ソフトウェア工学におけるLLMの包括的なベンチマーク基盤の構築に向けて
現在のコード用大規模言語モデルの評価は、特定のタスクや単純な正解率指標に偏っており、実世界のソフトウェア開発で不可欠な堅牢性、解釈可能性、公平性、効率性といった多角的な側面を十分に評価できていないという課題があります。
TL;DR(結論)
現在のコード用大規模言語モデルの評価は、特定のタスクや単純な正解率指標に偏っており、実世界のソフトウェア開発で不可欠な堅牢性、解釈可能性、公平性、効率性といった多角的な側面を十分に評価できていないという課題があります。 既存のベンチマークには、ソフトウェア工学特有の文脈の欠如、機械学習中心の指標への過度な依存、そして標準化されていない再現性の低いデータパイプラインという3つの主要な障壁が存在し、深刻なデータ汚染問題も浮き彫りになっています。 これらの課題を解決するため、ソフトウェアのシナリオ定義と多角的な指標評価を統合した包括的なベンチマーク基盤「BEHELM」が提案され、開発ライフサイクル全体をカバーする公平で現実的な評価の実現を目指しています。
なぜこの問題か
コード用大規模言語モデル(LLMc)は、コード補完、要約、コードレビュー支援、バグ修正、テスト生成など、ソフトウェア工学のワークフローを劇的に変化させています。GitHub CopilotやGoogleのCodeBotといったツールの普及により、開発者は日常的なコーディング作業の多くをこれらのモデルに依存するようになっています。しかし、モデルの能力が急速に進化する一方で、その性能を正確に評価する手法の開発が遅れているという深刻な問題があります。現在の評価手法は、主にコードの正解率やテキストの類似度といった指標に集中しています。しかし、これらの指標だけでは、モデルの出力がどれほど解釈可能か、実行効率が良いか、あるいは公平性やバイアスが含まれていないかといった、実務において極めて重要な要素を明らかにすることができません。 既存のベンチマークの多くは、現実のソフトウェア開発で必要とされる複雑な文脈を切り離した、単純化されたタスクに焦点を当てています。例えば、リポジトリの構造、ビルド構成、依存関係の定義、コミット履歴といった、開発者が意思決定を行う際に参照する重要な情報が評価データに含まれていないことが多いのです。…
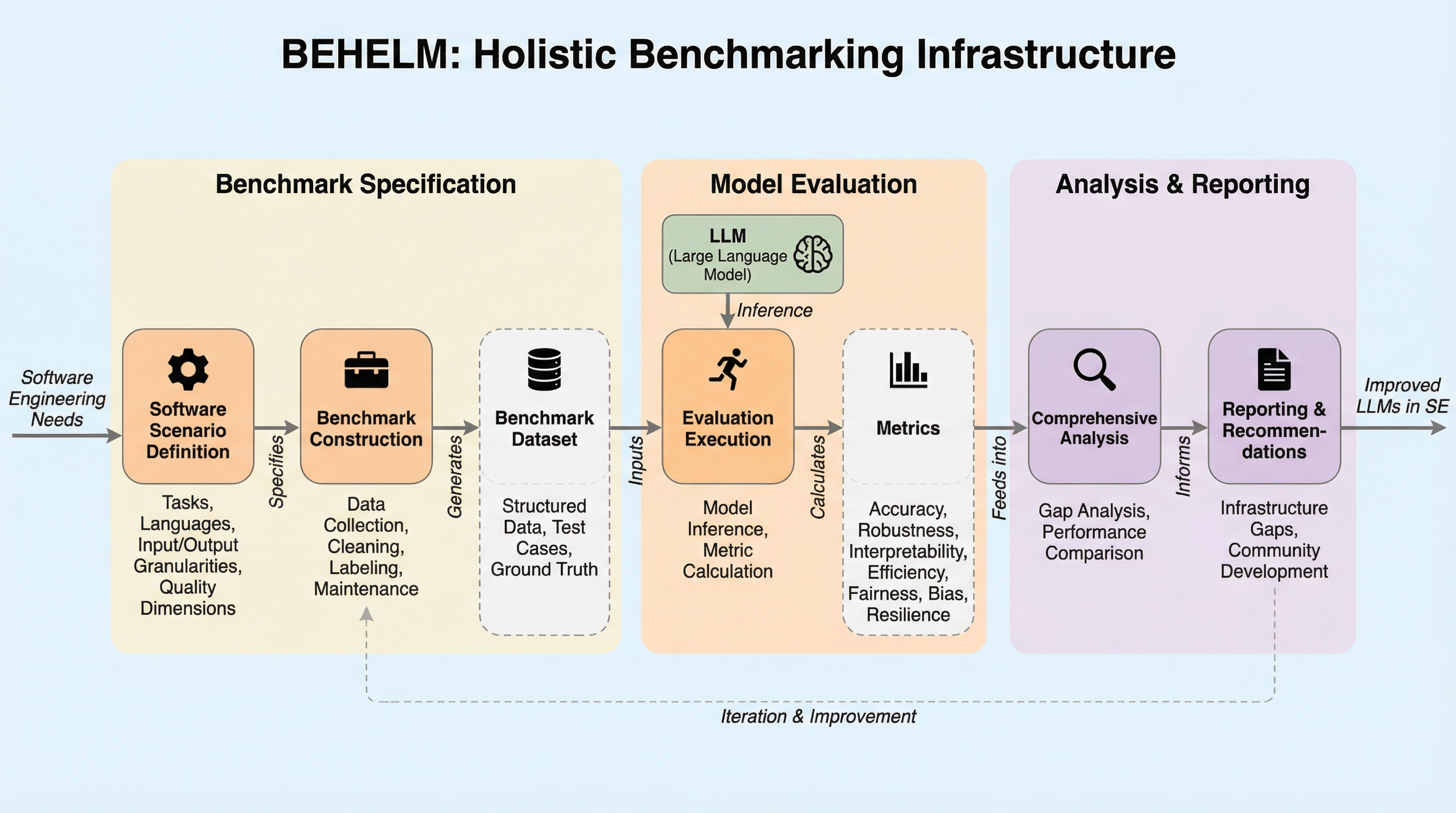
核心:何を提案したのか
本研究の核心は、既存のベンチマークの包括的な調査とコミュニティワークショップでの知見を統合し、大規模言語モデルの評価における主要な欠陥を特定した上で、新たな包括的ベンチマーク基盤「BEHELM」を提案したことにあります。この基盤は、従来の単一的な評価から脱却し、ソフトウェアのシナリオ指定と多角的な指標評価を統合した構造を提供することを目的としています。この提案は、モデルが単に「正しいコードを生成するか」だけでなく、「効率的で、透明性が高く、信頼できるか」を総合的に判断できる環境を構築することを目指しています。 この基盤の重要な側面は、評価を「ソフトウェアシナリオ」と「マルチメトリック(多角的指標)」の2つの軸で整理することにあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related