ReLE: 中国語LLMにおける能力異方性を診断するためのスケーラブルなシステムと構造化ベンチマーク
ReLEは、中国語大規模言語モデル(LLM)の評価において、既存ベンチマークの飽和と膨大な計算コストという課題を解決するために開発された、スケーラブルな動的診断システムである。304個のモデルを対象に20万件以上のサンプルを用いた評価を行い、分散認識型スケジューラにより精度を維持しながらコストを70%削減し、記号接地ハイブリッドスコアリングで判定の信頼性を高めた。モデルの性能が領域ごとに不均一である「能力異方性」を定量化し、単一の集計スコアでは隠されてしまうランキングの不安定性や、専門性と汎用性の間にある構造的なトレードオフを明らかにした。
TL;DR(結論)
ReLEは、中国語大規模言語モデル(LLM)の評価において、既存ベンチマークの飽和と膨大な計算コストという課題を解決するために開発された、スケーラブルな動的診断システムである。304個のモデルを対象に20万件以上のサンプルを用いた評価を行い、分散認識型スケジューラにより精度を維持しながらコストを70%削減し、記号接地ハイブリッドスコアリングで判定の信頼性を高めた。モデルの性能が領域ごとに不均一である「能力異方性」を定量化し、単一の集計スコアでは隠されてしまうランキングの不安定性や、専門性と汎用性の間にある構造的なトレードオフを明らかにした。
なぜこの問題か
大規模言語モデル(LLM)の急速な進歩により、中国語の理解能力は飛躍的に向上したが、それに伴い既存のベンチマークが天井に達する「ベンチマークの飽和」が深刻な問題となっている。CLUEやC-Eval、AGIEvalといった従来のデータセットでは、最新モデルのスコアが上限付近で密集し、モデル間の真の能力差を識別することが困難になっている。また、従来のリーダーボードは静的なスナップショットに過ぎず、モデルが持つ能力の構造的なトレードオフを覆い隠してしまう傾向がある。現在の評価フレームワークの多くは、能力を単一の数値(スカラー値)に集約しているが、これは「一般知能(g-factor)」という単一の要因を前提としたものであり、実際のモデルが示す多面的な特性を反映できていない。 さらに、評価にかかる膨大なコストも大きな障壁となっている。300以上のモデルを従来の固定サンプル戦略で評価する場合、商用APIや計算リソースの費用は69,000ドルを超え、モデルごとに1時間以上の適応作業が必要になるという調査結果がある。このような高コストな構造は、モデルの更新頻度が高い現代において持続可能な評価を妨げている。…
核心:何を提案したのか
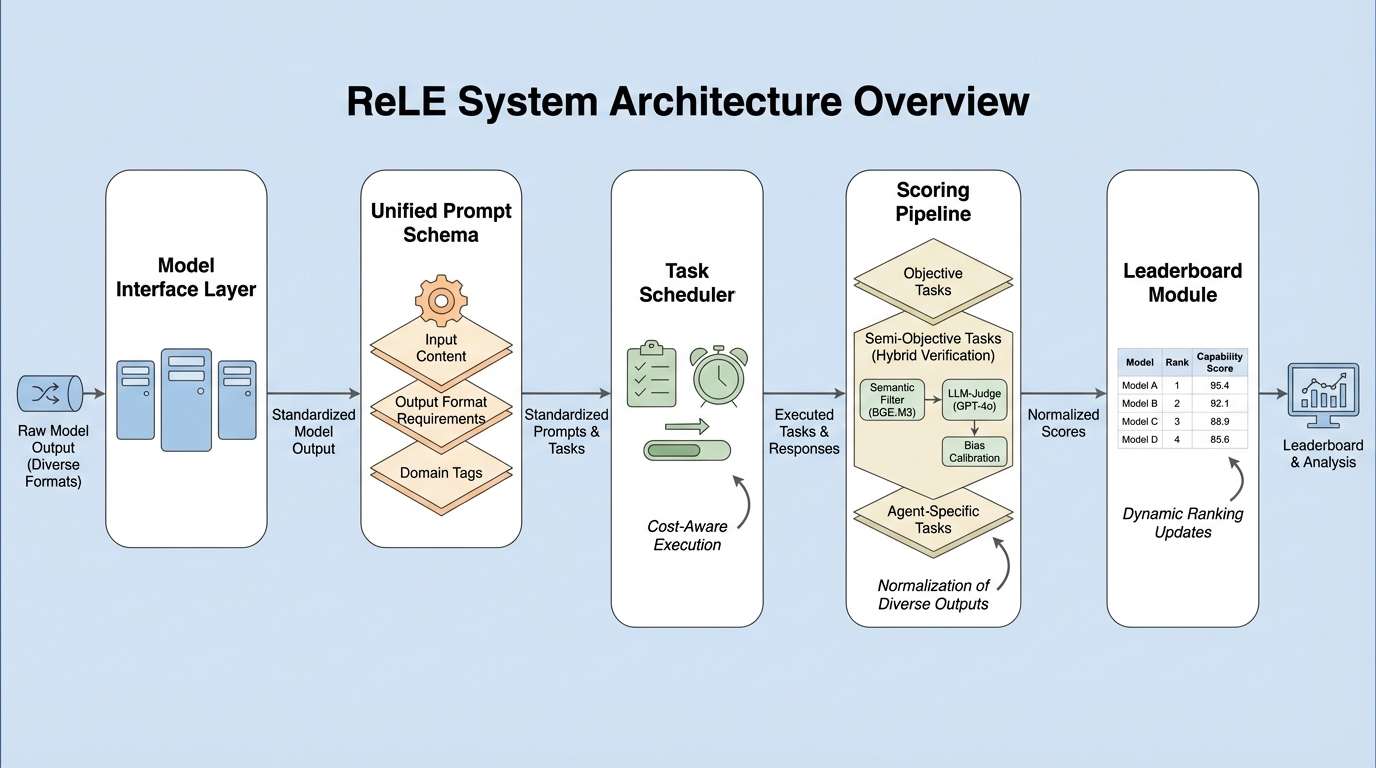
本研究では、モデルの領域ごとの性能の不均一性である「能力異方性(Capability Anisotropy)」を診断するためのシステム「ReLE(Robust Efficient Live Evaluation)」を提案している。ReLEは、コスト効率の高い診断評価を実現するために、システム統合と大規模な実証分析のレベルで3つの主要な貢献を行っている。第一に、統計的な分散減少サンプリング戦略を導入することで、従来のフルセット評価と比較して計算コストを70%削減(69,000ドルから20,700ドルへ)し、304個のモデルという大規模な評価を可能にした。第二に、7つのコア領域、22の主要次元、317のサブタスクからなる階層的な能力分解フレームワークを構築し、最新のデータを含む207,843件のサンプルを提供している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related