D最適(D-optimal)統計で高次元シミュレーション代理モデルのテスト時適応を安定化するSATTS
工学シミュレーションを高速化する機械学習代理モデルは、学習時と運用時で条件(形状や構成など)がずれると性能が大きく落ちやすく、特に高次元・非構造・回帰の設定では既存のテスト時適応が不安定になりやすい状況が問題になります。
TL;DR(結論)
- 工学シミュレーションを高速化する機械学習代理モデルは、学習時と運用時で条件(形状や構成など)がずれると性能が大きく落ちやすく、特に高次元・非構造・回帰の設定では既存のテスト時適応が不安定になりやすい状況が問題になります。
- SATTSは、学習時のソース領域から「情報量が最大になるように選んだ」D最適の小さな統計だけを保存しておき、テスト時にはそれを使って潜在特徴の整合、ソース知識の逸脱抑制、ラベルなしでの学習率選択までを一体として安定化します。
- 事前学習済みのシミュレーション代理モデルに適用すると、計算コストの上乗せは小さいまま分布外で最大7%の改善が得られ、SIMSHIFTとEngiBenchで高次元回帰と生成的な設計最適化の両方に対して有効性が検証された、と著者らは述べています。
なぜこの問題か
工学や科学の現場では、偏微分方程式に基づく数値シミュレーションが高価になりやすく、その近似としてニューラルな代理モデルが使われる場面が増えています。ところが代理モデルは、学習に使った条件とテスト時の条件が一致しているときは動きやすい一方で、見たことのない形状や構成が入力として現れると性能が大きく低下しやすいとされています。産業シミュレーションや設計最適化では、反復のたびに設定が広く変動し、あらかじめ想定した範囲を越えた構成が現れやすいため、この分布ずれは実務上の障害になりやすいです。さらに、利用できるのが大規模な事前学習済みモデルだけで、全面的な再学習が高価または非現実的な状況も想定されています。加えて、可搬性や権利上の理由などで元の学習データにアクセスできない場合があり、推論時に追加のラベルを用意せずに適応できる仕組みが求められます。 この要請に対してテスト時適応(TTA)は、ラベルなしのターゲットデータを使って推論時にモデルを調整し、計算負荷を小さくしやすい手段として位置づけられています。ただし従来のTTAは、低次元の分類や、入力と出力が視覚的に対応しやすい領域を主な前提として発展してきました。…
核心:何を提案したのか
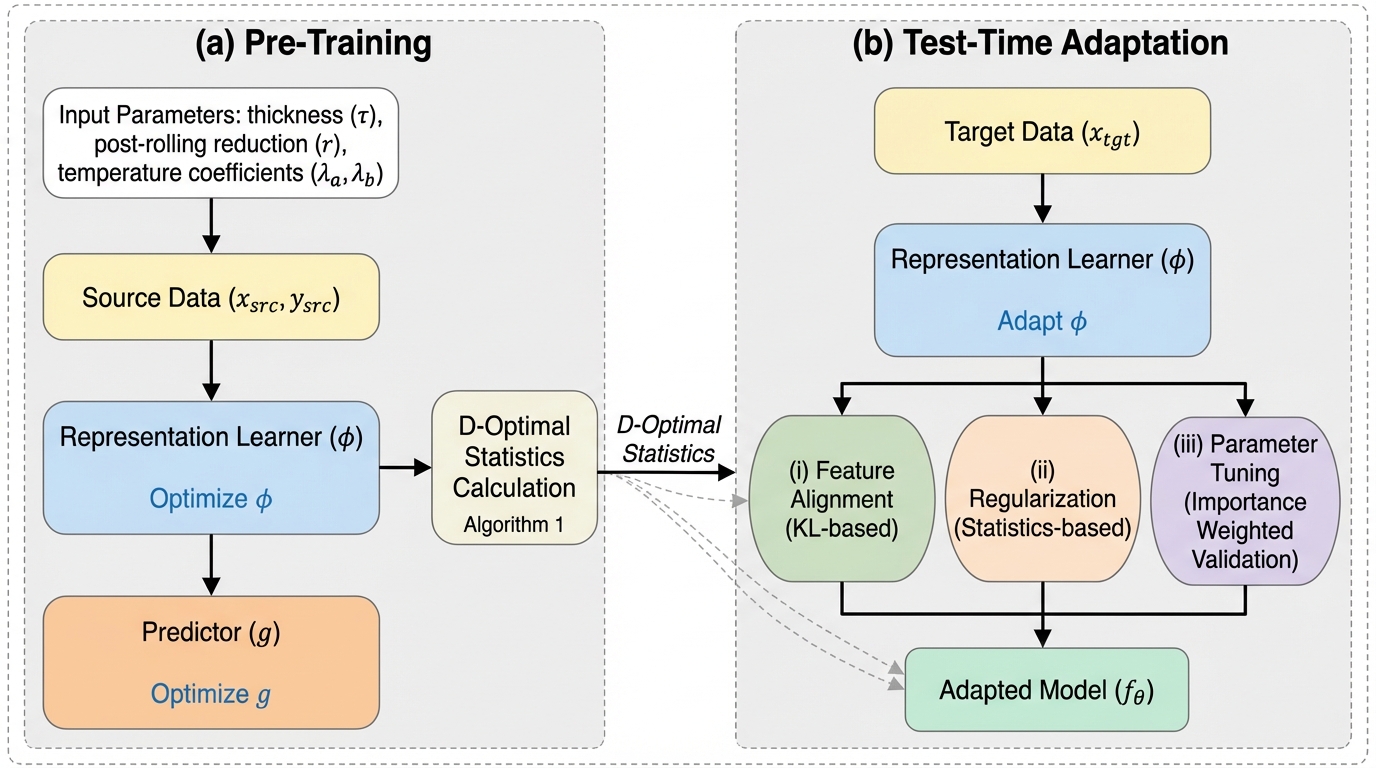
著者らは、高次元シミュレーションの回帰(回帰としての代理モデル)と、設計最適化における生成(逆問題としての生成モデル)という2つのタイプの工学タスクを対象に、テスト時適応を安定化する枠組みSATTS(Stable Adaptation at Test-Time for Simulation)を提案しています。中核の発想は、ソース領域のすべての学習データを保持しなくても、潜在空間で「最大限に情報量が高い」統計だけを小さく保存しておけば、テスト時の適応を成立させつつ不安定性を抑えられる、という点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related