DeltaEvolve:モメンタム駆動型進化による科学的発見の加速
大規模言語モデル(LLM)を用いた従来の進化型エージェントは、過去の全コード履歴をコンテキストに詰め込むため、トークン消費が膨大になり、重要なアルゴリズムの核となるアイデアが実装の詳細に埋もれてしまうという課題を抱えていた。
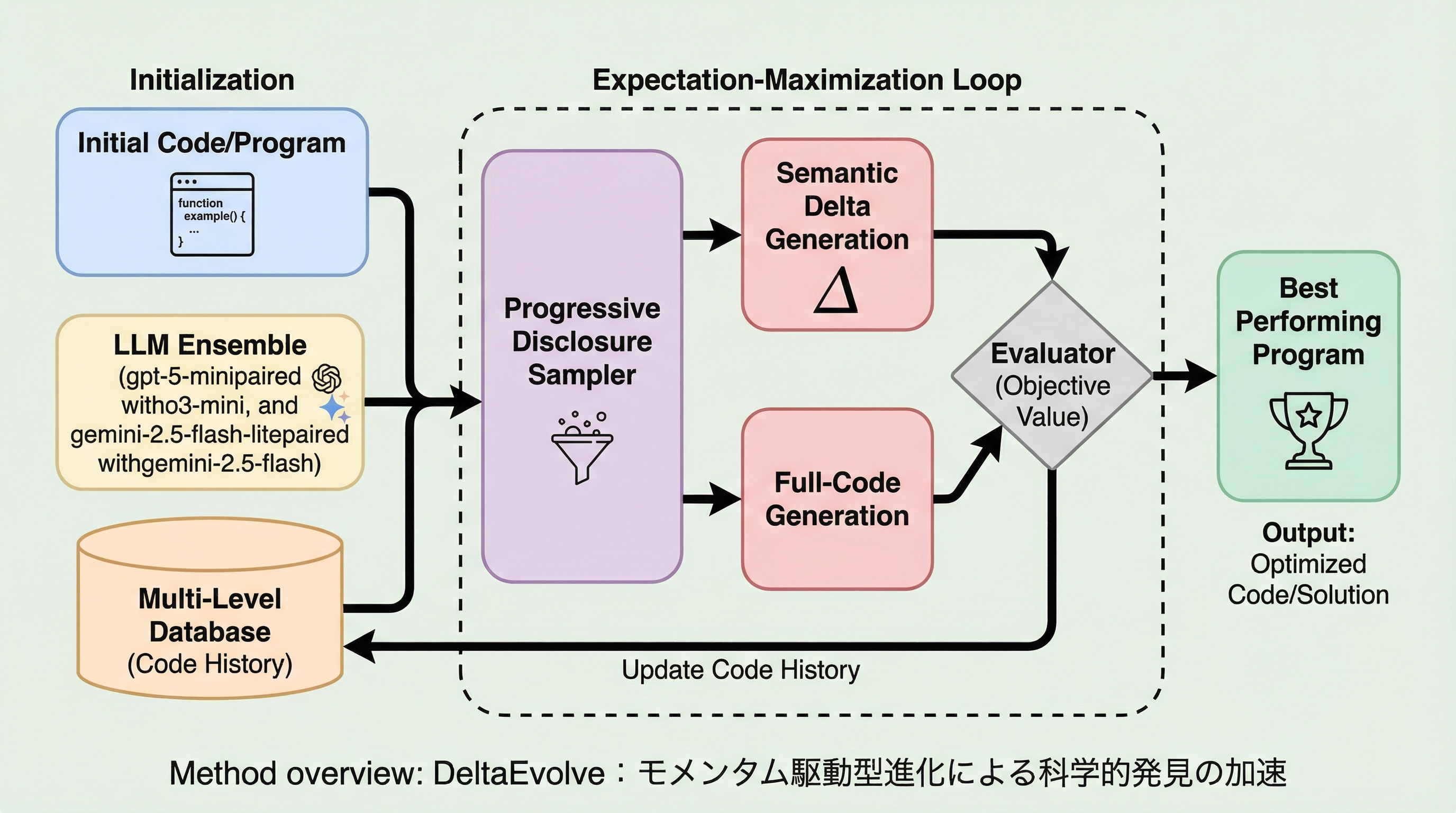
TL;DR(結論)
大規模言語モデル(LLM)を用いた従来の進化型エージェントは、過去の全コード履歴をコンテキストに詰め込むため、トークン消費が膨大になり、重要なアルゴリズムの核となるアイデアが実装の詳細に埋もれてしまうという課題を抱えていた。 本研究が提案するDeltaEvolveは、進化プロセスを期待値最大化(EM)フレームワークとして厳密に定式化し、全コードの代わりに変更内容とその性能への影響を構造化した「セマンティック・デルタ」を保存・活用することで、効率的な探索を実現する。 5つの科学的ドメインでの検証の結果、DeltaEvolveは従来手法と比較してトークン消費量を平均36.79%削減しながら、より高品質な解を発見することに成功し、計算資源を抑えつつ自己進化の性能を最大化する新たな枠組みを提示した。
なぜこの問題か
大規模言語モデル(LLM)を活用した進化型エージェントは、数学的最適化、物理システム、分子発見といった多様な科学的ドメインにおいて、自動化された発見を推進する有望な手法として注目されている。これらのタスクの核心は、直接合成することは困難だが評価は容易な解を探索する問題であり、コードという表現形式を用いることで、複雑なアルゴリズムの記述と実行による自動評価が可能になる。しかし、既存のAlphaEvolveやFunSearchといった自己進化型システムには、解決すべき2つの根本的な限界が存在している。 第一の限界は、コンテキストウィンドウの制約に伴う効率性の欠如である。進化の過程で生成される多数のプログラム履歴をすべて保持しようとすると、計算コストと遅延が許容できないほど増大し、進化の履歴を十分に活用できなくなる。既存手法では上位のプログラムのみを保持するなどの工夫をしているが、複雑なシステムでは個々のプログラム自体が長大であるため、履歴情報を再利用するための容量がすぐに不足してしまう。これは、推論時の計算量を増やすことで性能を向上させる「テストタイム・スケーリング」の恩恵を十分に享受できないことを意味する。…
核心:何を提案したのか
本研究では、進化型エージェントを「期待値最大化(EM)フレームワーク」として厳密に定式化し、その視点からDeltaEvolveという新しい枠組みを提案している。この定式化において、LLMが候補プログラムをサンプリングする過程をEステップ、評価フィードバックに基づいてコンテキストを更新する過程をMステップと定義した。既存手法のようにフルコードの履歴をコンテキストに含めることは、現在の状態は捉えているものの、どの変更が性能の向上や低下を招いたのかを不明瞭にするため、不十分なMステップであると指摘している。 DeltaEvolveの核心的な提案は、フルコードの代わりに「セマンティック・デルタ(Semantic Delta)」を用いることである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related