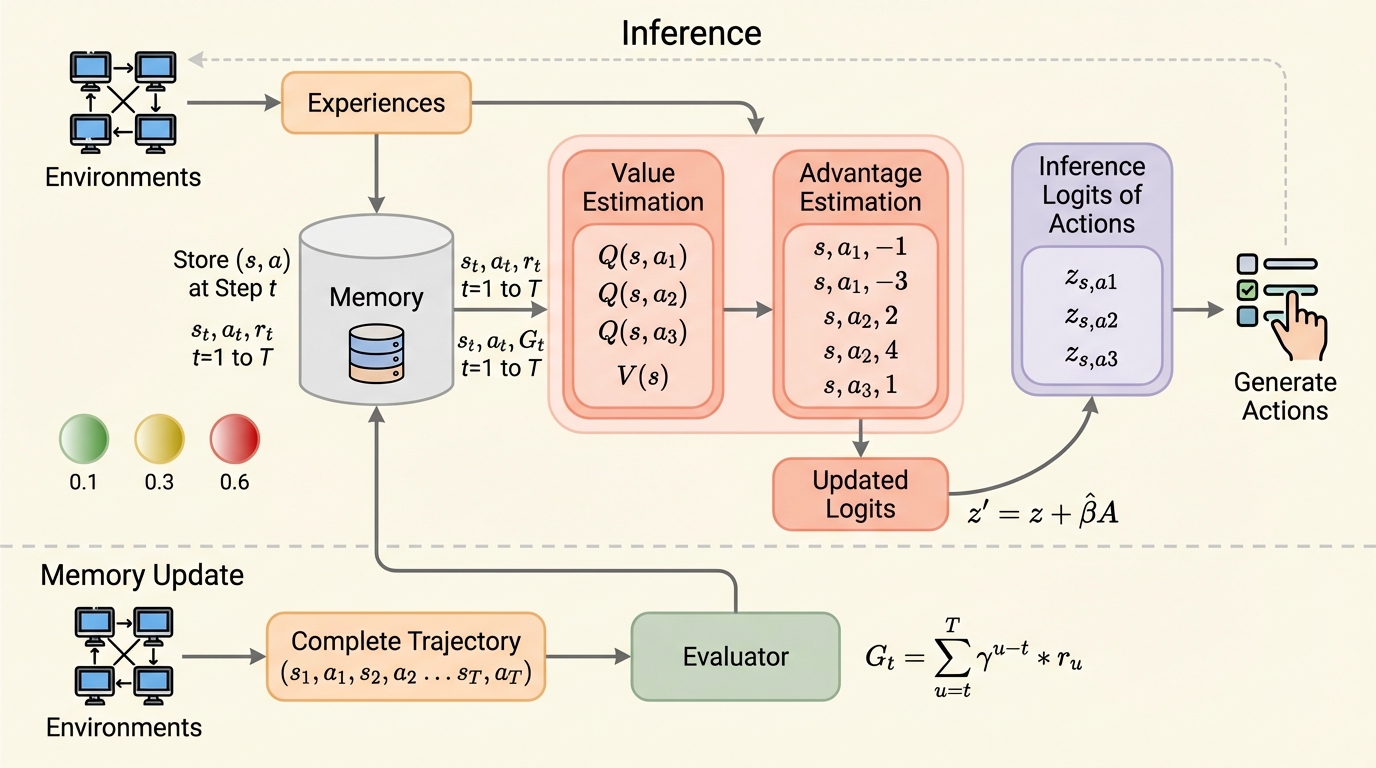
大規模言語モデル(LLM)エージェントがデプロイ後に新しい環境へ適応できないという「重みの固定」問題を解決するため、勾配更新を一切行わずに推論時に方策を最適化する「Just-In-Time Reinforcement Learning(JitRL)」が提案されました。 この手法は、過去の経験を動的な非パラメトリックメモリに蓄積し、現在の状態に類似した軌跡を検索して行動のアドバンテージを推定することで、LLMの出力ロジットを直接調整し、KL制約付き方策最適化の厳密な閉形式解として機能します。 WebArenaやJerichoを用いた実験において、JitRLは従来の学習不要な手法を上回る最高水準の性能を達成し、計算コストの高い微調整手法であるWebRLに対しても30倍以上のコスト削減を実現しながら、未知のタスクへの高い汎用性と継続的な自己進化の可能性を示しました。
なぜこの問題か
現在の人工知能(AI)エージェント、特に大規模言語モデルを基盤とするシステムは、トレーニングが完了して実環境にデプロイされた後はモデルの重みが固定されてしまうという本質的な制約を抱えています。このため、エージェントが新しい環境や動的に変化する状況に投入された際、自身の経験から即座に学習して適応することができず、同じ過ちを何度も繰り返してしまうという実用上の大きな問題が生じています。これは、実地訓練を受けないまま現場に送り出された新入社員が、どれだけ経験を積んでも業務効率が改善しない状況に似ています。人間は日々の活動を通じて「その場で」学習し、失敗を糧に能力を向上させることができますが、現在のAIシステムはこの「継続的に学習する能力」が最も欠如していると指摘されています。 この問題を解決するために、従来は方策勾配を更新し続ける継続的な強化学習が検討されてきましたが、これには膨大な計算リソースが必要であり、さらに新しい知識を習得する過程で過去に学んだ重要な能力を失ってしまう「破滅的忘却」のリスクが常に付きまといます。…
核心:何を提案したのか
本研究では、勾配更新を必要とせずにテスト時の推論プロセスの中で方策を最適化する「ジャストインタイム強化学習(JitRL)」という革新的なフレームワークを提案しています。JitRLの核心は、エージェントの重みを固定したまま、過去の経験を動的なメモリとして保持し、推論の瞬間にその知識を動員して行動を修正する点にあります。具体的には、過去の「状態、行動、報酬」のセットを蓄積し、現在の状況に類似した過去の事例を検索することで、どのアクションがどれほど優れているかを示す「アドバンテージ」を即座に推定します。この推定値を用いて、大規模言語モデルが出力するロジット(確率の元となる値)を直接調整することで、モデルの振る舞いを最適化します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related