表現のアンラーニング:情報圧縮による忘却
機械学習モデルから特定の学習データの情報を削除するマシンアンラーニングにおいて、従来のモデルパラメータを直接変更する手法は計算コストや不安定さが大きな課題であったが、本研究ではモデルの内部表現空間で直接忘却を行う表現アンラーニングという新しい枠組みを提案している。
TL;DR(結論)
機械学習モデルから特定の学習データの情報を削除するマシンアンラーニングにおいて、従来のモデルパラメータを直接変更する手法は計算コストや不安定さが大きな課題であったが、本研究ではモデルの内部表現空間で直接忘却を行う表現アンラーニングという新しい枠組みを提案している。 この手法は情報ボトルネックの原理に基づき、保持すべきデータの相互情報を最大化しつつ忘却対象のデータの情報を抑制する変換を学習するもので、変分近似を用いることで計算を可能にし、保持データが利用可能な通常設定と忘却データのみが利用可能なゼロショット設定の両方に対応している。 実験の結果、従来のパラメータ中心の手法と比較して、より信頼性の高い忘却と高い実用性の維持、そして優れた計算効率を達成しており、プライバシー規制やデータの堅牢性に関する懸念に対応するための効率的かつ安定した解決策として機能することが示されている。
なぜこの問題か
現代の機械学習システムは膨大なデータセットで訓練されているが、そこには機密情報や個人情報、あるいは問題のある情報が含まれることが少なくない。欧州のGDPRやカリフォルニア州のCCPAといった法規制により、ユーザーが自身のデータの削除を求める「忘れられる権利」が確立されたことで、モデルから特定の学習サンプルの影響を取り除く必要性が高まっている。また、誤ったラベルが付与されたサンプルや、悪意を持って注入された毒性データ、あるいは同意を撤回したユーザーのデータを除去するといった実用的な要件も存在する。単に元のデータベースからデータを削除するだけでは不十分であり、深層学習モデルは学習データを記憶する性質があるため、モデルのパラメータ内に統計的な痕跡が残ってしまうことが知られている。 この課題を解決するために「マシンアンラーニング」の研究が進められているが、理想的な解決策である「対象データを除いて一から再学習する」という手法は、大規模なモデルやデータセットにおいては計算コストが膨大になりすぎて現実的ではない。そのため、再学習の効果を近似する効率的な代替手法が求められている。…
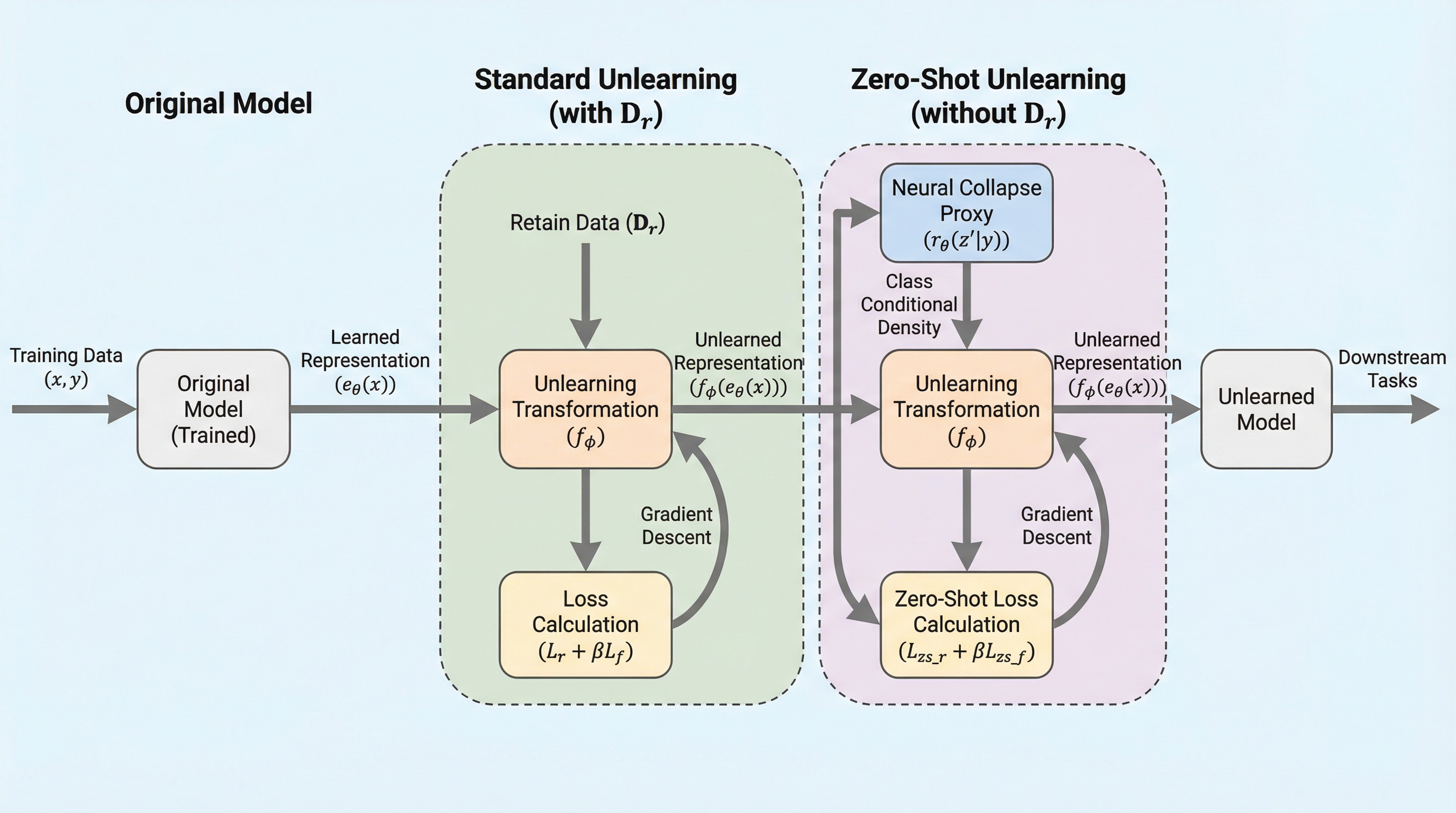
核心:何を提案したのか
本研究では、従来のパラメータ中心の手法とは一線を画し、モデルの内部表現空間で直接操作を行う「表現アンラーニング」というフレームワークを提案している。ネットワークのパラメータそのものを変更したり再最適化したりするのではなく、特定のサンプルがより局所的に制御しやすい形で現れる内部表現を対象とする。具体的には、元の表現を新しい表現へと写像する変換関数を学習し、そこに情報ボトルネックの制約を課す。この制約の目的は、保持セットに含まれるデータとの相互情報を最大化しつつ、忘却セットに含まれるデータとの相互情報を抑制することにある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related