CORE: 相互教育を通じた協調的推論フレームワーク
1. COREは、複数の大規模言語モデルが「相互教育(Cross Teaching)」を通じて互いの推論エラーを補完し合う、トレーニング段階の新しい協調学習フレームワークであり、モデル間の相補性を直接的に最適化する。 2.
TL;DR(結論)
- COREは、複数の大規模言語モデルが「相互教育(Cross Teaching)」を通じて互いの推論エラーを補完し合う、トレーニング段階の新しい協調学習フレームワークであり、モデル間の相補性を直接的に最適化する。
- 独立して問題を解く「コールド・ラウンド」と、成功した仲間の解法をヒントに失敗したモデルが再挑戦する「レスキュー・ラウンド」の二段階で学習し、チーム全体の正答率を最大化することに成功した。
- わずか1,000件の学習データを用いた実験で、30億と40億パラメータの小規模モデルのペアが、GSM8Kで99.54%、MATHで92.08%という極めて高いチーム正答率を達成し、モデルの規模を拡大せずに性能を大幅に向上させた。
なぜこの問題か
現在の大規模言語モデルは、中間的な推論ステップを生成させることで複雑な多段階推論問題を解決できるが、依然として体系的かつ相補的な失敗を示すことが大きな課題となっている。異なるアーキテクチャや学習データを持つモデルであっても、同じデータセットに対して特定のモデルが成功する一方で別のモデルが失敗するという、エラーパターンの違いが存在する。従来の手法では、推論時に複数のモデルの回答を組み合わせるアンサンブルやマルチエージェントによる議論が行われてきたが、これらは推論時の計算量を増やすだけであり、モデル自体の基礎的な能力を向上させるものではない。また、複数のモデルが同じような間違いを犯す「相関した失敗(Correlated Failure)」が発生した場合、単にモデルの数を増やしたりサンプル数を増やしたりしても、同じ誤った結論に収束してしまうという限界がある。…
核心:何を提案したのか
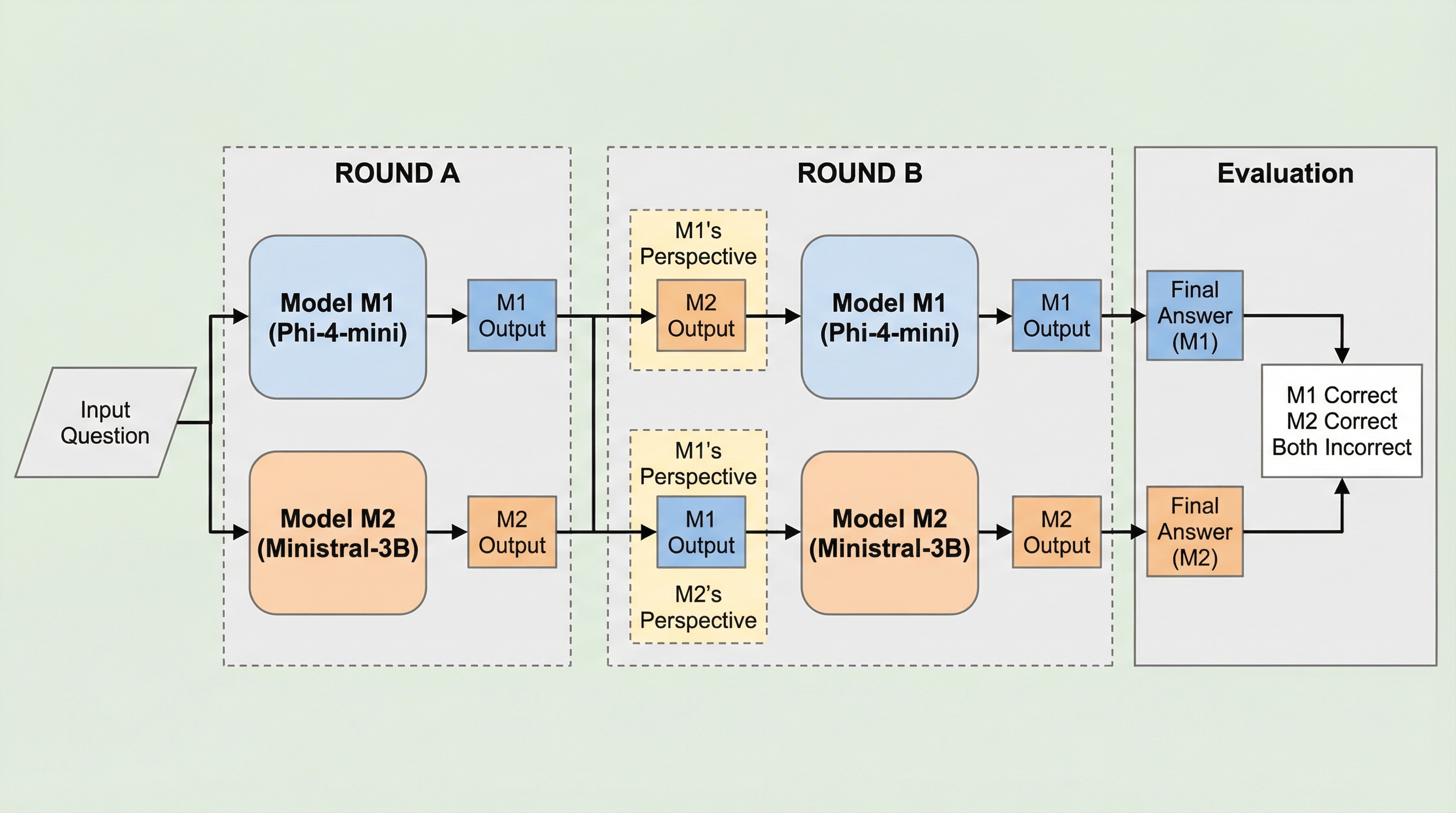
本論文では、複数の大規模言語モデルを協調して推論タスクに取り組ませるための学習アルゴリズム「CORE(Collaborative Reasoning)」を提案している。COREの核心は、仲間の成功を学習信号に変換する「マイクロラウンド・プロトコル」という二段階の学習プロセスにある。第一段階の「コールド・ラウンド」では、各モデルが独立して複数の推論トレースを生成し、自力で問題を解くことを試みる。もし少なくとも一つのモデルが成功した場合、その成功したトレースからヒントを抽出し、第二段階の「コンテキスチュアル・レスキュー・ラウンド」へと進む。このレスキュー・ラウンドでは、第一段階で失敗したモデルが、成功した仲間のヒントを条件として再度問題を解き、正解にたどり着いた場合に特別な報酬を与える仕組みとなっている。 これにより、特定のモデルが苦手とする問題に対して、仲間の成功をターゲットを絞った教師信号として利用することが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related