表現のアンラーニング:情報圧縮による忘却
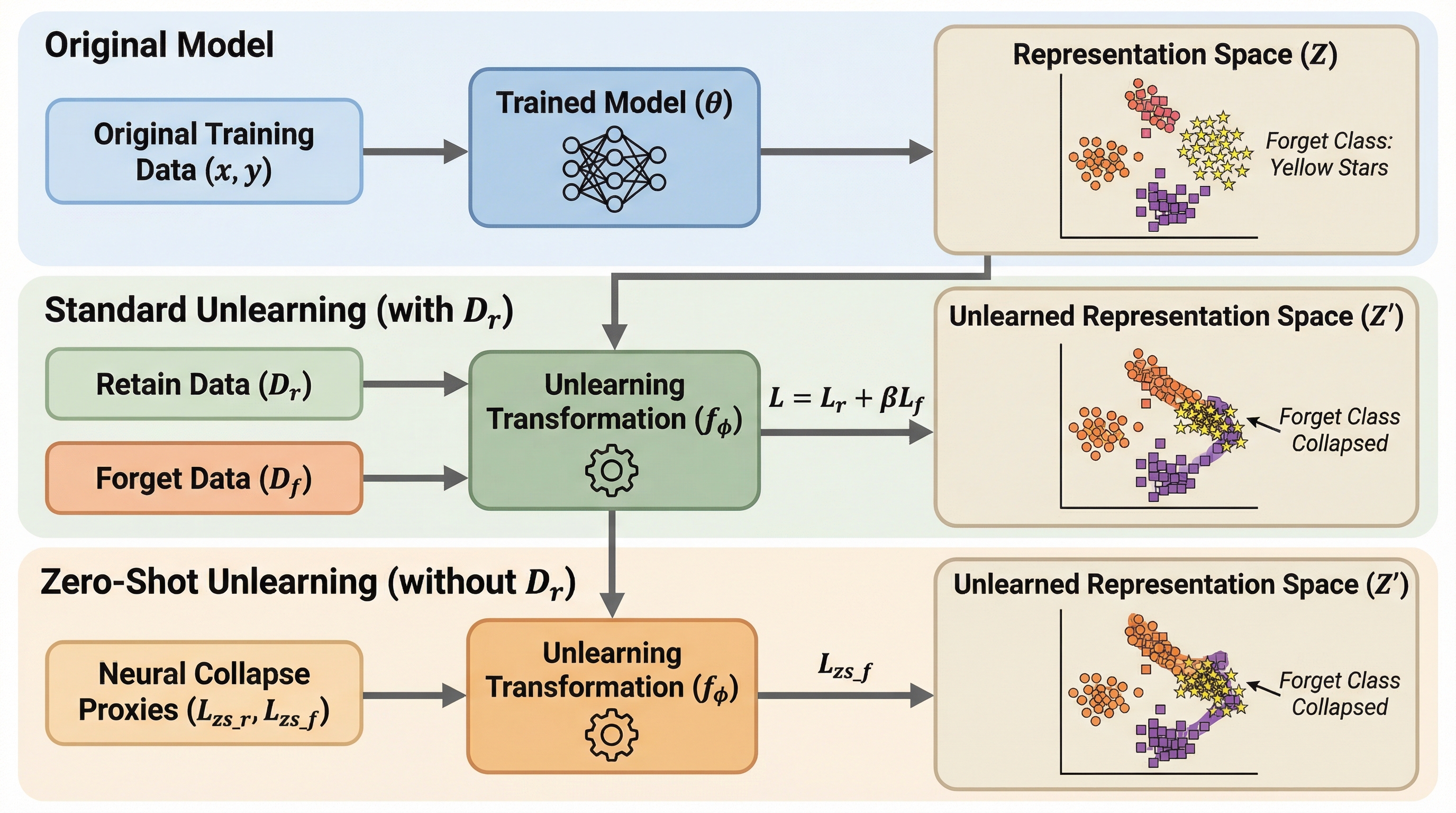
機械学習モデルから特定のデータを忘却させる手法として、モデルのパラメータを直接修正するのではなく、内部の表現空間で情報を変換する「Representation Unlearning」という新しい枠組みが提案されました。
TL;DR(結論)
機械学習モデルから特定のデータを忘却させる手法として、モデルのパラメータを直接修正するのではなく、内部の表現空間で情報を変換する「Representation Unlearning」という新しい枠組みが提案されました。 この手法は情報ボトルネックの原理に基づき、保持したいデータの相互情報量を最大化しつつ忘却対象のデータの情報を抑制する変換を学習するもので、変分近似を用いることで計算効率と安定性を両立しています。 従来のパラメータ中心の手法と比較して、忘却の信頼性が高く、保持データの性能維持に優れ、さらに保持データにアクセスできないゼロショット設定でも効果的に機能することが大規模な実験によって確認されました。
なぜこの問題か
現代の機械学習システムは、膨大なデータセットを用いて訓練されていますが、その中には機密情報や個人情報、あるいは誤ったラベルや毒性のあるデータが含まれている可能性があります。欧州連合のGDPR(一般データ保護規則)やカリフォルニア州消費者プライバシー法(CCPA)などの法規制により、ユーザーが自分のデータをモデルから削除することを求める「忘れられる権利」が法的に保証されるようになりました。しかし、単に元のデータベースからデータを削除するだけでは不十分です。深層学習モデルは訓練データを記憶する性質があるため、モデルのパラメータ内に統計的な痕跡が残ってしまうことが知られています。この影響を完全に取り除くための最も確実な方法は、モデルを最初から再訓練することですが、大規模なモデルでは計算コストが膨大になり、現実的ではありません。 そのため、再訓練を行わずに効率的に特定のデータの影響を消去する「マシンアンラーニング(機械忘却)」の研究が盛んに行われています。しかし、既存の多くの手法はモデルのパラメータを直接変更するアプローチをとっており、これにはいくつかの重大な課題が存在しています。…
核心:何を提案したのか
本論文では、パラメータ空間ではなくモデルの内部表現空間で忘却を実行する「Representation Unlearning(表現忘却)」という革新的なフレームワークを提案しています。このアプローチの最大の特徴は、ネットワークの重みを再最適化する代わりに、元の表現を新しい表現へと写像する変換関数を学習するという点にあります。この変換は情報ボトルネックの概念を導入しており、保持セットのデータに関する相互情報量を維持しながら、忘却セットのデータに関する相互情報量を最小化するように設計されています。表現空間は通常、パラメータ空間よりも次元数が大幅に小さいため、この変換の学習はパラメータレベルのマッピングよりもはるかに単純で扱いやすいものとなります。 具体的には、ニューラルネットワークの最終層に近い部分の活性化(表現)を対象とし、そこに軽量な線形写像または浅い多層パーセプトロンを適用します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related