分散型LLM推論ネットワークのための適応的かつ堅牢なコスト意識型品質証明
分散型LLM推論ネットワークにおいて、悪意ある評価者によるスコア操作や評価者の不均一性が合意形成を歪める課題に対し、中央値やトリム平均を用いた堅牢な集計ルールと、過去の乖離に基づく適応的な信頼重み付けメカニズムを導入した。
TL;DR(結論)
分散型LLM推論ネットワークにおいて、悪意ある評価者によるスコア操作や評価者の不均一性が合意形成を歪める課題に対し、中央値やトリム平均を用いた堅牢な集計ルールと、過去の乖離に基づく適応的な信頼重み付けメカニズムを導入した。 この手法は、ノイズ注入やサボタージュなどの攻撃下でも、単純平均より高い精度で正解データとの整合性を維持し、推論ノードと評価者の双方に対して品質とコストのバランスに基づいた公平な報酬分配を可能にすることを実証した。 実験を通じて、評価者のサンプリング数(K)を増やすことでシステムの堅牢性は向上するものの、個々の評価者の報酬が減少し分散が増大するという運用上のトレードオフを明らかにし、実用的なネットワーク設計の指針を提示した。
なぜこの問題か
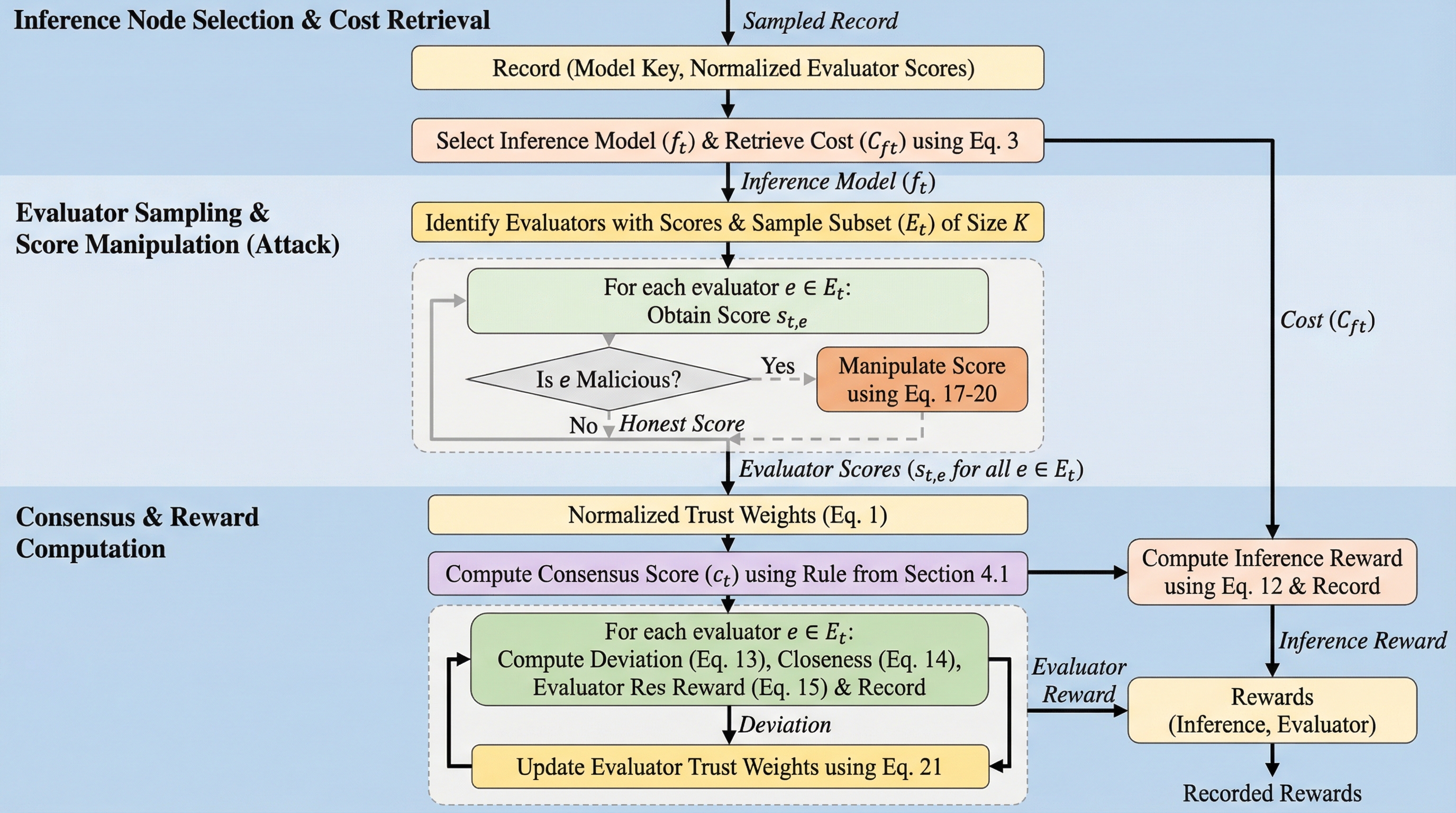
分散型の大型言語モデル(LLM)推論ネットワークは、中央集権的な管理を排除し、透明性と検閲耐性を備えたAI機能へのオープンなアクセスを提供することを目指している。しかし、このようなネットワークにおいて、出力の品質を大規模かつ低コストで検証する仕組みを構築することは極めて困難である。現代のトランスフォーマーモデルに対する暗号学的な検証は、対話的な遅延が求められる環境では計算コストが非常に高く、実用的ではないという課題がある。そのため、多くの実用的なシステムでは、軽量な評価モデルによる信号を集計して品質を近似する「Proof of Quality(PoQ)」という手法に依存している。 先行研究で提案されたコスト意識型のPoQは、出力品質と計算コストのバランスを取りながら報酬を分配する仕組みを提供したが、オープンな参加設定における脆弱性が残されていた。具体的には、評価者が不均一であったり、悪意を持ってスコアを操作したりする場合、ネットワーク全体の合意が歪められ、不当な報酬の支払いや低品質な出力の選択を招くリスクがある。…
核心:何を提案したのか
本論文では、敵対的な評価者に対する耐性を備えた、拡張版のコスト意識型品質証明(PoQ)メカニズムを提案している。この提案は、主に二つの重要なコンポーネントで構成されている。第一に、合意形成プロセスにおいて、極端なスコアの影響を軽減するための堅牢な集計ルールを導入した。具体的には、サンプルの中央値を用いる手法や、両端の極端な値を除外して平均を算出するトリム平均を採用している。これにより、一部の評価者が極端に高いスコアや低いスコアを報告して合意を操作しようとしても、その影響を限定的に抑えることが可能になる。 第二に、評価者の過去の行動に基づいて影響力を調整する、適応的な信頼重み付けメカニズムを導入した。これは、各評価者が報告したスコアと、ネットワーク全体で形成された合意スコアとの乖離を継続的に監視し、乖離が小さい評価者の重みを維持または増加させ、乖離が繰り返される評価者の重みを減少させる仕組みである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related