模倣を超えて:能動的潜在プランニングのための強化学習
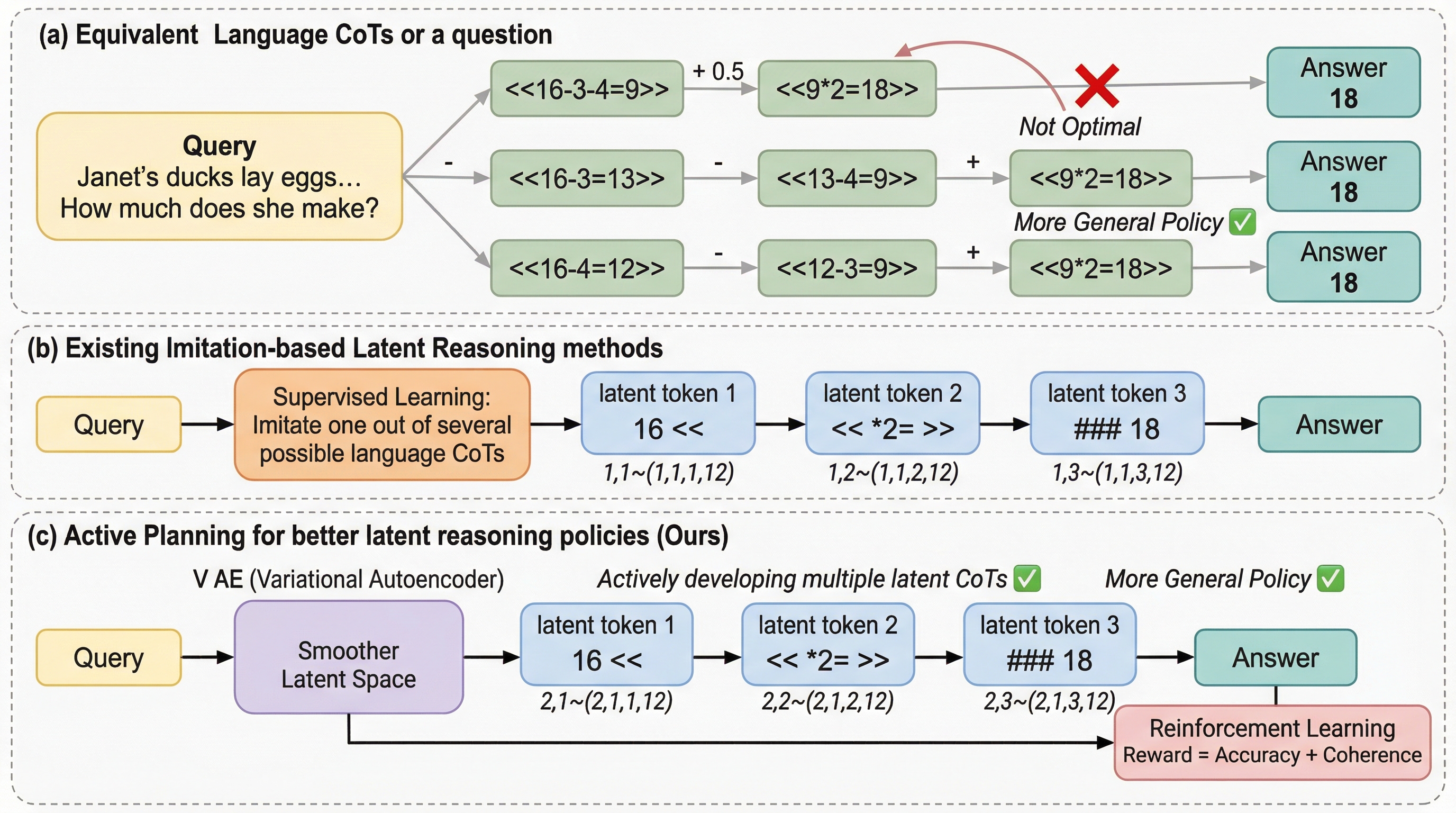
従来の潜在推論手法は、単一の言語ラベルを模倣する受動的な学習に依存しており、複数の正解経路が存在する複雑な推論問題において、特定の解法に過剰適合し汎用性が低下するという課題がありました。 本研究が提案するATP-Latentは、条件付き変分自己符号化器(VAE)を用いて滑らかな潜在空間を構築し、強化学習を通じて最適な推論経路を自律的に探索・計画する「能動的プランニング」の枠組みを導入しています。 LLaMA-1Bを用いた実験では、従来の模倣ベースの手法と比較して、主要な数値推論ベンチマークで正解率を4.1%向上させつつ、使用するトークン数を3.3%削減することに成功し、高密度で効率的な推論の有効性を実証しました。
TL;DR(結論)
従来の潜在推論手法は、単一の言語ラベルを模倣する受動的な学習に依存しており、複数の正解経路が存在する複雑な推論問題において、特定の解法に過剰適合し汎用性が低下するという課題がありました。 本研究が提案するATP-Latentは、条件付き変分自己符号化器(VAE)を用いて滑らかな潜在空間を構築し、強化学習を通じて最適な推論経路を自律的に探索・計画する「能動的プランニング」の枠組みを導入しています。 LLaMA-1Bを用いた実験では、従来の模倣ベースの手法と比較して、主要な数値推論ベンチマークで正解率を4.1%向上させつつ、使用するトークン数を3.3%削減することに成功し、高密度で効率的な推論の有効性を実証しました。
なぜこの問題か
大規模言語モデル(LLM)における思考の連鎖(CoT)は、数学的推論などの複雑なタスクで高い能力を発揮しますが、推論過程が長くなることでリアルタイム性が損なわれるという課題があります。この遅延を解消するために、離散的な言語トークンの代わりに連続的な潜在トークンを用いて推論を行う「潜在推論」の研究が進められてきました。潜在推論は、構文維持や説明のためだけの冗長なトークンを排除し、情報の密度を高めることで、限られたトークン予算内での性能向上を可能にします。しかし、既存の潜在推論手法の多くは、あらかじめ用意された言語ラベルを模倣するようにモデルを微調整する「模倣ベース」の戦略を採用しています。 推論問題には、答えが同じであっても解法や説明の仕方が異なる「等価で多様なCoTラベル」が複数存在することが一般的です。特定の一つのラベルだけを受動的に模倣する学習では、潜在トークンの表現がそのラベルに過剰適合してしまい、汎用的な推論方策の獲得が困難になります。その結果、訓練データには適応できても未知のテストデータでは性能が低下するという、訓練とテストの間の明確な乖離が生じていました。…
核心:何を提案したのか
本論文では、潜在トークンの表現空間において能動的なプランニングを実現する新しい手法「ATP-Latent(Active Latent Planning)」を提案しています。この手法の核心は、潜在推論の学習プロセスを単なる模倣から、強化学習(RL)を用いた能動的な探索へと転換させた点にあります。ATP-Latentは大きく分けて、教師あり微調整(SFT)ステージと強化学習(RL)ステージの二段階で構成されています。第一段階のSFTステージでは、従来の模倣手法を拡張し、条件付き変分自己符号化器(VAE)の枠組みを導入することで、解釈可能かつ滑らかな潜在トークンの表現空間を構築します。 第二段階のRLステージでは、最終的な回答の正解率だけでなく、生成された潜在トークンの一貫性を評価する独自の報酬系を用いて、推論方策を能動的に最適化します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related