CORE: 相互教育を通じた協調的推論フレームワーク
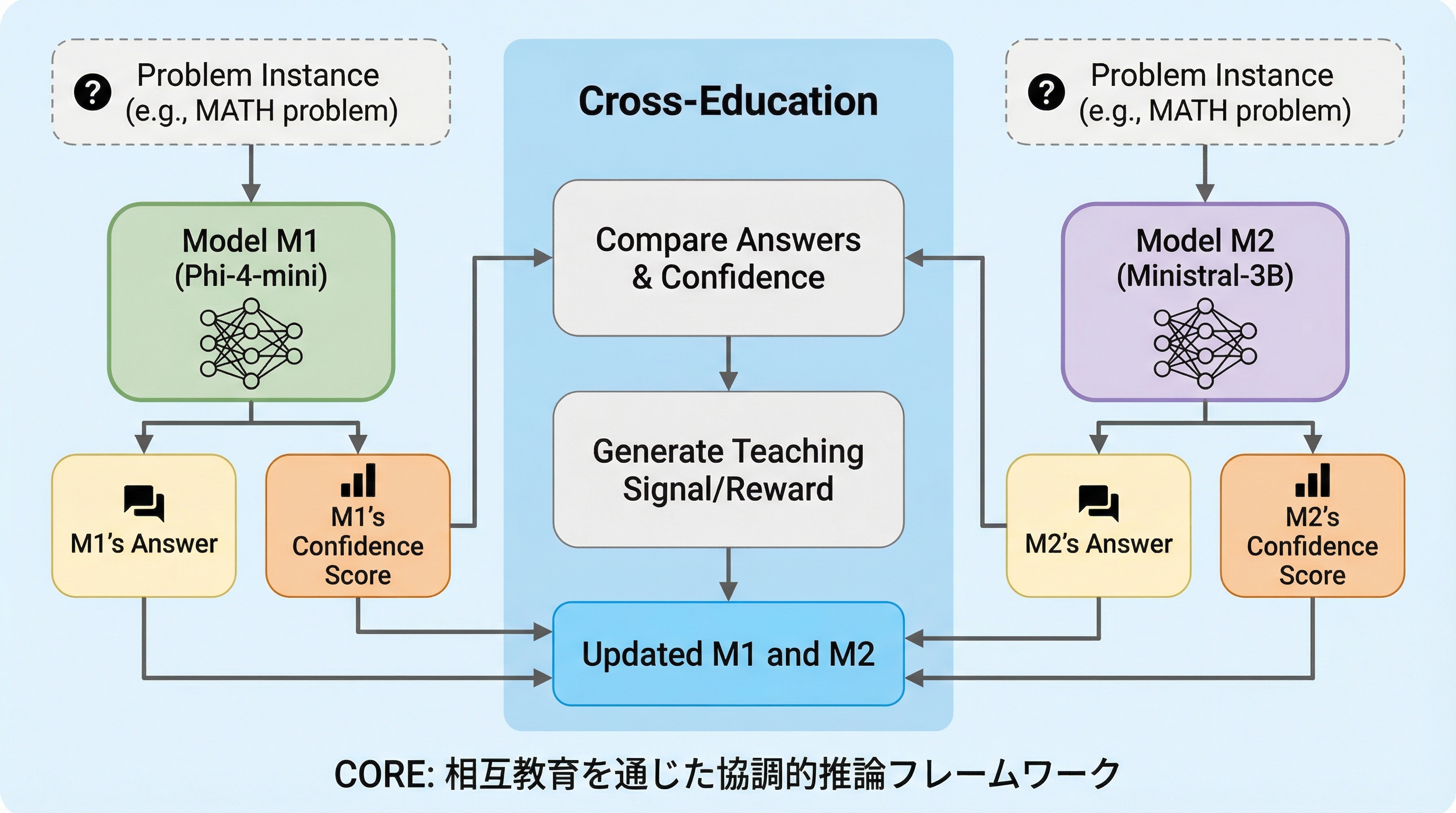
CORE(Collaborative Reasoning)は、複数の大規模言語モデルを訓練時に相互教育させることで、推論能力を飛躍的に向上させる新しい学習フレームワークである。 独立して問題を解く「コールドラウンド」と、成功した他者のヒントを元に解き直す「レスキューラウンド」の2段階構成により、モデル間の誤りの重複を減らし、相補的な能力を育成する。 わずか1,000例以下の学習データを用いた実験では、GSM8Kで99.54%、MATHで92.08%という極めて高いチーム正解率を達成し、モデルサイズを拡大せずに推論の信頼性を大幅に高めることに成功した。
TL;DR(結論)
CORE(Collaborative Reasoning)は、複数の大規模言語モデルを訓練時に相互教育させることで、推論能力を飛躍的に向上させる新しい学習フレームワークである。 独立して問題を解く「コールドラウンド」と、成功した他者のヒントを元に解き直す「レスキューラウンド」の2段階構成により、モデル間の誤りの重複を減らし、相補的な能力を育成する。 わずか1,000例以下の学習データを用いた実験では、GSM8Kで99.54%、MATHで92.08%という極めて高いチーム正解率を達成し、モデルサイズを拡大せずに推論の信頼性を大幅に高めることに成功した。
なぜこの問題か
大規模言語モデル(LLM)は、思考の連鎖(Chain-of-Thought)を用いることで複雑な多段階の推論問題を解くことができるが、依然として系統的かつ相補的な誤りを犯すという課題がある。 異なるアーキテクチャや学習データを持つモデルは、同じデータセットに対しても異なる箇所で失敗する傾向があり、既存の手法ではこの多様性を推論時のアンサンブルやマルチエージェントの対話によって活用しようとしてきた。 しかし、自己整合性(Self-consistency)や検索ベースの枠組みといった推論時の工夫は、計算コストを増大させるものの、モデル自体の根本的な方策(ポリシー)を改善するものではない。 さらに、複数のモデルが同じ重要な洞察を見逃す「相関した失敗」が発生した場合、単にサンプル数を増やしたりエージェントを増やしたりしても、同じ誤った結論に収束してしまうという限界がある。 アンサンブルによる利得は、構成要素となるモデル間の誤りに相関がある場合に制限されることが知られており、モデル同士がいかに協力して互いの弱点を補うかが重要な焦点となっている。…
核心:何を提案したのか
本論文では、複数のLLMを協調的に訓練するための新しいアルゴリズムである「CORE(Collaborative Reasoning)」を提案している。 COREの核心は「相互教育(Cross-Teaching)」プロトコルにあり、これは各問題を2つのマイクロラウンドに分けて処理する仕組みである。 第1段階の「コールドラウンド」では、各モデルが独立して複数の推論トレースを生成し、その中で少なくとも1つのモデルが成功したかどうかを確認する。 もし成功したモデルがいれば、その成功した推論トレースから「ヒント」を抽出し、失敗したモデルに提供するための「教師コンテキスト」を構築する。 第2段階の「レスキューラウンド」では、失敗したモデルがこのヒントを条件として再度問題に挑戦し、ヒントを得て正解に到達できた場合には特別な「レスキューボーナス」を与える。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related