模倣を超えて:能動的潜在計画のための強化学習
大規模言語モデルの推論において、従来の潜在推論手法は単一の正解ラベルを模倣することに固執しており、多様な推論経路が存在する問題に対して最適なポリシーを構築できず、訓練とテストの間に性能の乖離が生じるという課題がありました。
TL;DR(結論)
大規模言語モデルの推論において、従来の潜在推論手法は単一の正解ラベルを模倣することに固執しており、多様な推論経路が存在する問題に対して最適なポリシーを構築できず、訓練とテストの間に性能の乖離が生じるという課題がありました。 本研究が提案するATP-Latentは、変分オートエンコーダ(VAE)の枠組みを導入して滑らかで均一な潜在空間を構築し、強化学習によって能動的な推論計画を行うことで、単なる模倣を超えた汎用的な推論能力と高いトークン効率を獲得することに成功しました。 LLaMA-1Bを用いた数値推論ベンチマークの実験では、既存の先進的な手法と比較して正確性が4.1パーセント向上し、同時に推論に必要なトークン消費量を3.3パーセント削減しており、効率的かつ高精度な推論プロセスを自律的に構築できることが証明されました。
なぜこの問題か
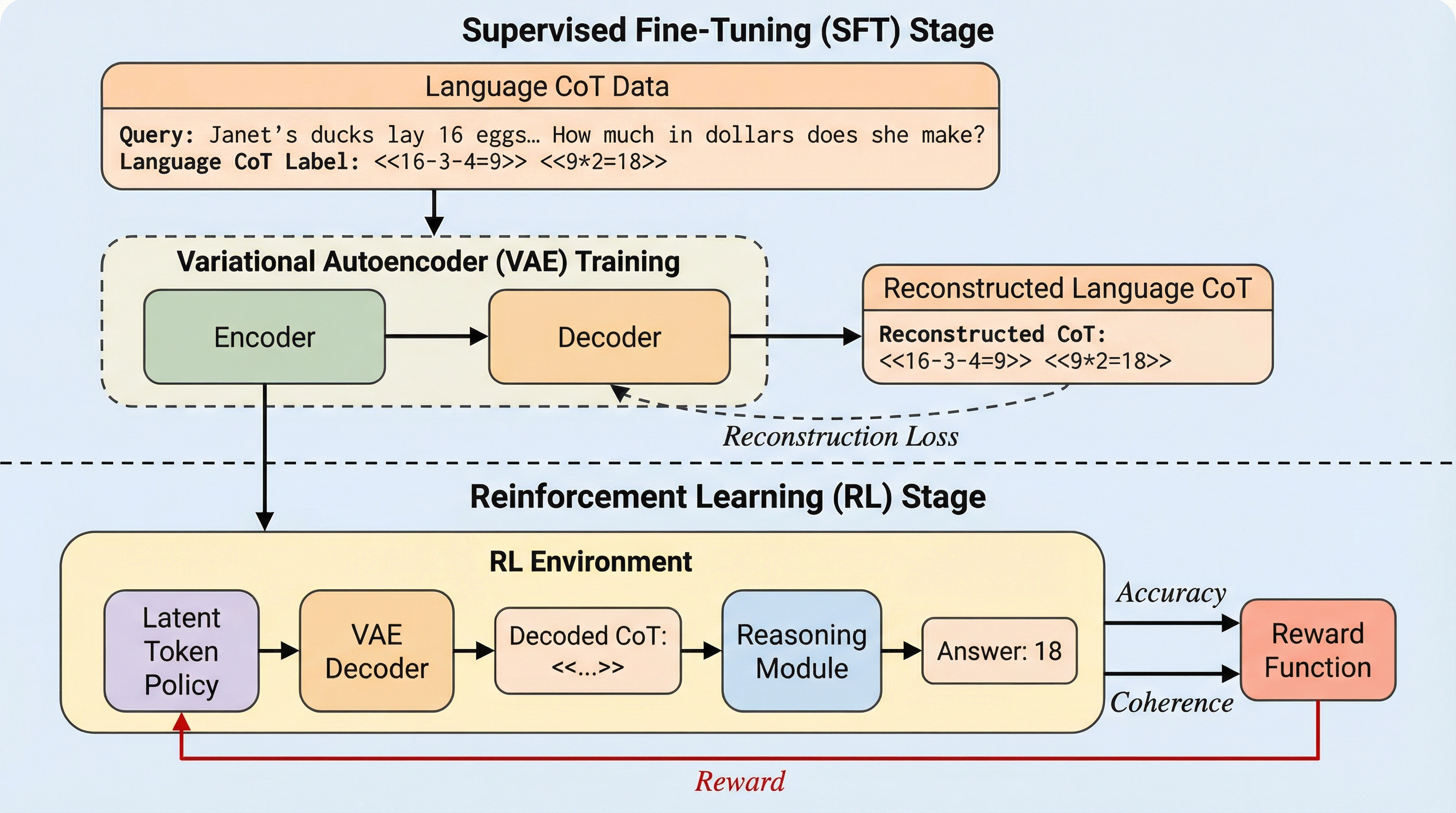
大規模言語モデル(LLM)は、思考の連鎖(CoT)という手法を用いることで複雑な数学的推論において高い能力を発揮しますが、このプロセスを強化しようとすると推論パスが非常に長くなる「オーバーシンキング」という副作用が生じ、リアルタイムな応答を妨げる要因となっています。この遅延問題を解決するために、離散的な言語トークンの代わりに連続的なベクトルである潜在トークンを用いてモデル内部で推論を行う「潜在推論」という手法が注目を集めています。潜在推論は、文法を整えるためだけの言葉や冗長な表現を排除し、情報の密度を飛躍的に高めることができるため、限られたトークン数で高い推論性能を実現できる可能性を秘めています。 しかし、既存の潜在推論手法には大きな弱点がありました。それは、学習プロセスが特定の言語ラベルを「模倣」することに過度に依存している点です。数学の問題などでは、答えに至るまでの論理的な道筋は一つとは限らず、複数の等価で正しい推論パスが存在します。それにもかかわらず、モデルが任意に選ばれた一つのラベルだけを模倣するように訓練されると、潜在トークンの表現がその特定のパターンに過学習してしまいます。…
核心:何を提案したのか
本研究が提案する「ATP-Latent(Active Latent Planning)」は、潜在トークンの生成プロセスを能動的な計画問題として捉え直し、二段階のアプローチで最適化する新しい手法です。第一段階の教師あり学習(SFT)では、従来の模倣学習を拡張し、変分オートエンコーダ(VAE)の枠組みを導入しています。ここでは、LLMをエンコーダとして機能させ、潜在トークンを生成すると同時に、別のLLMをデコーダとして用いて、その潜在トークンがどのような言語的意味を持っているのかを復元させます。このプロセスにより、潜在空間は単なる数値の羅列ではなく、意味的に整合性の取れた滑らかで均一な表現空間へと変貌します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related