CORE: 相互教授による協調的推論
CORE(Collaborative Reasoning)は、複数の大規模言語モデルが互いの成功例を学習信号として活用する「相互教授(Cross Teaching)」という革新的なフレームワークを提案し、モデル間の相補的な推論能力を飛躍的に向上させる手法である。
TL;DR(結論)
CORE(Collaborative Reasoning)は、複数の大規模言語モデルが互いの成功例を学習信号として活用する「相互教授(Cross Teaching)」という革新的なフレームワークを提案し、モデル間の相補的な推論能力を飛躍的に向上させる手法である。 独立して問題を解く「コールドラウンド」と、他者の成功をヒントに再試行する「レスキューラウンド」の二段階構成に加え、多様性を促すDPP-lite報酬と救済ボーナスを組み合わせることで、モデル間でのエラーの重複を最小化することに成功した。 わずか1,000件の学習データを用いた3Bと4Bの小規模モデルペアにおいて、GSM8Kで99.54%、MATHで92.08%という極めて高いチーム正解率を達成し、モデル規模を拡大せずとも高度な協調が可能であることを証明した。
なぜこの問題か
現在の大規模言語モデル(LLM)は、思考の連鎖(Chain-of-Thought)を用いることで複雑な多段階の推論問題を解く能力を得ているが、依然として系統的なエラーを完全に排除することはできていない。興味深いことに、異なるアーキテクチャや学習データを持つモデル間では、同じ問題に対しても一方が成功し他方が失敗するという「相補的なエラーモード」が存在することが知られている。従来の研究では、推論時に複数の回答を生成して多数決を取るアンサンブル手法や、複数のエージェントを対話させる手法によってこの多様性を利用してきた。しかし、これらの手法は推論時の計算コストを大幅に増大させる一方で、モデル自体の推論ポリシーを根本的に改善するものではないという課題があった。 また、単純なアンサンブルは、モデル同士のエラーが相関している場合、つまり全てのモデルが同じ箇所でつまずく場合には、モデル数を増やしても正解率が向上しないという限界がある。学習段階でモデル同士を協調させる試みは、正解に対する教師信号が希薄であることや、モデルが互いの出力を単に模倣し合うことで多様性が失われる「多様性の崩壊」のリスクがあるため、非常に困難な課題とされてきた。…
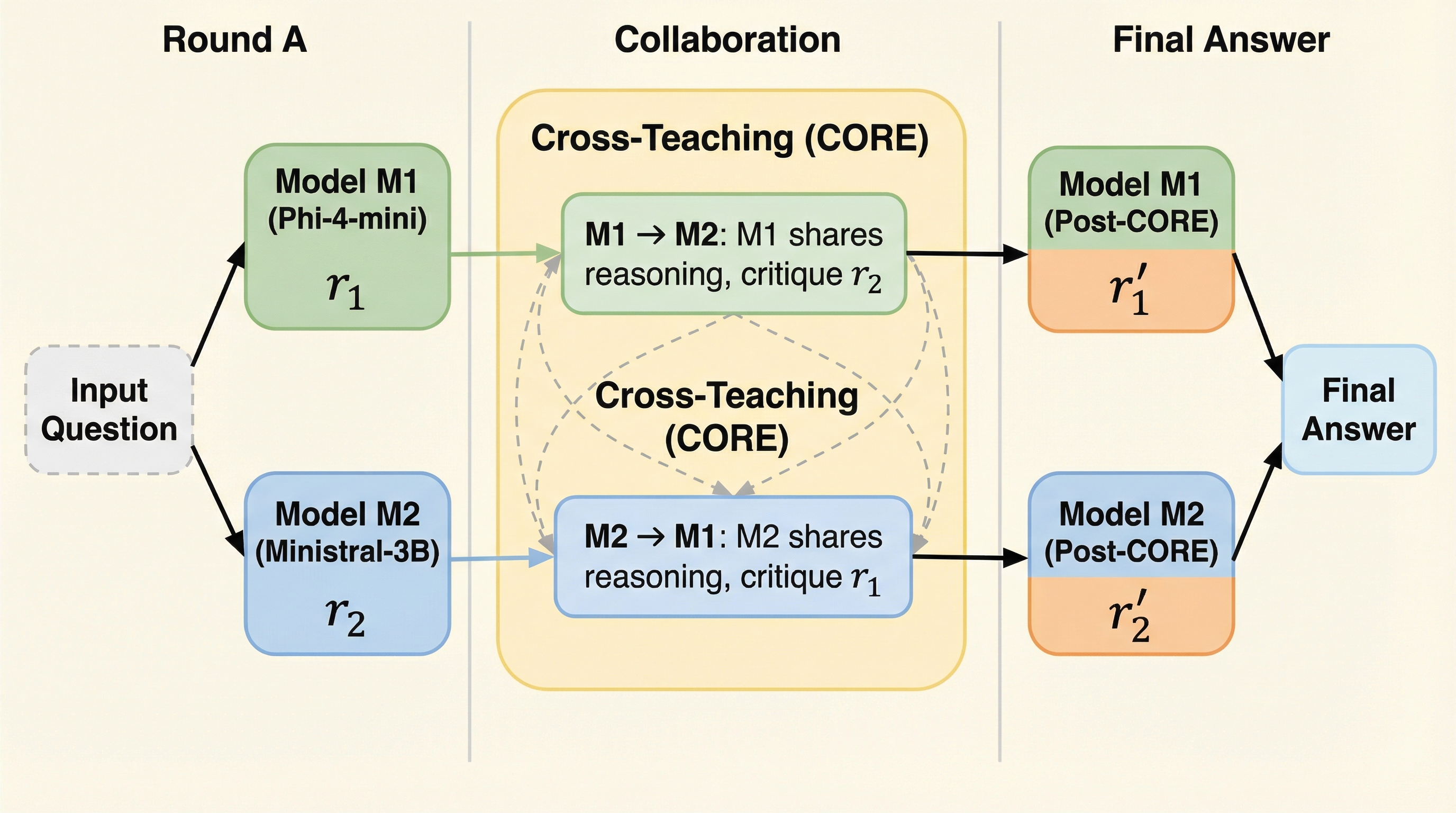
核心:何を提案したのか
本論文が提案する「CORE(Collaborative Reasoning)」は、複数の大規模言語モデルを協調的に学習させるための新しいアルゴリズムである。この手法の核心は、あるモデルの成功を別のモデルの学習信号へと変換する「相互教授(Cross Teaching)」プロトコルにある。COREでは、各学習ステップにおいて「コールドラウンド」と「レスキューラウンド」という二つのマイクロラウンドを実行する。まず、各モデルが独立して問題を解き、もし少なくとも一つのモデルが正解に到達したならば、その正解に至る推論過程を「ヒント」として抽出する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related