超線形多段階アテンション
本論文は、標準的な自己注意機構の二次計算量 $O(L^2)$ を打破し、シーケンス長 $L$ に対して $O(L^{1+1/N})$ の劣二次計算量を実現する「スーパーリニア・アテンション」を提案しています。
TL;DR(結論)
本論文は、標準的な自己注意機構の二次計算量 $O(L^2)$ を打破し、シーケンス長 $L$ に対して $O(L^{1+1/N})$ の劣二次計算量を実現する「スーパーリニア・アテンション」を提案しています。 この手法は、特定のトークンを構造的に注意の対象から除外しない「ランダム・コンテキスト・アクセス(構造的非除外性)」を維持しており、全てのトークンが内容に応じて動的に選択される可能性を担保しています。 単一の NVIDIA B200 GPU を用いた検証では、1000万トークンの文脈において毎秒80トークンのデコード・スループットを達成し、25.6万トークンの文脈における情報抽出タスクでも高い学習能力と性能を示しました。
なぜこの問題か
大規模言語モデル(LLM)は、膨大な文書の統合、長期的な対話やエージェントのワークフローにおける一貫性の維持、大規模な検索結果に基づく推論(RAG)、大規模なコードベースの理解など、非常に長い文脈を扱う能力がますます求められています。文脈窓が数万から数百万、あるいはそれ以上に拡大することで、単一のパスで信頼性の高い情報抽出や長期的な推論が可能になりますが、標準的なトランスフォーマーが採用している自己注意機構の計算コストはシーケンス長の二乗 $O(L^2)$ で増大するため、これがスケーラビリティの根本的なボトルネックとなっています。 これまでにも計算量を削減するための様々なアプローチが提案されてきました。初期のスパース・アテンション手法は、注意を向けるトークンの位置を固定的なマスクで制限するため、特定のトークンが構造的にアクセス不能になるという欠点がありました。…
核心:何を提案したのか
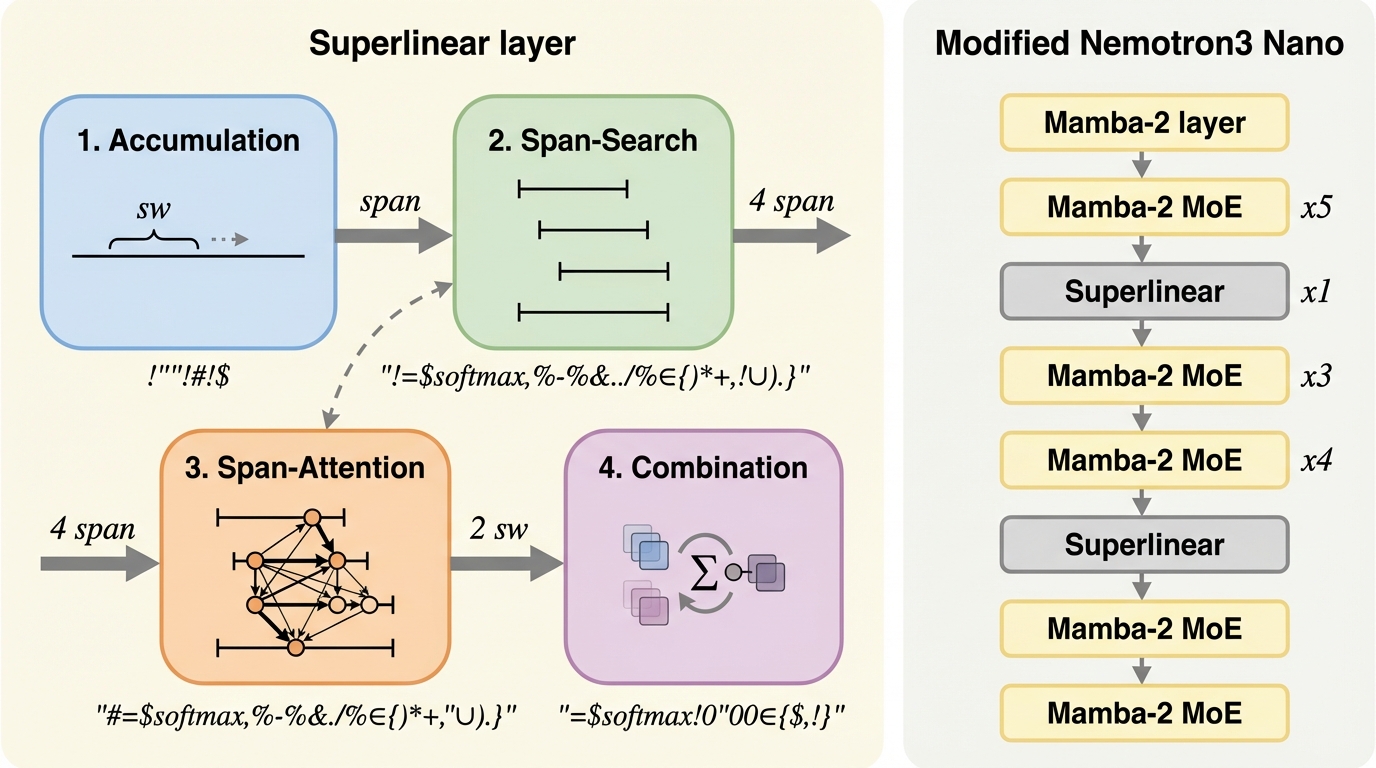
本論文は、標準的な自己注意機構を $N$ ステップの探索問題として再定式化する「スーパーリニア・アテンション(Superlinear attention)」を提案しています。このアーキテクチャは、シーケンス全体に対して $O(L^{1+1/N})$ という全体計算量を実現しながら、どのトークン位置も構造的に注意の対象から排除されない「ランダム・コンテキスト・アクセス」を維持している点が最大の特徴です。これは、内容に依存した動的なルーティングメカニズムを通じて、全てのトークンが注意の候補になり得ることを意味します。 具体例として、アルゴリズム的に「ジャンプ探索(jump search)」に類似した $N=2$ のベースライン実装が示されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related